标注:本博客是参考论文有《传统情感分类方法与机遇深度学习的情感分类方法对比分析》、《自然语言处理中的深度学习:方法及应用》
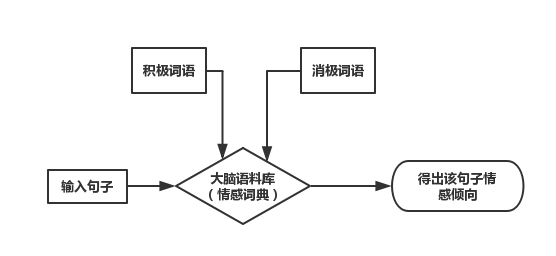
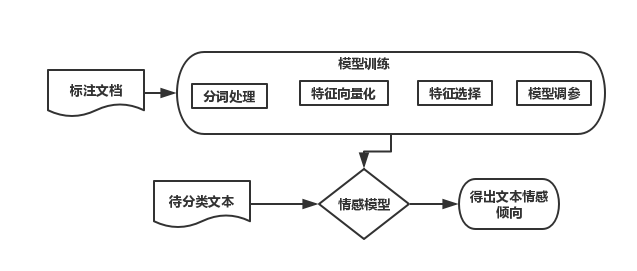
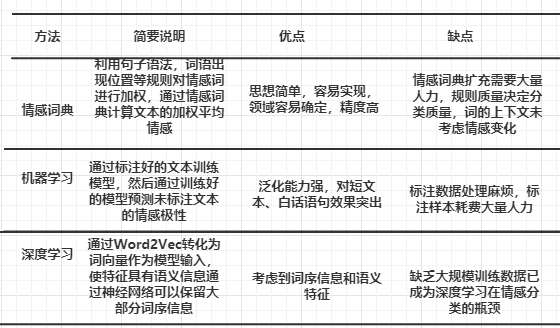
情感分类是自然语言处理的重要分支,传统情感分类主要有基于情感词典的和基于机器学习的,最新的方法是基于深度学习的。
缺点:受限于情感词典的质量和覆盖度。
核心:模型训练
定义:
深度学习是基于特征自学习和深度神经网络(DNN)的一系列机器学习算法的总称。目前深度学习的研究有了长足发展,在传统特征选择与提取框架上取得巨大突破,在自然语言处理、生物医学分析、遥感影像解译等诸多领域产生越来越重要影响,并在计算机视觉和语音识别领域取得革命性突破。
NLP研究任务包括
词性标注、机器翻译、命名实体识别、机器问答、情感分析、自动文摘、句法分析和共指消解等。
深度学习应用在NLP领域原因:
不使用传统神经网络原因
传统神经网络无法处理前后关联问题,而深度学习模型RNN解决了该问题。随着距离和先验知识的增加,RNN会出现梯度消失或梯度爆炸情况,因此无法解决长久依赖问题。而LSTM通过三个门结构控制细胞cell,解决上述问题。
深度学习优点:
基于深度学习抽象特征,可避免人工提取特征的工作,且通过Word2Vec技术模拟词语之间联系,有局部特征抽象画以及记忆功能,在情感分类中具有极大优势。
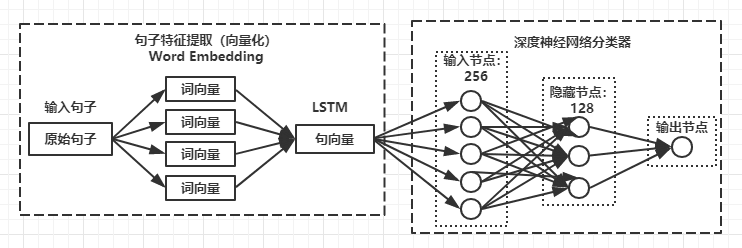
现有深度学习方法主要分为两个步骤:
将需要分类的评论语料表达为语义词向量(Word Embedding);
通过不同语义合成方法用词向量得到所对应句子或文档的特征表达式,最后通过深度神经网络进行分类。
在自然语言处理中,很重要的一个问题是如何将一个句子用向量表示。词向量通常是指通过语言模型学习到的词的分布式特征表示,也被称为词编码。可以非稀疏的表示大规模语料中复杂的上下文信息。
传统文档表示方法是基于词袋模型。
极高维度:文本向量的维数与训练数据集中出现的所有单词数一样多,且若某一词汇在训练集中未出现过,则会忽视这个词,在测试集中无法成为该文本特征。
向量极度稀疏
认为词语之间无关系,很难表示一个句子或一篇短文的语义,
不同语境下,词袋法很难区分一个词的意义。
该模型由Mikolov等人提出,核心思想是通过高维向量表示词语,相近词语放在相近位置,因此Word2Vec适合处理序列数据,因为序列局部间的数据存在很大关联。通过Word2Vec可训练语料库模型,获得词向量,且词向量的高维性解决了词语多方向发散问题,从而保证模型的稳定性。
通过不同语义合成(Semantic Composition)方法用词向量得到所对应句子或文档的特征表达,语义词向量就是利用原始词向量合成更高层次的文本特征向量。
循环神经网络和长短记忆神经网络
循环神经网络(Recurrent neural networks,RNN)是隐藏层和自身存在连接的一类神经网络。相较于前馈神经网络,RNN可将本次隐藏层的结果用于下次隐藏层的计算,因此可以用来处理时间序列问题,比如文本生成【28】、机器翻译【29】和语音识别【30】,RNN的优化算法为BPTT算法(backpropagation through time)【31】,由于梯度消失的原因,RNN的反馈误差往往只能向后传递5-10层,因此文献【32】在RNN的基础上提出来长短记忆神经网络(long-short term memory,LSTM).LSTM使用Celljiegou 记忆之前的输入,使得网络可以学习到合适的时机重置Cell结构。
卷积神经网络(Convolutional neural networks,CNN)
CNN由文献【40】提出并由文献【41】改进的深度神经网络。在一般前馈神经网络中,输入层和隐藏层之间采用全连接结构,而在CNN中每一个卷积层节点只与一个固定大小的区域有连接,连接的权重矩阵称为卷积核。池化(pooling)是CNN所采用的另一个关键技术,在固定大小的区域使用平均值或最大值代替原有的矩阵区域,既减少了特征数目又增加了网络的鲁棒性。
目前深度学习的理论依据还处于起步阶段,大部分的研究成果都是经验性的,没有足够的理论来指导实验,研究者无法确定网络架构。超参数设置是否已是最优组合。除此之外,目前仍没有一种通用的神经网络或学习策略可以适用于大多数的应用任务,因此深度学习领域的研究者正在不断尝试新的网络架构和学习策略,以提升网络的泛化能力。
将原始文本作为输入,自学习得到文本特征的分布表示。
将分布式向量特征作为深度神经网络的输入。
针对不同的应用需求,使用不同的深度学习模型,有监督的训练网络权重。