这篇教程Keras实现vgg源代码写得很实用,希望能帮到您。
vgg16先卷积2次,池化,卷积2次,池化,卷积3次,池化,卷积3次,池化,然后全连接层。
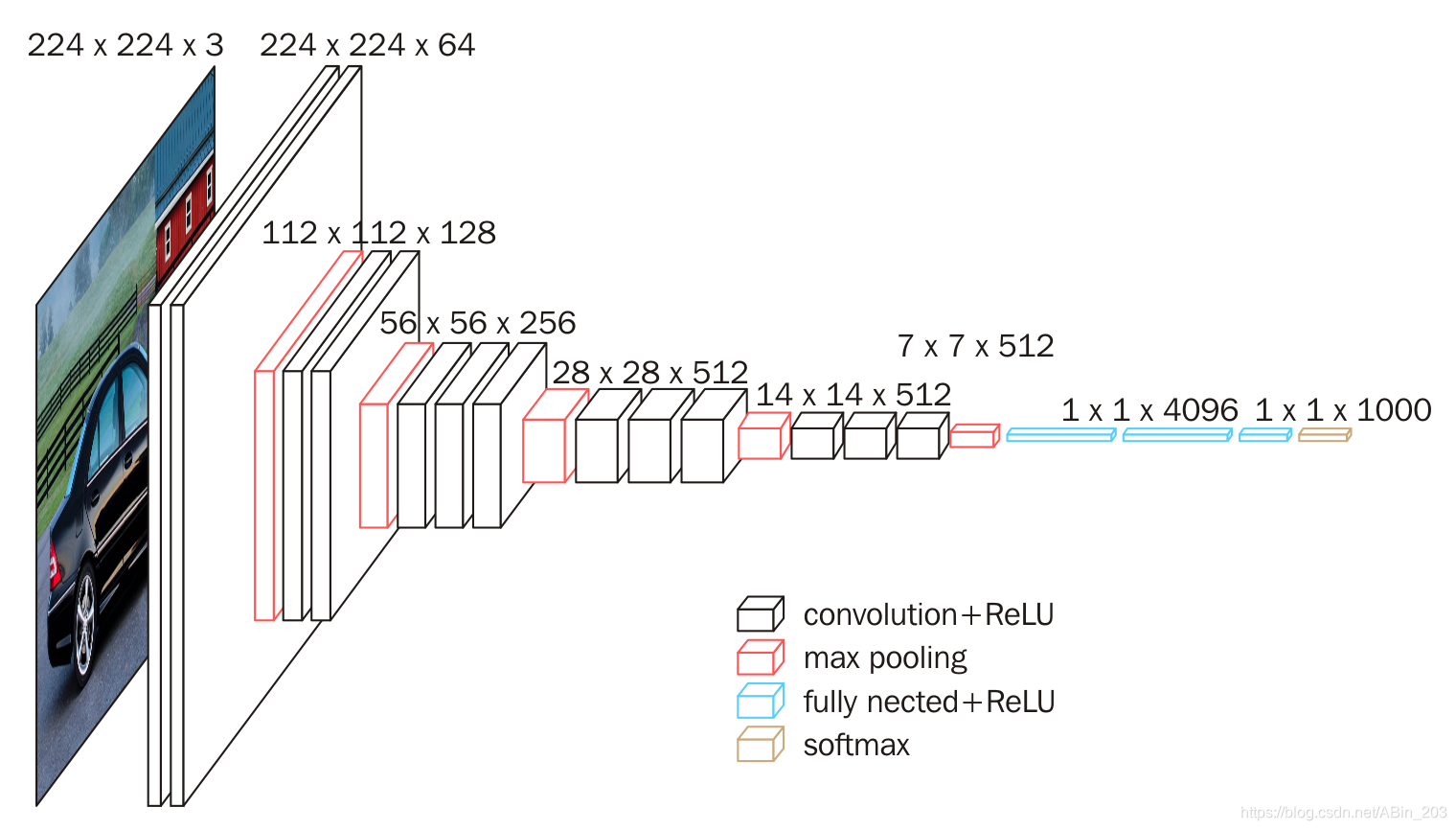 看看大概结构其实很容易发现规律,似乎有些代码都是重复的,然后有些只是改个数字而已。具体怎么写,下面进行详细介绍。小伙伴们要特别注意代码中一些数字和上图结构中数字的关系噢,特别是64,128,256,512,4096,1000.很有规律的。仔细观察你就会了
看看大概结构其实很容易发现规律,似乎有些代码都是重复的,然后有些只是改个数字而已。具体怎么写,下面进行详细介绍。小伙伴们要特别注意代码中一些数字和上图结构中数字的关系噢,特别是64,128,256,512,4096,1000.很有规律的。仔细观察你就会了
from keras.models import Sequential
from keras.layers.core import Flatten, Dense
from keras.layers.convolutional import Conv2D, MaxPooling2D
model = Sequential()
model.add(Conv2D(64, (3, 3), padding = 'same', activation='relu', input_shape=(224, 224, 3)))
model.add(Conv2D(64, (3, 3), padding = 'same', activation='relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Conv2D(128, (3, 3), padding = 'same', activation='relu'))
model.add(Conv2D(128, (3, 3), padding = 'same', activation='relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Conv2D(256, (3, 3), padding = 'same', activation='relu'))
model.add(Conv2D(256, (3, 3), padding = 'same', activation='relu'))
model.add(Conv2D(256, (3, 3), padding = 'same', activation='relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Conv2D(512, (3, 3), padding = 'same', activation='relu'))
model.add(Conv2D(512, (3, 3), padding = 'same', activation='relu'))
model.add(Conv2D(512, (3, 3), padding = 'same', activation='relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Conv2D(512, (3, 3), padding = 'same', activation='relu'))
model.add(Conv2D(512, (3, 3), padding = 'same', activation='relu'))
model.add(Conv2D(512, (3, 3), padding = 'same', activation='relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dense(4096, activation='relu'))
model.add(Dense(1000, activation='softmax'))
model.summary()
Sequential
sequential就是实例化模型,创建一个 Sequential模型,可以通过 .add()的方法将各层添加到网络中。
Conv2D
keras.layers.Conv2D(filters,
kernel_size,
strides=(1, 1),
padding=‘valid’,
data_format=None,
dilation_rate=(1, 1),
activation=None,
use_bias=True,
kernel_initializer=‘glorot_uniform’,
bias_initializer=‘zeros’,
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None)
该层创建了一个卷积核, 该卷积核对层输入进行卷积, 以生成输出张量。 如果 use_bias 为 True, 则会创建一个偏置向量并将其添加到输出中。 最后,如果 activation 不是 None,它也会应用于输出。
当使用该层作为模型第一层时,需要提供 input_shape 参数。比如训练样本是(6000,28,28,1), 则input_shape=(28,28,1)
介绍一些常用的参数设置:
filters: 整数,输出空间的维度 (即卷积中滤波器的数量)。
kernel_size: 一个整数,或者 2 个整数表示的元组或列表, 指明 2D 卷积窗口的宽度和高度。 可以是一个整数,为所有空间维度指定相同的值。
strides: 一个整数,或者 2 个整数表示的元组或列表, 指明卷积沿宽度和高度方向的步长。 可以是一个整数,为所有空间维度指定相同的值。 指定任何 stride 值 != 1 与指定 dilation_rate 值 != 1 两者不兼容。
padding: “valid” 或 “same” (大小写敏感)。 valid padding就是不padding,而same padding就是指padding完尺寸与原来相同
图像识别一般来说都要padding,尤其是在图片边缘的特征重要的情况下。padding多少取决于我们需要的输出是多少
MaxPooling2D
keras.layers.MaxPooling1D(pool_size=2,
strides=None,
padding=‘valid’,
data_format=‘channels_last’)
介绍一些常用的参数设置:
该层是池化层,pool_size是最大池化的窗口大小。vgg16网络很有特点,池化的size都是2,strides步长也都是2.
padding: “valid” 或 “same” (大小写敏感)。 valid padding就是不padding,而same padding就是指padding完尺寸与原来相同。
Flatten
这个其实很简单了,功能呢就是相当于过渡一样。举个例子。前面是卷积池化,后面是全连接层,flatten意思是在这两边搭个桥,过渡过渡,把前面得到的数组展开得以输入后面连接层。
Dense
顾名思义就是层的意思,这个呢是专门来做全连接层的。
keras.layers.Dense(units,
activation=None,
use_bias=True,
kernel_initializer=‘glorot_uniform’,
bias_initializer=‘zeros’,
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None)
介绍一些常用的参数设置:
unit就是神经元了,vgg模型的全连接层第一层和第二层都是4096个单元,那这里units就是4096,激活函数activation为relu。
训练
构建完网络当然就是接着训练咯。不过在训练之前,要强调一下,注意上面代码中首层卷积层输入的维度224,224,3.这个维度是要和你的数据维度相同才能输入进网络。那么你的训练数据肯定不止一个数据,因此你的X_train的shape应该是x,224,224,3.
网络的训练还是比较简单。
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10)
训练之前进行的一些配置。adam是优化器。同样的还有其他的,loss就是选择的损失函数啦,对于多分类选择这个损失函数就是为了多分类任务的,然后选择评价指标是准确率。至于其他的参数以及更多参数的选择,大家可以到官网上查看。
fit里面X_train, y_train要保证维度相同。epochs表示迭代的次数。可以多一点,几十几百都没问题,只要你电脑给力。
预测
如果想要预测也很简单。
model.predict_classes(X_test)注意这里的X_test同样的图片维度也应该是224,224,3.也就是说如果你有多个图片的话,shape应该是x,224,224,3.
看到这,相信你可以自己搭建网络进行识别图像了。快去试试吧!
(其实博主是坑你的,一般的电脑一下子fit全部数据就会爆内存,参数太多了,但是vgg16真的好用,小伙伴们可以尝试删减层数,降低模型复杂度,或者参考博主第二篇博客来进行vgg16的实战以及网络如何优化来实现vgg噢。)
使用 Keras + CNN 识别 CIFAR-10 照片图像
用keras搭建的vgg16网络 |