这一节我们参照官方教程提供的代码,研究如何制作自己的数据集并送入深度学习模型中训练。我们可以看到,前几节的内容很多是基于现成的数据集,直接导入使用即可。但在实际应用中,这显然是不可行的。对于Tensorflow2.0,主要有两种自定义制作我们自己数据集的方式:一种是直接由tensorflow自身提供的函数来进行制作,而另一种则是调用tensorflow的高级API Keras的函数来制作,这两种方式都是可行的。但是建议大家还是使用官方提供的tf.dataset方式,但在这里二者都会进行介绍。那么这一节会先讲如何用tensorflow自身提供的方式来自定义数据集,下一节则会讨论另一种方式。
这一节我们将要对一些花的数据集来进行处理,这个数据集在网上可以通过远程链接进行下载。但是由于该数据集没有分好训练集和测试集的部分,因此在本节代码中我们不对模型进行测试,当然这也并不是我们这一节的重点,大家只要注重数据集制作的部分即可。
这里附上官方代码的链接:https://tensorflow.google.cn/tutorials/load_data/images
一.自定义数据集的读取
1.导入相关库。
-
from __future__ import absolute_import,division,print_function,unicode_literals -
import tensorflow as tf -
import pathlib #读图片路径 -
import random -
import IPython.display as display #显示图片 -
import os -
import matplotlib.pyplot as plt
2.这行的代码主要是跟图像数据后台的缓存处理有关。
AUTOTUNE = tf.data.experimental.AUTOTUNE
3.下载数据集。fname的意思为下载后文件的命名,而untar=True的意思为对下载完后的文件压缩包直接进行解压。
data_root_orig = tf.keras.utils.get_file(origin='https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',fname='flower_photos',untar=True)
4.得到下载文件的目录。
-
data_root = pathlib.Path(data_root_orig) -
data_root
![]()
5.用iterdir()查看该文件夹下的文件情况。
-
for item in data_root.iterdir(): -
print(item)

6.用glob获取所有文件并存入列表中。这里*的意思为获取所有文件,因此*/*的意思则为获取文件夹下的所有文件及它们的子文件。
-
all_images_paths = list(data_root.glob('*/*')) #获取所有文件路径 -
all_images_paths[-5:] #显示后5个数据
7.将所有文件路径存入列表并打乱顺序。
-
all_images_paths = [str(path) for path in all_images_paths] #将文件路径传入列表 -
random.shuffle(all_images_paths) #打乱文件路径顺序 -
image_count = len(all_images_paths) #查看文件数量 -
image_count
![]()
8.随机选择3张图片进行显示。random_choice的意思为随机选择。
-
for n in range(3): -
image_path = random.choice(all_images_paths) #随机选择 -
display.display(display.Image(image_path)) #图片显示

9.获取不同花朵图片标签的名字。这里*/获得的是当前目录的文件路径,item.name函数可自动从路径中筛选出需要的图片名。
-
label_names = sorted(item.name for item in data_root.glob('*/') if item.is_dir()) -
label_names
![]()
10.因为在训练时参数必须为数字,因此我们需要将标签转为数字表示。这里的enumerate属于python的语法,即是为其建立一个索引序列并配上下标。
-
label_to_index = dict((name,index)for index,name in enumerate(label_names)) #转数字 -
label_to_index
![]()
11.查看所有图片路径文件的类别。因为图片路径的上一级目录名字就是代表的它的类别,因此我们可以用parent.name直接得到。
-
for path in all_images_paths: -
print(pathlib.Path(path).parent.name) #上级路径

12.存储图片的数字标签到列表中。
-
all_images_labels = [label_to_index[pathlib.Path(path).parent.name] for path in all_images_paths] -
print(all_images_labels[:10]) #显示前10个图片标签
![]()
二.自定义数据集的预处理
1.定义图片预处理函数和图片读入函数,第一个decode_jpeg为将读入图片的参数映射为图片,然后将图片大小统一并归一化。
-
def preprocess_img(image): -
image = tf.image.decode_jpeg(image,channels=3) #映射为图片 -
image = tf.image.resize(image,[192,192]) #修改大小 -
image /= 255.0 #归一化 -
return image -
-
def load_and_preprocess_image(path): -
image = tf.io.read_file(path) #这里注意的是这里读到的是许多图片参数 -
return preprocess_img(image)
2.显示其中一张图片。
-
image_path = all_images_paths[0] -
label = all_images_labels[0] -
plt.imshow(load_and_preprocess_image(image_path)) -
plt.grid(False) -
plt.title(label_names[label].title())

3.构建一个tf.dataset,将图片数据传入其中。最简单的方法就是使用from_tensor_slices方法。将图片路径字符串数组切片,得到一个字符串数据集。然后将我们刚才定义的图片读取和预处理函数传入map函数中,即通过在路径数据集上映射preprocess_image来动态加载和格式化图片。
-
path_ds = tf.data.Dataset.from_tensor_slices(all_images_paths) #路径字符串集合 -
image_ds = path_ds.map(load_and_preprocess_image, num_parallel_calls=AUTOTUNE) #通过路径加载图片数据集
到了这一步我们就把我们的所有图片数据集加载到tf.dataset中了。
4.将标签数据也传入其中。cast的意思即是将什么数据转为什么类型,这里我们将其转为整型int64。
label_ds = tf.data.Dataset.from_tensor_slices(tf.cast(all_images_labels,tf.int64)) #读入标签
5.将图片数据和标签打包组合在一起。
image_label_ds = tf.data.Dataset.zip((image_ds,label_ds)) #图片和标签整合
6.我们还可以通过一些函数对图片集进行打乱、重复、分批操作。
-
Batch_size = 32 -
ds = image_label_ds.shuffle(buffer_size=image_count) #打乱数据 -
ds = ds.repeat() #数据重复 -
ds = ds.batch(Batch_size) #分割batch -
ds = ds.prefetch(buffer_size=AUTOTUNE) #使数据集在后台取得 batch
到了这一步我们的图片标签都已经制作好了,下一步进行模型搭建训练。
三.模型搭建
1.这里我们将使用一个的名为MobileNetV2模型作为backbone进行训练。192为我们刚才修改后图片的尺寸,include_top意为是否保留顶层的全连接层,这里我们选择False,因为我们只需要它的特征输出部分。之后我们将这个模型设置为还未训练的形式。
-
mobile_net = tf.keras.applications.MobileNetV2(input_shape=(192,192,3),include_top=False) -
mobile_net.trainable=False
2.整体模型搭建。
-
model = tf.keras.Sequential([ -
mobile_net, -
tf.keras.layers.GlobalAveragePooling2D(), #平均池化 -
tf.keras.layers.Dense(len(label_names),activation='softmax') #分类 -
])
3.模型参数设置。
-
model.compile(optimizer=tf.keras.optimizers.Adam(), -
loss='sparse_categorical_crossentropy', -
metrics=["accuracy"])
4.打印模型概要。
model.summary()

5.查看模型需要训练完所有图片的次数是多少,我们将图片数量/batch_size即可得到。这里要注意的是epochs和step_per_epoch的区别,前者是整体全部图片训练的次数,后者则是要训练完一次epoch所需要的step。
-
steps_per_epoch=tf.math.ceil(len(all_images_paths)/Batch_size).numpy() -
steps_per_epoch
![]()
我们发现要训练115个step所有的batch才能训练完。为了节约时间,我们这里只选择step=3。
model.fit(ds, epochs=1, steps_per_epoch=3,verbose=2)
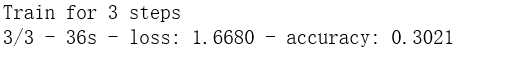
以上就是本节的内容,下次内容会讲述另一种制作数据集的方式。谢谢大家的观看和支持!