这篇教程深度学习实践系列之--身份证上汉字及数字识别系统的实现(下)写得很实用,希望能帮到您。
深度学习实践系列之--身份证上汉字及数字识别系统的实现(下)
此文为本人原创,转载请注明:http://www.cnblogs.com/ygh1229/p/7227660.html
接上文: 深度学习实践系列之--身份证上汉字及数字识别系统的实现(上)
训练完成后,就要对模型进行测试:
在实验中,我取得一张数据测试的图片,在word里输入三行数据并截一张图,如图所示:

图 测试图片示意图
然后将图片数据读到image_color和灰度image里面,让其生成灰度图,代码如下:
image_color = cv2.imread(path_test_image)
new_shape = (image_color.shape[1] * 2, image_color.shape[0] * 2)
image_color = cv2.resize(image_color, new_shape)
image = cv2.cvtColor(image_color, cv2.COLOR_BGR2GRAY)
读取到图片后,然后对图像进行二值化处理,生成的二值化后的灰度图如图所示:

图 数据图片灰度图
然后使用水平投影的方法提取每一行的文本,使用垂直投影的方法切分每个字符,为了展示切分的效果,我将水平方向的图像求和,然后利用Opencv的库函数画出结果,部分代码如下:
plt.plot(horizontal_sum, range(horizontal_sum.shape[0]))
plt.gca().invert_yaxis()
plt.show()
最后画出的结果图如图所示,可以见到文本行被明显分隔出来:
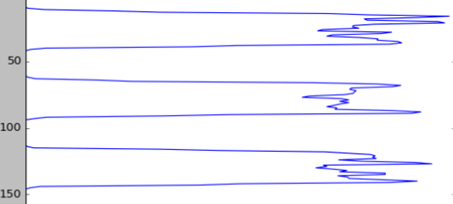
图 水平投影图像求和波形图
在输入的数据图片中有三行文本,在图中的纵轴上的波谷就代表行间的空白区域,同理也可以垂直投影将每个字符切割出来,最后的切割效果图如图所示:

图 字符切分后的数据图
在图中可以看出有部分字符没有切分出来,有“深”、“如”和“对”字,这是因为因为它们的组成都是左右结构,由于组合时不紧密,切分中还没有解决这类问题,所以没有切分到。
然后为了将数据图片放入模型识别,根据切分结果获取到数据图片中的每一个字符图片,如图所示:

图 部分数据图中截取的字符图
然后将这些取出来的字符图片依次放入模型中识别,
caffe_cls = CaffeCls(model_def, model_weights, y_tag_json_path)
output_tag_to_max_proba = caffe_cls.predict_cv2_imgs(np_char_imgs)
在终端下运行这个python的脚本,然后经过图片处理和模型的计算,最终在终端下输出结果,输出的结果如图所示:

图 图片中字符识别结果图
在图中可以看出,在图片处理时个别字符没有切分出来,但是定位切分成功的字符都识别出来了,并且除了一个“级”识别有小错误,其他字符全部识别正确。
这里贴出测试时python脚本的核心代码: 
cv2_color_img = cv2.imread(test_image)
##放大图片
resize_keep_ratio = PreprocessResizeKeepRatio(1024, 1024)
cv2_color_img = resize_keep_ratio.do(cv2_color_img)
##转换成灰度图
cv2_img = cv2.cvtColor(cv2_color_img, cv2.COLOR_RGB2GRAY)
height, width = cv2_img.shape
##二值化 调整自适应阈值 使得图像的像素值更单一、图像更简单
adaptive_threshold = cv2.adaptiveThreshold(
cv2_img, ##原始图像
255, ##像素值上限
cv2.ADAPTIVE_THRESH_GAUSSIAN_C, ##指定自适应方法Adaptive Method,这里表示领域内像素点加权和
cv2.THRESH_BINARY, ##赋值方法(二值化)
11, ## 规定领域大小(一个正方形的领域)
2) ## 常数C,阈值等于均值或者加权值减去这个常数
adaptive_threshold = 255 - adaptive_threshold
## 水平方向求和,找到行间隙和字符所在行(numpy)
horizontal_sum = np.sum(adaptive_threshold, axis=1)
## 根据求和结果获取字符行范围
peek_ranges = extract_peek_ranges_from_array(horizontal_sum)
vertical_peek_ranges2d = []
for peek_range in peek_ranges:
start_y = peek_range[0] ##起始位置
end_y = peek_range[1] ##结束位置
line_img = adaptive_threshold[start_y:end_y, :]
## 垂直方向求和,分割每一行的每个字符
vertical_sum = np.sum(line_img, axis=0)
## 根据求和结果获取字符行范围
vertical_peek_ranges = extract_peek_ranges_from_array(
vertical_sum,
minimun_val=40, ## 设最小和为40
minimun_range=1) ## 字符最小范围为1
## 开始切割字符
vertical_peek_ranges = median_split_ranges(vertical_peek_ranges)
## 存放入数组中
vertical_peek_ranges2d.append(vertical_peek_ranges)
## 去除噪音,主要排除杂质,小的曝光点不是字符的部分
filtered_vertical_peek_ranges2d = []
for i, peek_range in enumerate(peek_ranges):
new_peek_range = []
median_w = compute_median_w_from_ranges(vertical_peek_ranges2d[i])
for vertical_range in vertical_peek_ranges2d[i]:
## 选取水平区域内的字符,当字符与字符间的间距大于0.7倍的median_w,说明是字符
if vertical_range[1] - vertical_range[0] > median_w*0.7:
new_peek_range.append(vertical_range)
filtered_vertical_peek_ranges2d.append(new_peek_range)
vertical_peek_ranges2d = filtered_vertical_peek_ranges2d
char_imgs = []
crop_zeros = PreprocessCropZeros()
resize_keep_ratio = PreprocessResizeKeepRatioFillBG(
norm_width, norm_height, fill_bg=False, margin=4)
for i, peek_range in enumerate(peek_ranges):
for vertical_range in vertical_peek_ranges2d[i]:
## 划定字符的上下左右边界区域
x = vertical_range[0]
y = peek_range[0]
w = vertical_range[1] - x
h = peek_range[1] - y
## 生成二值化图
char_img = adaptive_threshold[y:y+h+1, x:x+w+1]
## 输出二值化图
char_img = crop_zeros.do(char_img)
char_img = resize_keep_ratio.do(char_img)
## 加入字符图片列表中
char_imgs.append(char_img)
## 将列表转换为数组
np_char_imgs = np.asarray(char_imgs)
## 放入模型中识别并返回结果
output_tag_to_max_proba = caffe_cls.predict_cv2_imgs(np_char_imgs)
ocr_res = ""
## 读取结果并展示
for item in output_tag_to_max_proba:
ocr_res += item[0][0]
print(ocr_res.encode("utf-8"))
## 生成一些Debug过程产生的图片
if debug_dir is not None:
path_adaptive_threshold = os.path.join(debug_dir,
"adaptive_threshold.jpg")
cv2.imwrite(path_adaptive_threshold, adaptive_threshold)
seg_adaptive_threshold = cv2_color_img
# color = (255, 0, 0)
# for rect in rects:
# x, y, w, h = rect
# pt1 = (x, y)
# pt2 = (x + w, y + h)
# cv2.rectangle(seg_adaptive_threshold, pt1, pt2, color)
color = (0, 255, 0)
for i, peek_range in enumerate(peek_ranges):
for vertical_range in vertical_peek_ranges2d[i]:
x = vertical_range[0]
y = peek_range[0]
w = vertical_range[1] - x
h = peek_range[1] - y
pt1 = (x, y)
pt2 = (x + w, y + h)
cv2.rectangle(seg_adaptive_threshold, pt1, pt2, color)
path_seg_adaptive_threshold = os.path.join(debug_dir,
"seg_adaptive_threshold.jpg")
cv2.imwrite(path_seg_adaptive_threshold, seg_adaptive_threshold)
debug_dir_chars = os.path.join(debug_dir, "chars")
os.makedirs(debug_dir_chars)
for i, char_img in enumerate(char_imgs):
path_char = os.path.join(debug_dir_chars, "%d.jpg" % i)
cv2.imwrite(path_char, char_img)
完整代码详见: 链接
四、系统设计及实现
本文系统共分为两部分:移动(Android)端和服务器端。移动端共分为两个模块:输入模块和输出模块;服务器端共分为三个模块:模型加载模块、模型处理模块和结果映射模块。如图所示:
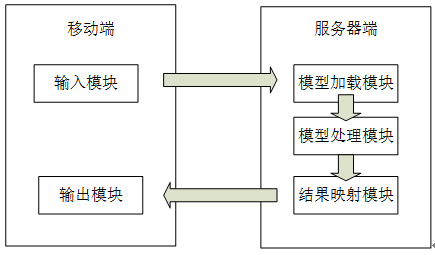
图 系统模型框架
其中,移动端的输入模块负责获取手机上身份证图片信息,包括从手机相册选择和手机拍照两种方式,输入模块获取到图片后再进行裁剪,去除其他背景使得正好裁剪出身份证图像,然后向服务器发送图片信息;输出模块负责接收服务器端返回的身份证上的个人信息,并将信息显示在手机移动端。
服务器端的模型加载模块负责接收移动端输入模块发送过来的身份证图片信息,经过图片预处理,进行文字定位,提取图片文字信息,将数据传入模型处理模块;模型处理模块接收到模型加载模块里的符合模型要求的数据格式,调用模型进行数据分类与识别,处理完成后依次输出每个处理后的数据到结果映射模块;结果映射模块接收到处理模块输出的数据后,将数据封装成json格式,然后返回给移动端进行下一步处理。
4.1 模型服务器端设计
(1)Flask服务器搭建
Flask是一个轻量级的 Web 应用框架,它使用Python语言编写的,优点是部署快,可移植性强。由于Flask的轻量级和易于移植,本文的服务器采用Flask架构开发,在Ubuntu系统中配置下载Flask包即可使用。
首先,本文通过pip下载Flask包,然后在程序中直接import了Flask 类就可以使用Flask的功能,非常简洁。为了让Flask服务器在本地服务器上运行,需要在main函数中执行 run()函数 ,核心代码如下:
if __name__ == '__main__':
app.run(host='0.0.0.0',port=8888)
其中上述代码的第一句表示这个函数时Python程序中的主函数,也就是执行程序时首先访问此函数,这样确保服务器的Flask脚本在终端下直接执行的时候会首先执行,而不能将其作为一个依赖导入其他程序中。本文搭建的Flask要在手机端访问,所以要设置外部可访问服务器:app.run(host='0.0.0.0',port=8888),这会让服务器监听所有在局域网内的 IP地址并且访问端口是8888。
编写好Python的WSGI程序,在终端下直接运行即可。服务器启动后会实时监听网络端口,当有数据请求发送到这一端口,Flask服务器获取数据请求体,然后将其中的身份证图片保存到服务器指定目录下。然后对身份证图像进行二值化处理,进行字符的分割,然后依次将字符放入训练好的模型中进行字符的识别,待模型识别完成后将结果返回,Flask服务器将结果封装成Json格式并返回到客户端。本文搭建的Flask服务器处理身份证图像的过程如图所示。

图 Flask系统流程图
(2)身份证图片预处理
在Android移动端摄像头拍摄的图片是彩色图像,上传到服务器后为了读取到身份证上的主要信息,就要去除其他无关的元素,因此对身份证图像取得它的灰度图并得到二值化图。
对身份证图像的的二值化有利于对图像内的信息的进一步处理,可以将待识别的信息更加突出。在OpenCV中,提供了读入图像接口函数imread, 首先通过imread将身份证图像读入内存中:
id_card_img = cv2.imread(path_img)
之后再调用转化为灰度图的接口函数cvtColor并给它传入参数COLOR_BGR2GRAY,它就可以实现彩色图到灰度图的转换,代码如下
gray_id_card_img = cv2.cvtColor(color_img, cv2.COLOR_BGR2GRAY)
preprocess_bg_mask = PreprocessBackgroundMask(boundary)
转化为二值化的灰度图后图像如图所示:

图 身份证图像灰度图
转换成灰度图之后要进行字符定位,通过每一行进行垂直投影,就可以找到所有字段的位置,具体结果如图4.4所示:

图 垂直投影后的灰度图
然后根据像素点起始位置,确定字符区域,然后将字符区域一一对应放入存放字符的列表中:
vertical_peek_ranges = extract_peek_ranges_from_array(
vertical_sum,
minimun_val=40,
minimun_range=1)
vertical_peek_ranges2d.append(vertical_peek_ranges)
最后的效果图如图所示:

图 字符切割后的效果图
(3) 身份证信息识别
在对身份证上字符截取后,开始调用模型进行识别,首先要初始化第三部分模型训练中生成的deploy网络模型,因为输入的数据会放入网络模型中进行参数匹配,核心代码如下:
base_dir = "/workspace/data/deepocr"
model_def = os.path.join(base_dir, "deploy_train_test.prototxt")
之后还要初始化经过训练得到的模型文件:
model_weights = os.path.join(base_dir, "lenet_iter_50000.caffemodel"
然后初始化训练的文字库清单文件列表:
y_tag_json_path = os.path.join(base_dir, "y_tag.json")
最后放入模型里开始识别,会对单个汉字进行分类,然后将识别结果与文字库文件一一映射,取出最终结果,并将身份证上的所有信息进行拼接,存入数组中:
ocr_res = reco_text_line.do(boundary2binimgs, segment, caffe_cls)
Flask向移动端返回数据采用json的格式,如下所示:
data =
[{"result":"sucess","response":
{"name":key_ocr_res["name"],
"address":key_ocr_res["address"]
……
"day":key_ocr_res["day"]}
}]
然后移动端解析json格式即可。
由于篇幅,附上我截取的代码,其余详见github: 链接
@app.route('/upload', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
f = request.files['file']
f.save('/home/ygh/flask/id_card_img.jpg')
## path_img = os.path.expanduser("/home/ygh/deep_ocr/data/id_card_img.jpg")
path_img = os.path.expanduser("/home/ygh/flask/id_card_img.jpg")
debug_path = os.path.expanduser("/home/ygh/deep_ocr_workspace/debug")
if debug_path is not None:
if os.path.isdir(debug_path):
shutil.rmtree(debug_path)
os.makedirs(debug_path)
cls_dir_sim = os.path.expanduser("/home/ygh/deep_ocr_workspace/data/chongdata_caffe_cn_sim_digits_64_64")
cls_dir_ua = os.path.expanduser("/home/ygh/deep_ocr_workspace/data/chongdata_train_ualpha_digits_64_64")
caffe_cls_builder = CaffeClsBuilder()
cls_sim = caffe_cls_builder.build(cls_dir=cls_dir_sim,)
cls_ua = caffe_cls_builder.build(cls_dir=cls_dir_ua,)
caffe_classifiers = {"sim": cls_sim, "ua": cls_ua}
seg_norm_width = 600
seg_norm_height = 600
preprocess_resize = PreprocessResizeKeepRatio(
seg_norm_width, seg_norm_height)
id_card_img = cv2.imread(path_img)
id_card_img = preprocess_resize.do(id_card_img)
segmentation = Segmentation(debug_path)
key_to_segmentation = segmentation.do(id_card_img)
boundaries = [
((0, 0, 0), (100, 100, 100)),
]
boundary2binimgs = []
for boundary in boundaries:
preprocess_bg_mask = PreprocessBackgroundMask(boundary)
id_card_img_mask = preprocess_bg_mask.do(id_card_img)
boundary2binimgs.append((boundary, id_card_img_mask))
char_set = CharSet()
char_set_data = char_set.get()
rect_img_clf = RectImageClassifier(
None,
None,
char_set,
caffe_cls_width=64,
caffe_cls_height=64)
reco_text_line = RecoTextLine(rect_img_clf)
key_ocr_res = {}
for key in key_to_segmentation:
key_ocr_res[key] = []
print("="*64)
print(key)
for i, segment in enumerate(key_to_segmentation[key]):
if debug_path is not None:
line_debug_path = "key_%s_%i" % (key, i)
line_debug_path = os.path.join(debug_path, line_debug_path)
reco_text_line.debug_path = line_debug_path
reco_text_line.char_set = char_set_data[key]
## 初始化模型
caffe_cls = caffe_classifiers[
char_set_data[key]["caffe_cls"]]
## 输入到模型中进行识别
ocr_res = reco_text_line.do(boundary2binimgs, segment, caffe_cls)
## 将结果输出到列表中
key_ocr_res[key].append(ocr_res)
print("ocr res:")
for key in key_ocr_res:
print("="*60)
print(key)
for res_i in key_ocr_res[key]:
print(res_i.encode("utf-8"))
if debug_path is not None:
path_debug_image_mask = os.path.join(
debug_path, "reco_debug_01_image_mask.jpg")
cv2.imwrite(path_debug_image_mask, id_card_img_mask)
## 返回结果 将其封装成json的键值对的格式
data = [{"result":"sucess","response":{"name":key_ocr_res["name"],"address":key_ocr_res["address"],"month":key_ocr_res["month"],
"minzu":key_ocr_res["minzu"],"year":key_ocr_res["year"],"sex":key_ocr_res["sex"],"id":key_ocr_res["id"],"day":key_ocr_res["day"]}}]
## data = '{"result":"sucess"}
## result = json.loads(data)
return json.dumps(data,skipkeys=True,ensure_ascii=False,encoding="utf-8")
else:
data2 = [{"result":"error"}]
## result2 = json.loads(data2)
return json.dumps(data2)
## return "error"
if __name__ == '__main__':
app.run(host='0.0.0.0',port=8880)
4.3 Android移动端设计
(1) 图片处理
Android端获取用户输入的身份证图像信息有两种方式,一种是拍照,一种是从手机相册里选择。首页点击“+”可以选择两种不同的方式,移动端首页如图所示:

图 移动端首页图
拍照获取图像
在主活动首页选择“拍照”按钮,按钮的点击事件是通过Intent机制调用系统相机功能开始拍照,首先通过getOutputMediaFileUri方法指定拍照后图片的保存位置,之后利用Intent对象带有MediaStore.ACTION_IMAGE_CAPTURE的参数开始拍照。
当获取到系统相机拍的照片后,在主活动的onActivityResult回调方法中调用startPhotoZoom(fileUri)方法进行身份证图片的裁剪,通过Intent机制调用系统相册的裁剪功能,首先利用getOutputMediaFileUri方法指定裁剪后图片的保存位置,然后指定Intent的动作为:action.CROP,然后开始裁剪当前图片。
调用系统相机的裁剪事件后,进行图像的剪切工作,之后通过Intent的putExtra方法将裁剪后的图片路径返回,
之后继续执行onActivityResult回调方法,进行访问接口,将获取到的图片上传到服务器端。
选择相册获取图像
在主活动首页选择“相册”按钮,按钮的点击事件是通过Intent启动系统相机的拍照功能,指定Intent的动作为ACTION_PICK,然后指定保存路径,之后继续执行onActivityResult回调方法完成选择图片的功能。
获取到相册里的图片后,继续执行onActivityResult回调方法里裁剪图片的事件,完成后就访问接口,方法是PostFile(String imgPath),将获取到的图片上传到服务器端。
(2) 数据传输
本文图片文件上传与json格式数据获取采用okhttp网络请求框架,是一个效率非常高的 网络请求框架,它采用连接池降低了请求延迟,下载文件时采用GZIP 缩减了下载的大小,并且对于请求不成功的状态还支持请求的重传,支持异步的调用。
在方法PostFile(String imgPath)中调用okhttp请求框架,在请求体中封装要上传的图片内容,核心代码如下:
RequestBody body = new MultipartBuilder().addFormDataPart("file",imgPath ,
RequestBody.create(MediaType.parse("media/type"), new File(imgPath)))
.type(MultipartBuilder.FORM) .build();
设置传输格式为"media/type",然后将File传入请求体完成封装。然后通过execute()方法完成请求:
Response response = client.newCall(request).execute();
按照上文所描述,服务器会处理移动端的okhttp发送的网络请求,接收身份证图片进行下一步处理,等到处理后封装成json数据并返回结果体,然后okhttp通过接收体Response接收json数据:
String tempResponse = response.body().string();
JSONArray arr = new JSONArray(tempResponse);
String responsew = arr.getString(0);
JSONObject obj = new JSONObject(responsew);
通过方法将数据格式解析成格式,之后直接解析JSONObject里的数据,利用handler机制将数据更新到首页指定位置,具体实现效果如图所示:

图 返回数据并更新界面效果图
Android端源码已经上传至github: 链接
综上,完成了移动端获取身份证图像并上传图片,接收返回请求并更新界面等一系列操作。
五、总结
本文解决了在设计中遇到的诸多困难,比如:1)在模型的选择上,经过大量实验,最后选择了符合本系统的改进Lenet网络模型;2)在模型的训练上,由于考虑到获取大量身份证图片数据比较困难,所以训练模型采取对单个字符进行训练识别,通过Python将字体文件库转换成单个字符灰度图,共分6492类,放入11层改进Lenet模型进行训练3)对于身份证图片中的字符提取,首先利用水平和垂直投影法将字符定位,并切割,之后再将单独的每一个字符放入模型中进行识别,实验表明得到了较好的结果。
本文主要做的工作如下:1)首先提出了本文基于深度学习对身份证识别的研究意义,并介绍了深度学习发展的现状以及文字识别的研究进展;2)然后介绍了卷积神经网络、Lenet和Alexnet两种模型,以及字符切割等关键的技术3)然后获取数据训练集,在实验中选择并设计模型,配置Solver文件,把深层卷积神经网络模型进行训练,得出精度超过96%的模型4)之后进行系统设计开发,对身份证图像进行定位和切割,并放入模型中测试实验,得到较好的识别率;5)最后完成了android端程序的设计以及Flask服务器的搭建,并连通系统完成身份证图片信息识别的工作。
(完)
by still、
心有猛虎,细嗅蔷薇 转载请注明:https://www.cnblogs.com/ygh1229/
Caffe框架的基本操作和分析
深度学习实践系列之--身份证上汉字及数字识别系统的实现(上) |