这篇教程Algorithms for Hyper-Parameter Optimization写得很实用,希望能帮到您。
Algorithms for Hyper-Parameter Optimization
原文:http://papers.nips.cc/paper/4443-algorithms-for-hyper-parameter-optimization.pdf
作者:
- James Bergstra
哈佛大学罗兰研究所
- R´emi Bardenet
南巴黎大学计算机科学研究实验室
- Yoshua Bengio
蒙特利尔大学计算机科学与运筹学系
- Bal´azs K´egl
南巴黎大学直线加速器实验室
专有名词:
- DBN
Deep Belief Network,深度置信网络。
详见:大话深度信念网络(DBN) https://my.oschina.net/u/876354/blog/1626639
- SMBO
Sequential Model-Based Global Optimization,基于顺序模型的全局优化。
- EI
Expected Improvement,预期改进。
- GP
Gaussian Process,高斯过程。
- EDA
Estimation of Distribution Algorithms,分布估计算法。
- CMA-ES
Covariance Matrix Adaptation - Evolution Strategy,协方差矩阵适应进化策略。
- TPE
Tree-structured Parzen Estimator Approach,树状结构Parzen估计方法(TPE)
- PCA
Principal Component Analysis,主成分分析方法
摘要
图像分类基准的现有技术的若干最新进展来自于现有技术的更好配置而不是特征学习的新方法。一般来说,超参数优化的工作一直由人工完成,因为它们在只有少数试验的环境中非常有效。目前,计算机集群和GPU处理器可以运行更多的试验,我们发现算法方法可以找到更好的结果。我们在训练神经网络和深度置信网络(DBN)的任务中提出超参数优化结果。我们使用随机搜索和基于预期改进标准的两种新的贪婪顺序方法来优化超参数。随机搜索对于学习某些数据集的神经网络已足够有效,但是我们发现它对于训练深度置信网络是不可靠的。顺序算法应用于[1]中最困难的深度置信网络学习问题,并且发现比先前报道的最佳结果明显更好的结果。该工作提供了用于制作响应面模型 P ( y ∣ x ) P(y|x) P(y∣x)的新技术,其中许多超参数分配 ( x ) (x) (x)的元素与其他元素给定的特定值是不相关的。
1 介绍
诸如深度置信网络(DBN)[2],多层降噪自动编码机[3],卷积网络[4]以及基于复杂特征提取技术的分类器等模型具有10个到大约50个超参数,具体取决于实验者如何选择来对模型进行参数化,以及实验者在合理的默认值下选择多少超参数。调整这些模型的难度使得公布的结果难以复现和扩展,甚至使这些方法的原始研究更像是一门艺术,而不是一门科学。
最近的结果如[5],[6]和[7]表明,大型和多层模型中的超参数优化直接阻碍了科学进步。这些工作通过简单算法中的更协调的超参数优化而不是通过创新建模或机器学习策略,在图像分类问题上具有先进的性能。从如[5]的结果中得出特征学习是无用的结论显然是错误的。相反,超参数优化应该被视为学习过程中有条理的外层循环。学习算法,像a functional from data to classifier(以分类问题为例),包括预算选择在超参数探索上花费多少CPU周期,以及花费多少CPU周期来评估每个超参数选择(即通过调整常规参数)。[5]和[7]的结果表明,对于诸如大型计算机集群和GPU的当代硬件,CPU周期的最佳分配包括比机器学习文献典型来得更多的超参数探索。
超参数优化是在图结构配置空间上优化损失函数的问题。在这项工作中,我们将自己限定在树状结构配置空间。树状结构的配置空间意义在于一些叶变量(例如DBN第二层中隐藏层的数量)只有在节点变量(例如离散选择了多少层)取特定值时才能很好地定义值。超参数优化算法不仅必须优化离散、有序和连续的变量,而且必须同时选择变量哪一个变量来优化。
在该工作中,我们通过一种生成过程来定义配置空间,以绘制有效样本。随机搜索是从该过程中绘制超参数分配并对其进行评估的算法。优化算法通过识别已经绘制的超参数来工作,并且基于损失函数在其他点处的值看起来很有希望。本文做出了两点贡献:1)随机搜索与[1]中DBN的手动优化是可竞争的。2)自动顺序优化优于手动和随机搜索。
第2节介绍基于顺序模型的优化和预期的改进标准。第3节介绍了一种基于高斯过程的超参数优化算法。第4节介绍了基于自适应Parzen窗的又一种方法。第5节描述了DBN超参数优化的问题,并显示了随机搜索的效率。第6节显示了根据随机搜索对两个最难的数据集进行顺序优化的效率。本文在第7节和第8节讨论了结果和总结。
2 基于顺序模型的全局优化(SMBO)
基于顺序模型的全局优化(SMBO)算法已被用于许多应用,其适应度函数的评估代价很高[8,9]。在真实的适应度函数 f : χ → R f:\chi \to \mathbb{R} f:χ→R 评估成本高的应用中,基于模型的算法近似评估 f f f 来得更便宜。通常,SMBO算法中的内循环是该代理的数值优化,或代理的某些变换。最大化代理(或其转换)的点 x ∗ x^{*} x∗ 是原本应评估的真实函数 f f f 的替代方案。这种主动学习的类似算法模板概括如图1。

图1 通用基于顺序模型的全局优化伪代码
SMBO算法的不同之处在于它们在给定 f f f 的模型(或代理)下优化以获得 x ∗ x^{*} x∗ 的标准,和在于它们的模型 f f f 通过观察历史 H \mathcal{H} H 。这项工作中的算法优化了预期改进(EI)的标准[10]。有其他已被提出的标准,例如改进概率和预期改进[10],最小化最小化器的条件熵[11],以及[12]中描述的基于强盗的标准。我们选择在我们的工作中使用EI标准,因为它是直观的,并且已经证明在各种环境中都能很好地工作。我们对未来工作的改进标准进行系统探索。预期的改进是在 f : χ → R N f:\chi \to \mathbb{R}^{N} f:χ→RN 的某个模型 M M M 下的期望 f ( x ) f(x) f(x) 将超过(负)某个阈值 y ∗ y^{*} y∗。
E I y ∗ ( x ) : = ∫ − ∞ ∞ m a x ( y ∗ − y , 0 ) p M ( y ∣ x ) d y \mathrm{EI}_{y^{*}}(x):=\int_{-\infty}^{\infty}\mathrm{max}(y^*-y,0)pM(y|x)dy EIy∗(x):=∫−∞∞max(y∗−y,0)pM(y∣x)dy
这项工作的贡献是通过建模 H \mathcal{H} H: 一种分层高斯过程和树状结构Parzen估计,来近似 f f f 的两种新策略。这些分别在第3节和第4节中进行描述。
3 高斯过程方法(GP)
在基于模型的优化文献中,高斯过程一直被认为是建模损失函数的好方法[13]。高斯过程(GPs,[14])是封闭的欠采样(原文closed under sampling)函数的先验,这意味着如果 f f f 的先验分布被认为是具有均值0和核k的GP,则从 f f f 的条件分布得知样本 H = ( x i , f ( x i ) ) i = 1 n \mathcal{H}=(x_{i},f(xi))^{n}_{i=1} H=(xi,f(xi))i=1n 的值也是GP,其均值和协方差函数可以通过分析推导出来。原则上可以使用具有通用平均函数的GP,但是对于我们的目的而言,仅考虑零均值过程更简单且充分。我们通过将函数值集中在所考虑的数据集中来实现。例如建模GP均值的线性趋势导致使用SMBO出现非探索区域中的非期望外推[15]。
上面提到的封闭性,以及GP提供包含数据稀缺性影响的预测不确定性评估的事实,使得GP成为寻找候选 x x x (图1步骤3)和拟合模型 M t M_{t} Mt 的简炼方法(图1步骤6)。GP方法的每次迭代运行时间在 ∣ H ∣ \left|\mathcal{H}\right| ∣H∣ 中立方地缩放并且在被优化的变量中线性地缩放,但是功能评估 f ( x ∗ ) f(x^*) f(x∗) 的花费通常甚至在该立方成本中占主导地位。
3.1 使用GP优化EI
我们用GP对 f f f 进行建模,并将 y ∗ y^{*} y∗ 设置为观察 H : y ∗ = m i n { f ( x i ) , 1 ≤ i ≤ n } \mathcal{H}:y^{*}=\mathrm{min}\{f(x_{i}),1\le i \le n\} H:y∗=min{f(xi),1≤i≤n} 后找到的最佳值。(1)中的模型 p M pM pM 是知道 H \mathcal{H} H 的后验GP。(1)中的EI函数在平均函数接近或优于 y ∗ y^{*} y∗ 的区域和不确定性高的欠探索区域之间进行折衷。
EI函数通常通过输入空间上的详尽网格搜索或更高维度的拉丁超立方搜索进行优化。然而,关于EI标准的一些地形信息可以从简单的计算得出[16]:1)它总是非负的并且在 D \mathcal{D} D 的训练点处为零,2)它继承了核 k k k 的平滑性,在实践中通常至少一次可微分,3)EI标准可能是高度多模态的,特别是随着训练点数量的增加。[16]的作者使用前面关于EI地形的评论来设计一种混合搜索的进化算法,特别是旨在优化EI,在EI评估中表现出优于对给定预算的穷举搜索。我们借用他们的方法更进一步。我们在输入空间的离散部分(分类和离散超参数)上保持了分布估计(EDA,[17])方法,其中我们根据二项分布对候选点进行采样,同时我们使用协方差矩阵适应进化策略(CMA-ES,[18])用于输入空间的剩余部分(连续超参数)。CMA-ES是一种用于连续域优化的最先进的无梯度进化算法,已被证明优于高斯搜索EDA。请注意,这种无梯度方法允许GP回归的不可微内核。我们不会像在[16]一样使用混合算法,而是从有机会的位置开始多次重启本地搜索。[16]建议使用的曲面细分在这里是禁止的,因为我们的任务通常意味着工作在10个以上的维度,因此我们在单纯的质点开始每个局部搜索,在训练点中随机选取顶点。
最后,我们注意到所有超参数都与每个点无关。例如,仅具有一个隐藏层的DBN没有与第二层或第三层相关联的参数。因此,在超参数的整个空间上放置一个GP是不够的。我们选择以树状方式通过共同使用超参数分组,并在每个组上放置不同的独立GP。例如,对于DBN,这意味着将一个GP放在常见的超参数上,包括指示要考虑的条件组的分类参数,与三个层中的每一个对应的参数上的三个GP,以及一些1维GP非独立控制的超参数,如ZCA能量(DBN参数见表1)。
4 树状结构Parzen估计方法(TPE)
预计我们的超参数优化任务将意味着高维度和小适应度评估预算,现在我们转向SMBO算法的另一种建模策略和EI优化方案。然而基于高斯过程的方法直接模拟 p ( y ∣ x ) p(y|x) p(y∣x) ,该策略模拟 p ( x ∣ y ) p(x|y) p(x∣y) 和 p ( y ) p(y) p(y) 。
回顾一下介绍,配置空间 X \mathcal{X} X 由图形结构的生成过程描述(例如,首先选择多个DBN层,然后为每个选择参数)。树形结构Parzen估计器(TPE)通过转换生成过程来模拟 p ( x ∣ y ) p(x|y) p(x∣y) ,用非参数密度替换先前配置的分布。在实验部分中,我们将看到使用均匀,对数均匀,量化对数均匀和分类变量来描述配置空间。在这些情况下,TPE算法进行以下替换:均匀 → \to → 截断高斯混合 → \to → 对数均匀 → \to → 指数截断高斯混合,分类 → \to → 再加权分类。在非参数密度中使用不同的观察值 { x ( 1 ) , . . . , x ( k ) } \{x^{(1)},...,x^{(k)}\} {x(1),...,x(k)} ,这些替换表示可以在配置空间 X \mathcal{X} X 上产生各种密度的学习算法。TPE使用两个这样的密度定义 p ( x ∣ y ) p(x|y) p(x∣y) :
p ( x ∣ y ) = { ℓ ( x ) if y < y ∗ g ( x ) if y ≥ y ∗ , p(x|y) =
{ℓ(x)g(x)amp;if y<y∗amp;if y≥y∗,
p(x∣y)={ℓ(x)g(x)if y<y∗if y≥y∗,
其中 ℓ ( x ) \ell(x) ℓ(x) 是通过使用算法 { x ( k ) } \{x^{(k)}\} {x(k)} 观察形成的密度,使得相应的损失 f ( x ( i ) ) f(x^{(i)}) f(x(i)) 小于 y ∗ y^{*} y∗ ,并且 g ( x ) g(x) g(x) 是通过使用剩余观察值形成的密度。虽然基于GP的方法倾向于积极的 y ∗ y^{*} y∗ (通常小于观察到的最佳损失),但TPE算法取决于大于最佳观察到的 f ( x ) f(x) f(x) 的 y ∗ y^{*} y∗ ,因此可以使用某些点来形成 ℓ ( x ) \ell(x) ℓ(x) 。TPE算法选择 y ∗ y^{*} y∗ 作为观察到的 y y y 值的一些分位数 γ \gamma γ ,因此 p ( y < y ∗ ) = γ p(y\lt y^{*})=\gamma p(y<y∗)=γ ,但不需要 p ( y ) p(y) p(y) 的特定模型。通过在 H \mathcal{H} H 中维护观察到的变量的排序列表,TPE算法的每次迭代的运行时间可以在 ∣ H ∣ |\mathcal{H}| ∣H∣ 中线性缩放并且在被优化的变量(维度)的数量中线性地缩放。
4.1 优化TPE算法中的EI
选择TPE算法中 p ( x , y ) p(x,y) p(x,y) 作为 p ( y ) p ( x ∣ y ) p(y)p(x|y) p(y)p(x∣y) 的参数化以促进EI的优化。
E I y ∗ ( x ) = ∫ − ∞ y ∗ ( y ∗ − y ) p ( y ∣ x ) d y = ∫ − ∞ y ∗ ( y ∗ − y ) p ( x ∣ y ) p ( y ) p ( x ) \mathrm{EI}_{y^{*}}(x)=\int_{-\infty}^{y^{*}}(y^{*}-y)p(y|x)dy=\int_{-\infty}^{y^{*}}(y^{*}-y)\frac{p(x|y)p(y)}{p(x)} EIy∗(x)=∫−∞y∗(y∗−y)p(y∣x)dy=∫−∞y∗(y∗−y)p(x)p(x∣y)p(y)
通过构造 γ = p ( y < y ∗ ) \gamma =p(y<y^{*}) γ=p(y<y∗)和 p ( x ) = ∫ R p ( x ∣ y ) p ( y ) d y = γ ℓ ( x ) + ( 1 − γ ) g ( x ) p\left( x \right) =\int_{\mathbb{R}}{p\left( x|y \right) p\left( y \right) dy=\gamma \ell \left( x \right) +\left( 1-\gamma \right) g\left( x \right)} p(x)=∫Rp(x∣y)p(y)dy=γℓ(x)+(1−γ)g(x)
因此,
∫ − ∞ y ∗ ( y ∗ − y ) p ( x ∣ y ) p ( y ) d y = ℓ ( x ) ∫ − ∞ y ∗ ( y ∗ − y ) p ( y ) d y = γ y ∗ ℓ ( x ) − ℓ ( x ) ∫ − ∞ y ∗ p ( y ) d y \int_{-\infty}^{y^*}{\left( y^*-y \right) p\left( x|y \right) p\left( y \right) \text{d}y}=\ell \left( x \right) \int_{-\infty}^{y^*}{\left( y^*-y \right)}p\left( y \right) dy=\gamma y^*\ell \left( x \right) -\ell \left( x \right) \int_{-\infty}^{y^*}{p\left( y \right) dy} ∫−∞y∗(y∗−y)p(x∣y)p(y)dy=ℓ(x)∫−∞y∗(y∗−y)p(y)dy=γy∗ℓ(x)−ℓ(x)∫−∞y∗p(y)dy
最后,
E I y ∗ ( x ) = γ y ∗ ℓ ( x ) − ℓ ( x ) ∫ − ∞ y ∗ p ( y ) d y γ ℓ ( x ) + ( 1 − γ ) g ( x ) ∝ ( γ + g ( x ) ℓ ( x ) ( 1 − γ ) ) − 1 EI_{y^*}\left( x \right) =\frac{\gamma y^*\ell \left( x \right) -\ell \left( x \right) \int_{-\infty}^{y^*}{p\left( y \right) dy}}{\gamma ^{\ell \left( x \right)}+\left( 1-\gamma \right) g\left( x \right)}\propto \left( \gamma +\frac{g\left( x \right)}{\ell \left( x \right)}\left( 1-\gamma \right) \right) ^{-1} EIy∗(x)=γℓ(x)+(1−γ)g(x)γy∗ℓ(x)−ℓ(x)∫−∞y∗p(y)dy∝(γ+ℓ(x)g(x)(1−γ))−1
最后一个表达式表明,为了最大化改进,我们希望在点 x x x 下 ℓ ( x ) \ell(x) ℓ(x) 概率高同时 g ( x ) g(x) g(x) 概率低。 ℓ \ell ℓ 和 g g g 的树状结构形式使得根据 ℓ \ell ℓ 绘制许多候选者并且根据 g ( x ) / ℓ ( x ) g(x)/\ell(x) g(x)/ℓ(x) 来评估它们是容易的。在每次迭代中,算法返回具有最大EI的候选算法 x ∗ x^{*} x∗。
4.2 Parzen Estimator的细节
模型 ℓ ( x ) \ell(x) ℓ(x) 和 g ( x ) g(x) g(x) 是涉及离散值和连续值变量的分层过程。自适应Parzen估计器通过在 K K K 观测值 B = { x ( 1 ) , . . . , x ( k ) } ⊂ H \mathcal{B}=\{x^{(1)},...,x^{(k)}\} \subset\mathcal{H} B={x(1),...,x(k)}⊂H 附近放置一个模型而在 X \mathcal{X} X 上产生模型。每个连续超参数由一定间隔 ( a , b ) (a, b) (a,b) 或高斯或对数均匀分布的均匀先验指定。TPE用以 x ( i ) ∈ B x(i)\in\mathcal{B} x(i)∈B 中的每一个为中心的高斯方法代替先验的等加权混合。每个高斯方法的标准差被设置为到左和右邻点距离中的较大者,但是会被调整到合理范围内。在均匀的情况下,点 a a a 和 b b b 被认为是潜在的邻点。对于离散变量,假设先验是 N N N 个概率 p i p_{i} pi的向量,后向量元素与 N p i + C i N_{p_{i}}+C_{i} Npi+Ci 成比例,其中 C i C_{i} Ci 计算 B \mathcal{B} B 中选择 i i i 的出现。对数均匀超参数在对数域中被视为均匀。
表1:用于随机采样的DBN超参数分布。由“或”分隔的选项(如预处理(包括随机种子))的权重相等。符号 U U U 表示均匀, N \mathcal{N} N 表示高斯分布, l o g U log\ U log U 表示均匀分布在对数域中。CD(也称为CD-1)代表对比分歧,该算法用于初始化DBN的层参数。

5 随机搜索DBN中的超参数优化
形式化超参数优化的一个简单但最新的步骤是使用随机搜索[5]。[19]表明随机搜索比网格搜索更有效地优化单层神经网络分类器的参数。在本节中,我们评估了DBN优化的随机搜索,与[1]中进行的顺序网格辅助手动搜索相比较。
我们选择先前表1中列出的来定义DBN配置上的搜索空间。[1]中提供了数据集的细节,DBN模型以及基于CD的贪婪分层训练步骤。该先验对应于[1]的搜索空间,除了以下差异:(a)我们允许ZCA预处理[20],(b)我们允许每个层具有不同的大小,©我们允许对于每个层都有自己的CD训练参数,(d)我们允许将连续值数据视为CD算法中的伯努利均值(理论上更正确)或伯努利样本(更典型),以及(e)我们没有将实值超参数的可能值离散化。这些变化扩展了超参数搜索问题,同时将原始超参数搜索空间保持为扩展搜索空间的子集。
该初步随机搜索的结果如图2所示。
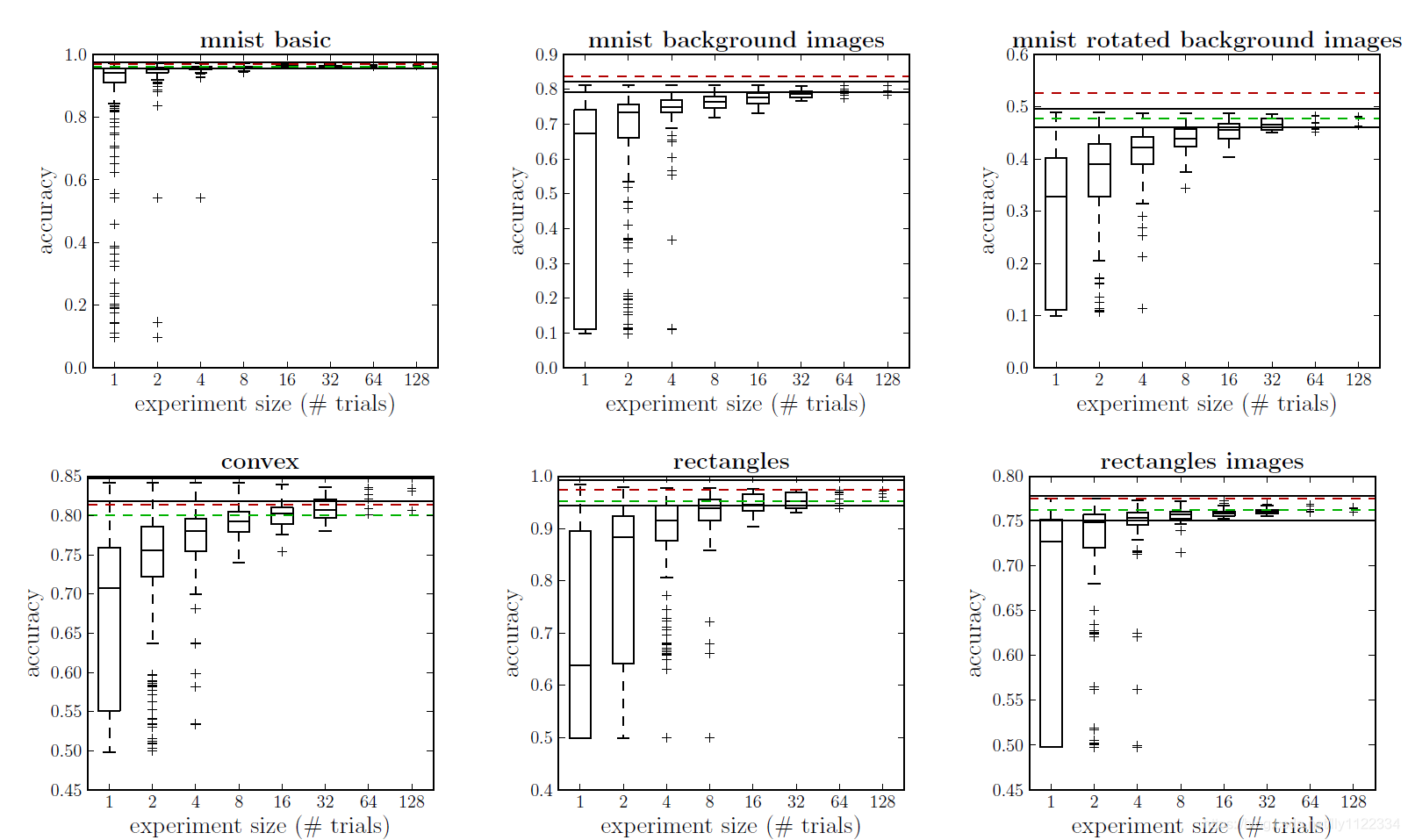
图2:深度信念网络(DBN)的性能根据随机搜索。随机搜索用于探索多达32个超参数(参见表1)。使用网格搜索辅助手动搜索在类似域上进行的结果平均41次试验以绿色(1层DBN)和红色(3层DBN)给出。每个箱形图(对于 N = 1 , 2 , 4... N=1,2,4... N=1,2,4...)显示当选择N个随机试验中的最佳模型时测试集性能的分布。 数据集“convex”和“mnist旋转背景图像”用于更彻底的超参数优化。
也许令人惊讶的是,手动搜索的结果可以与几个数据集的32次随机试验可靠地匹配。在[21]中进一步探讨了此设置中随机搜索的效率。在随机搜索结果与人类表现相匹配的情况下,从图2中不清楚其原因是它是否有效地搜索了原始空间,或者它搜索了更容易找到良好性能的更大空间。但是随机搜索通过搜索更大的空间以某种方式作弊的反对意见是相反的——表1中列出的搜索空间是超参数优化问题的自然描述,并且[1]对该空间的限制可能是简化搜索问题,使其易于网格搜索辅助手动搜索。关键的是,这两种方法都在相同的数据集上训练DBN。
图2中的结果表明,对于某些数据集,超参数优化更难。例如,在“MNIST旋转背景图像”数据集(MRBI)的情况下,随机抽样似乎相对较快地收敛到最大值(32个试验的实验中的最佳模型显示性能差异很小),但这个稳定水平低于手动搜索。在另一个数据集(convex)中,随机抽样程序超出了手动搜索的性能,但收敛到任何类型的平台都很慢。当选择32个模型中的最佳模型时,泛化存在相当大的差异。这种缓慢的收敛表明可能有更好的性能,但我们需要更有效地搜索配置空间才能找到它。本文的其余部分探讨了这两个数据集的超参数优化的顺序优化策略:convex和MRBI。
6 在DBN中顺序搜索超参数优化
我们通过与波士顿房价数据集上的随机抽样进行比较验证了第3.1节的GP方法,这是一个由13个标度输入变量和标量回归输出组成的506个点的回归任务。我们训练了一个具有10个超参数的多层感知器(MLP),包括学习率, ℓ 1 \ell_{1} ℓ1 和 ℓ 2 \ell_{2} ℓ2 惩罚,隐藏层的大小,迭代次数,是否应用PCA预处理,其能量是唯一的有条件的超参数[22]。我们的结果如图3所示。前30次迭代是使用随机抽样进行的,而从第30次开始,我们将随机样本与在更新历史上训练的GP方法区分开来。该实验重复了20次。尽管与维度相比点的数量特别少,但代理建模方法比随机点具有明显更好的点,这支持将SMBO方法应用于更雄心勃勃的任务和数据集。
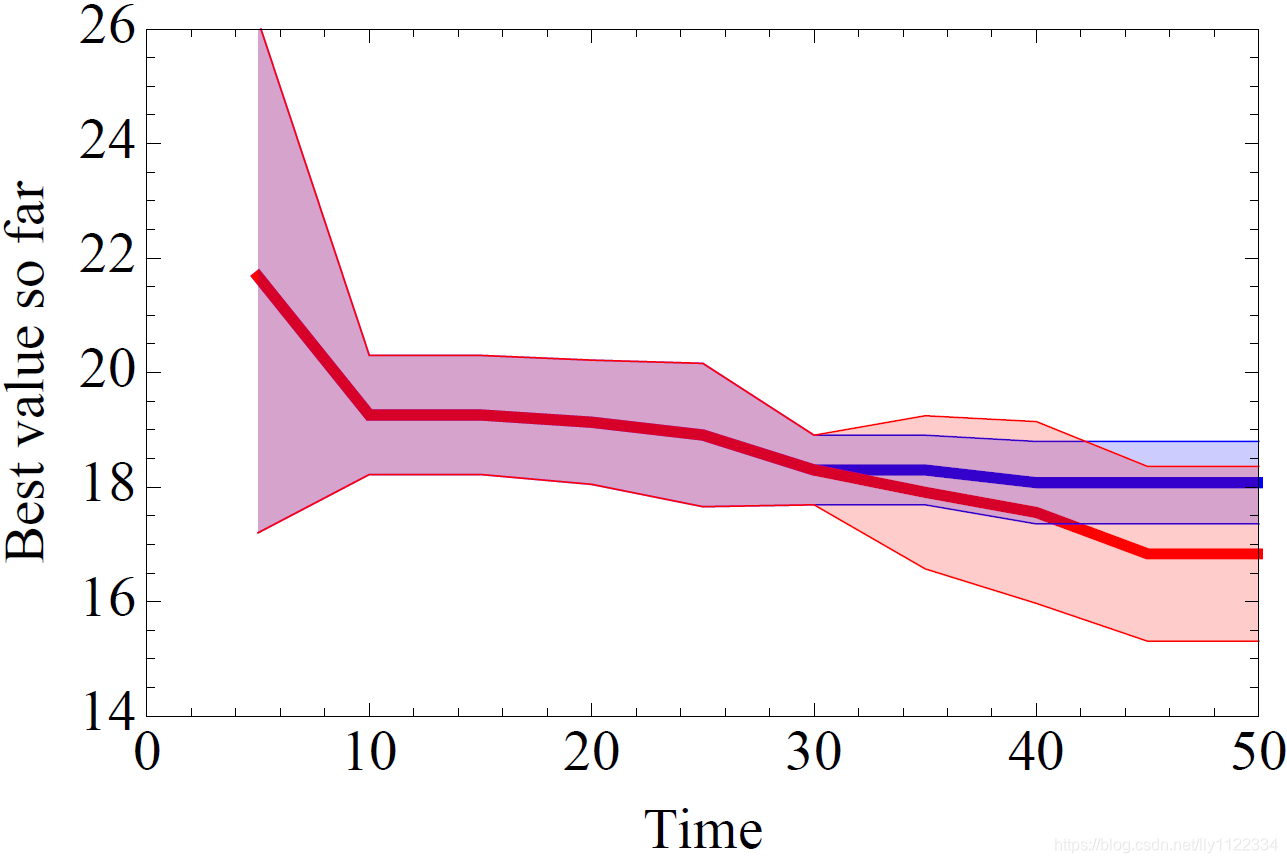
图3:在时间30之后,GP优化波士顿房价回归任务中的MLP超参数。 到目前为止,每5次迭代发现的最佳最小值,与时间相关。 红色=GP,蓝色=随机。阴影区域=1-sigma误差条。

表2:每个搜索算法针对每个问题找到的最佳模型的测试集分类错误。每个搜索算法最多允许200次试验。手动搜索使用82个试验convex和27个试验MRBI。
将GP应用于优化DBN性能的问题,我们允许每个提议 x ∗ x^{*} x∗ 对CMA + ES算法进行3次随机重启,并且在拟合GP的长度尺度时允许最多500次迭代的共轭梯度方法。平方指数内核[14]用于每个节点。GP的CMA-ES部分使用惩罚方法处理边界,二项式采样部分本质上处理它。在 H \mathcal{H} H 中用30个随机采样点初始化GP算法。在200次试验后,使用该GP预测点 x ∗ x^{*} x∗ 需要大约150秒。对于基于TPE的算法,我们选择了 γ = 0.15 \gamma=0.15 γ=0.15 ,并且在每次迭代中从 ℓ ( x ) \ell(x) ℓ(x) 中抽取的100个候选中的最佳选择为提议 x ∗ x^{*} x∗ 。在200次试验之后,使用该TPE算法预测点 x ∗ x^{*} x∗ 需要大约10秒。允许TPE在优化过程中超过用于随机采样的初始界限,而GP和随机搜索被限制在整个优化过程中保持在初始界限内。TPE算法用30个随机采样点进行初始化,GP算法也同样用这30个随机采样点播种。
6.1 并行化顺序搜索
GP和TPE方法实际上是异步运行的,以便利用多个计算节点并避免浪费时间等待试验评估完成。对于GP方法,使用所谓的恒定骗子(constant liar)方法:每次提出候选点 x ∗ {x^{*}} x∗ 时,临时分配等于训练集 D \mathcal{D} D 内的 y y y'的平均值的假适应性评估,直到评估完成为止。 并报告实际损失loss f ( x ∗ ) f(x^{*}) f(x∗)。对于TPE方法,我们简单地忽略了最近提出的点,并依赖于来自 ℓ ( x ) \ell(x) ℓ(x) 绘制的随机性来提供从一次迭代到下一次迭代的不同候选。并行化的结果是每个提议 x ∗ x^{*} x∗ 都基于较少的反馈。这使搜索效率降低,但在墙上时钟时间方面更快。
无论是否在GTX 285,470,480或580上执行,每次试验的运行时间限制为1小时GPU计算。最慢和最快的机器之间的速度差异在理论上大约是两倍,但实际的计算效率还取决于机器的负载和问题的配置(不同卡的相对速度在不同超参数配置下是不同的)。通过GP和TPE算法对多达五个提案的并行评估,每个实验使用五个GPU花费大约24小时的待机时间。
7 讨论
每个算法构建的轨迹( H \mathcal{H} H)最多200步,如图4所示,并与随机搜索和[1]中进行的手动搜索进行了比较。
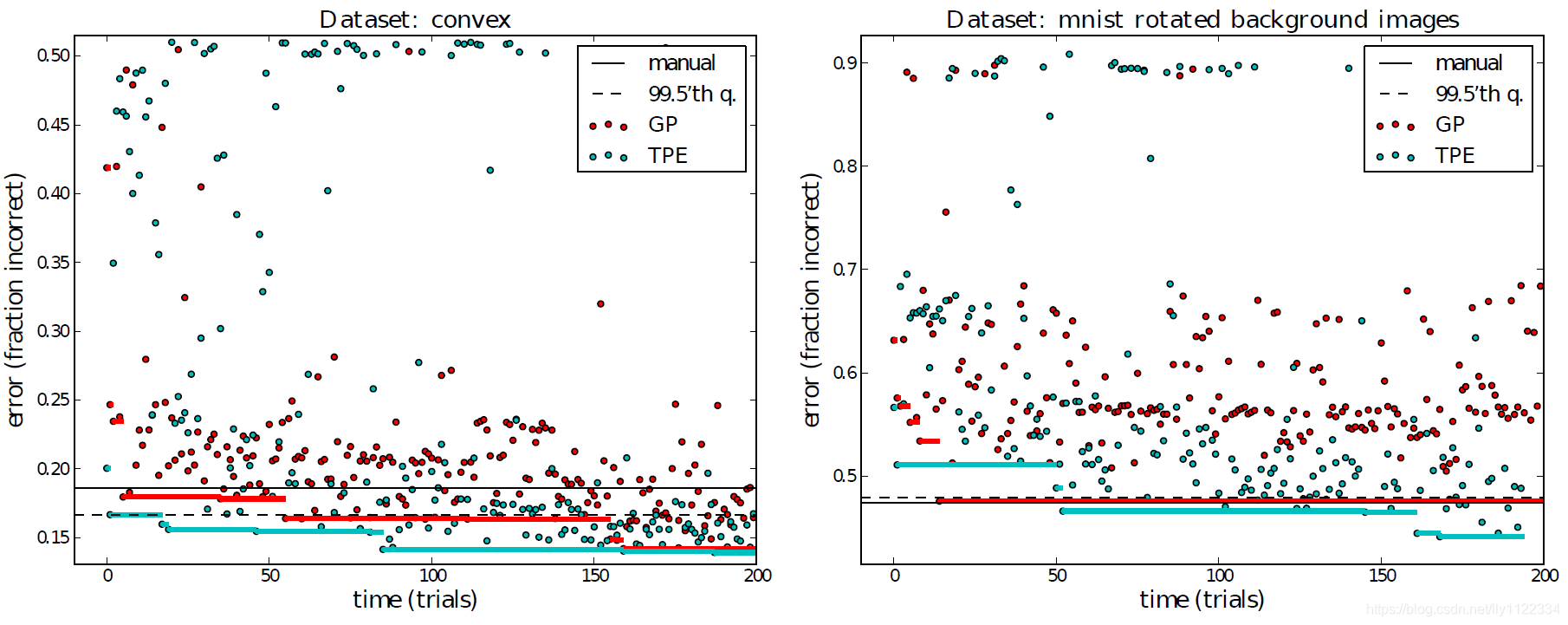
图4:基于高斯过程(GP)和基于图形模型(TPE)顺序优化算法的效率,用于在convex任务(左)和MRBI任务(右)上优化多达三层的DBN的验证集性能的任务。点是每个SMBO算法产生的轨迹 H \mathcal{H} H 的元素。纯色线是在每个时间点之前找到的最佳试验的验证集准确度。TPE和GP算法都从其随机初始条件中取得了显著进步,并且大大优于手动和随机搜索方法。关于convex任务的最佳验证方法的95%置信区间在每个点的上方和下方延伸0.018,在MRBI任务上在每个点的上方和下方延伸0.021。实线黑线是领域专家使用网格搜索和手动搜索[1]的组合获得的测试集精度。虚线是从我们之前的分布(参见表1)中抽样的试验中发现的99.5%验证性能的分位数,分别根据两个数据集的457和361个随机试验估算。
使用这些算法和其他算法找到的最佳模型的泛化分数列于表2中。在convex数据集(二分类)上,两种算法都收敛到13%误差的验证分数。总的来说,TPE的最佳模型有14.1%的误差,而GP的最佳模型有16.7%。TPE的最佳效果显着优于手动搜索(19%)和随机搜索200个试验(17%)。在MRBI数据集(十分类)上,随机搜索是表现最差的(50%误差),GP方法和手动搜索大致相关(47%误差),而TPE算法发现了新的最佳结果(44%误差))。特别是TPE算法找到的模型比以前在两个数据集上找到的模型都要好。GP和TPE算法的效率略低于手动搜索:GP和EI在80次试验中达到了与手动搜索相当的性能,[1]的手动搜索使用了82个convex试验和27个MRBI试验。
TPE方法在这两个数据集中的表现优于GP方法有几种可能的原因。也许 p ( x ∣ y ) p(x|y) p(x∣y) 的逆分解比高斯过程中的 p ( y ∣ x ) p(y|x) p(y∣x) 更准确。或许,相反,TPE缺乏准确性引发的探索结果证明是一种很好的搜索启发式算法。也许GP方法本身的超参数没有设置为在DBN配置空间中正确地权衡利用和探索。需要更多的实证研究来检验这些假设。然而,至关重要的是,所有四个SMBO运行都匹配或超过了随机搜索和仔细的人工引导搜索,这些搜索目前是超参数优化的最先进方法。
GP和TPE算法在这两种设置中都运行良好,但是这些算法需要一些明确的设置,实际上SMBO算法一般不会很好。顺序优化算法通过利用观察到的 ( x , y ) (x,y) (x,y) 对中的结构来工作。对于 p ( y ∣ x ) p(y|x) p(y∣x) 的错误选择,SMBO可能是任意不好的。如果它在 H \mathcal{H} H 中提取仅导致局部最优的结构,则在发现具有明显好的 p ( y ∣ x ) p(y|x) p(y∣x) 的全局最优时,也可能比随机采样慢。
8 结论
本文介绍了两种连续的超参数优化算法,并证明它们在涉及DBN的两个困难的超参数优化任务中满足或超过人的性能和蛮力随机搜索的性能。我们在搜索空间上放宽了标准约束(例如,所有层上的相等图层大小),并回退到32个变量(包括离散变量和连续变量)的更自然的超参数空间,其中许多变量有时不相关,具体取决于其他参数的值(例如层数)。在这个32维搜索问题中,这里介绍的TPE算法已经在这两个数据集上发现了新的最佳结果,这些结果明显优于之前认为的DBN。此外,GP和TPE算法是实用的:每个数据集的优化仅使用5个GPU处理器在24小时内完成。虽然我们的结果仅适用于DBN,但我们的方法非常通用,并且自然地扩展到任何超参数优化问题,其中超参数是从可测量的集合中提取的。
我们希望我们的工作可以激励机器学习社区的研究人员将超参数优化策略视为所有学习算法中一个有趣且重要的组成部分。“DBN对convex任务的效果如何?”这个问题并不是一个完全具体的、经验上可回答的问题——超参数优化的不同方法会给出不同的答案。超参数优化的算法方法使机器学习结果更容易传播,再现和转移到其他域。我们在此提出的具体算法至少在某些情况下也能够找到比以前已知的更好的结果。最后,强大的超参数优化算法拓宽了可以实际研究的模型的范围;研究人员不需要将自己局限于一些易于手动调整的变量系统。
本工作中提出的TPE算法以及并行评估基础架构可作为BSD许可的免费开源软件提供,该软件不仅可以在这项工作中重现结果,而且还可以促进这些和与其他超参数优化问题类似的算法。
Hyperopt:https://github.com/jaberg/hyperopt
鸣谢
这项工作得到了加拿大国家科学与工程研究委员会,Compute Canada以及法国国家研究机构的ANR-2010-COSI-002资助。 DBN模型的GPU实现由Theano [23]提供。
参考文献
[1] H. Larochelle, D. Erhan, A. Courville, J. Bergstra, and Y. Bengio. An empirical evaluation of deep architectures on problems with many factors of variation. In ICML 2007, pages 473–480, 2007.
[2] G. E. Hinton, S. Osindero, and Y. Teh. A fast learning algorithm for deep belief nets. Neural omputation, 18:1527–1554, 2006.
[3] P. Vincent, H. Larochelle, I. Lajoie, Y. Bengio, and P. A. Manzagol. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Machine Learning
Research, 11:3371–3408, 2010.
[4] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, November 1998.
[5] Nicolas Pinto, David Doukhan, James J. DiCarlo, and David D. Cox. A high-throughput screening approach to discovering good forms of biologically inspired visual representation. PLoS Comput Biol, 5(11):e1000579, 11 2009.
[6] A. Coates, H. Lee, and A. Ng. An analysis of single-layer networks in unsupervised feature learning.
NIPS Deep Learning and Unsupervised Feature Learning Workshop, 2010.
[7] A. Coates and A. Y. Ng. The importance of encoding versus training with sparse coding and vector quantization. In Proceedings of the Twenty-eighth International Conference on Machine Learning (ICML-11), 2010.
[8] F. Hutter. Automated Configuration of Algorithms for Solving Hard Computational Problems. PhD thesis, University of British Columbia, 2009.
[9] F. Hutter, H. Hoos, and K. Leyton-Brown. Sequential model-based optimization for general algorithm configuration. In LION-5, 2011. Extended version as UBC Tech report TR-2010-10.
[10] D.R. Jones. A taxonomy of global optimization methods based on response surfaces. Journal of Global Optimization, 21:345–383, 2001.
[11] J. Villemonteix, E. Vazquez, and E. Walter. An informational approach to the global optimization of
expensive-to-evaluate functions. Journal of Global Optimization, 2006.
[12] N. Srinivas, A. Krause, S. Kakade, and M. Seeger. Gaussian process optimization in the bandit setting:
No regret and experimental design. In ICML, 2010.
[13] J. Mockus, V. Tiesis, and A. Zilinskas. The application of Bayesian methods for seeking the extremum.
In L.C.W. Dixon and G.P. Szego, editors, Towards Global Optimization, volume 2, pages 117–129. North
Holland, New York, 1978.
[14] C.E. Rasmussen and C. Williams. Gaussian Processes for Machine Learning.
[15] D. Ginsbourger, D. Dupuy, A. Badea, L. Carraro, and O. Roustant. A note on the choice and the estimation of kriging models for the analysis of deterministic computer experiments. 25:115–131, 2009.
[16] R. Bardenet and B. K´egl. Surrogating the surrogate: accelerating Gaussian Process optimization with
mixtures. In ICML, 2010.
[17] P. Larra˜naga and J. Lozano, editors. Estimation of Distribution Algorithms: A New Tool for Evolutionary Computation. Springer, 2001.
[18] N. Hansen. The CMA evolution strategy: a comparing review. In J.A. Lozano, P. Larranaga, I. Inza, and
E. Bengoetxea, editors, Towards a new evolutionary computation. Advances on estimation of distribution
algorithms, pages 75–102. Springer, 2006.
[19] J. Bergstra and Y. Bengio. Random search for hyper-parameter optimization. The Learning Workshop
(Snowbird), 2011.
[20] A. Hyv¨arinen and E. Oja. Independent component analysis: Algorithms and applications. Neural Networks, 13(4–5):411–430, 2000.
[21] J. Bergstra and Y. Bengio. Random search for hyper-parameter optimization. JMLR, 2012. Accepted.
[22] C. Bishop. Neural networks for pattern recognition. 1995.
[23] J. Bergstra, O. Breuleux, F. Bastien, P. Lamblin, R. Pascanu, G. Desjardins, J. Turian, and Y. Bengio.
Theano: a CPU and GPU math expression compiler. In Proceedings of the Python for Scientific Computing
Conference (SciPy), June 2010.
深度学习超参数介绍及调参策略
什么是超参数?超参数有哪些? |