这篇帖子是希望让大家对momentum有一个直观的认识,所以我会尽量用更直观的角度来解释。想更严格深入的理解其中的理论结果,请阅读我提供的参考文献。为了表述简单,我这里只考虑最简单的Polyak‘s momentum,又名Heavy Ball。Nesterov‘s momentum形式稍微复杂一些,不过作用十分类似这,这里就不多赘述了。
下面我们来看具体看一下,目标是解一个d维实数空间的优化问题:
这里 是一个二阶可导的函数。
这个帖子会分上下两部分。上部分,我先解释momentum在凸问题和batch gradient method组合的效果。下部分,我会解释在非凸问题上和stochastic gradient method组合的效果。
那么接下来,我要解释的算法就是众所周知的Momentum Gradient Method (MGM):
这里 是步长,
就是Polyak's momentum,而
是momentum parameter。当
的时候,MGM变为Vanilla Gradient Method (VGM)。
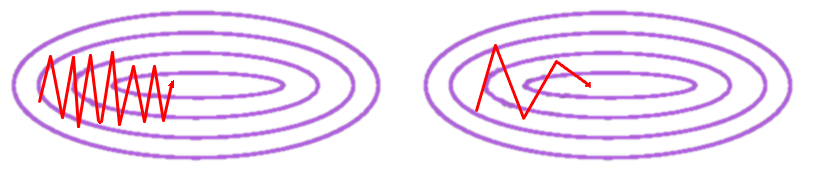
经常看到有人解释momentum是如何加速的,而且经常会用到下面这张图。
然后他们接下来会说,解凸优化问题的时候,没有momentum,VGM会向左边这张图一样跳动,而用了momentum的MGM会像右边这张图一样更稳定的接近最优解,理由一般是说momentum是moving average或者其他类似的理由。但其实这个解释是错误的。
我们先来看看实际是什么样子的。我们选一个最简单的二次函数。
这个问题的最优解是 ,强凸(
),符合Lipschitz continuous gradient (
)的条件。步长我们选
,momentum parameter我们选
。这里是非常标准的参数选择,我就不赘述了。不明白为什么选这些参数的话可以参见Vandenberghe的EE236C的课件(点击这里)。初始解我们选择
。迭代公式为
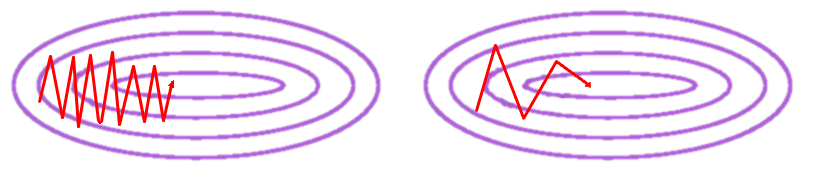
结果如何呢?

猜一猜哪个是VGM,哪一个是MGM。答案揭晓:红色的是MGM。
其实得到这种结果并不意外,这个问题的等高线都是离心率非常大的椭圆,初始解的gradient方向和指向最优解的方向其实是相差很大的,所以第一个iteration主要是沿着 方向来减小,所以从图里,我们可以看到
快速的减小到0,然后沿着
方向再缓慢下降。其实整个函数沿着
方向很平,本可以用更大的步长(
),但这里为保证收算法全局收敛性,对于固定步长,我们需要选择
。很多人会说,那很好办,只要动态选择步长就可以了。而这里要注意,对于backtracking之类的line search方法,步长只会随着迭代越来越小。所以这里说的动态步长需要允许在迭代中增大步长。不过这属于另一个范畴的问题了,我们还是回来讨论本篇的主题momentum。
可以看出,比起普通的gradient method,加了momentum之后,算法的稳定性其实是变差了。出现了一些震荡,算法也不再保证目标函数单调下降。但好处是每一次迭代,都会更接近最优解。从数值的角度来说,momentum的确是一种插值,但是并不是内插值,而是外插值。所以momentum并不是某种加权平均(weighted average),加权平均是会增加稳定性的,但是这种外插值其实是破坏了稳定性。
其实momentum的中文就是高中物理学到的动量。之所以被称作动量,是因为使用momentum的初衷,就是模拟有质量的粒子在有阻尼的场里运动轨迹 。空间内的反梯度方向就是场的作用力方向,粒子会从能量高的位置(初始解)向能量低的位置(最优解)移动,momentum parameter决定阻尼系数。因为粒子有质量,所以具有惯性,而惯性的定性定义是为物体抵抗“动量”改变的性质。换句话说,粒子具有保持静止状态或匀速直线运动状态的性质,所以粒子的运动的瞬时方向,会是力的作用方向和轨迹切线方向的一个组合。
这个物理解释可以用于理解MGM的加速效果,粒子从起点到距离终点 距离的时间可以解释为算法的迭代复杂度(iteration complexity)。如果阻尼小,会使得粒子产生很高的移动速度,但过大的动量会使得粒子震荡,并非保持向终点移动。而当阻尼过大,又会导致粒子移动过于缓慢的话,会花很久时间接近终点,同时震荡会减小。那么如何选择最优的设置阻尼,这就是已有的大量文献里提供的参数选择了。
更详细的描述可以看一下两篇文章:
【1】Su et al. A Differential Equation for Modeling Nesterov's Accelerated Gradient Method: Theory and Insights. 2015
【2】Yang et al. The Physical Systems Behind Optimization Algorithms. 2016
知道了这个简单的物理解释,其实就可以理解为什么momentum会被称作overshoot了。因为vanilla gradient method其实对应0质量粒子,所以粒子不具备惯性,会始终按作用力方向运动(加速度无穷大)。
但对于随机优化问题,比如使用momentum和stochastic gradient method的组合,这种加速效果就不复存在了。相反使用momentum会使收敛变慢。但为什么大家还是这么热衷使用momentum呢?具体原因,我会在下半部分里解释。