0.本文目的
本篇文章将使用Keras搭建一个模型,达到了87%的准确率。代码已传到我的github ,欢迎star
1.数据准备
先下载以下两个文件,其中HWDB1.1trn_gnt是训练集,HWDB1.1tst_gnt是测试集
http://www.nlpr.ia.ac.cn/databases/download/feature_data/HWDB1.1trn_gnt.zip
http://www.nlpr.ia.ac.cn/databases/download/feature_data/HWDB1.1tst_gnt.zip
建议用迅雷等带断点续传的下载工具来下载,如果是在纯命令行没迅雷,也可以用wget下载,但是我个人在下载的时候,会出现断了重连然后下载回来的文件出错的情况。为了防止文件出错,请下载后sha-256校验一下:
第一个数据集的sha-256为:
1e00a630613cd796423710fc8b438e7176a4a8fef8dd25966f20940076dce817
第二个数据集的sha-256为:
1d5060803574ac10c743b12e621de3cbbfd1e95fe69426da570f492e5cd5ee08
如果你的sha256结果不一样,那肯定是下载出错了,建议重新下载。
2.数据加载与预处理
数据解码代码参考了这篇文章【1】 里的解码代码。先解压原始数据,得到HWDB1.1trn_gnt和HWDB1.1tst_gnt两个文件夹,然后下面代码能把这两个文件夹里的内容转换为png
import os
import numpy as np
import struct
from PIL import Image
data_dir = ''
train_data_dir = os . path . join ( data_dir , 'HWDB1.1trn_gnt' )
test_data_dir = os . path . join ( data_dir , 'HWDB1.1tst_gnt' )
def read_from_gnt_dir ( gnt_dir = train_data_dir ):
def one_file ( f ):
header_size = 10
while True :
header = np . fromfile ( f , dtype = 'uint8' , count = header_size )
if not header . size : break
sample_size = header [ 0 ] + ( header [ 1 ] << 8 ) + ( header [ 2 ] << 16 ) + ( header [ 3 ] << 24 )
tagcode = header [ 5 ] + ( header [ 4 ] << 8 )
width = header [ 6 ] + ( header [ 7 ] << 8 )
height = header [ 8 ] + ( header [ 9 ] << 8 )
if header_size + width * height != sample_size :
break
try :
image = np . fromfile ( f , dtype = 'uint8' , count = width * height ) . reshape (( height , width ))
except :
print struct . pack ( '>H' , tagcode ) . decode ( 'gb2312' )
# print image, tagcode
image = image . reshape ()
yield image , tagcode
for file_name in os . listdir ( gnt_dir ):
if file_name . endswith ( '.gnt' ):
file_path = os . path . join ( gnt_dir , file_name )
with open ( file_path , 'rb' ) as f :
for image , tagcode in one_file ( f ):
yield image , tagcode
char_set = set ()
for _ , tagcode in read_from_gnt_dir ( gnt_dir = train_data_dir ):
tagcode_unicode = struct . pack ( '>H' , tagcode ) . decode ( 'gb2312' )
char_set . add ( tagcode_unicode )
#save char list
char_list = list ( char_set )
char_dict = dict ( zip ( sorted ( char_list ), range ( len ( char_list ))))
print len ( char_dict )
import pickle
f = open ( 'char_dict' , 'wb' )
pickle . dump ( char_dict , f )
f . close ()
train_counter = 0
test_counter = 0
print 'start extracting training data'
for image , tagcode in read_from_gnt_dir ( gnt_dir = train_data_dir ):
tagcode_unicode = struct . pack ( '>H' , tagcode ) . decode ( 'gb2312' )
im = Image . fromarray ( image )
dir_name = './data/train/' + ' %0.5d ' % char_dict [ tagcode_unicode ]
if not os . path . exists ( dir_name ):
os . makedirs ( dir_name )
im . convert ( 'RGB' ) . save ( dir_name + '/' + str ( train_counter ) + '.png' )
train_counter += 1
print 'start extracting testing data'
for image , tagcode in read_from_gnt_dir ( gnt_dir = test_data_dir ):
tagcode_unicode = struct . pack ( '>H' , tagcode ) . decode ( 'gb2312' )
im = Image . fromarray ( image )
dir_name = './data/test/' + ' %0.5d ' % char_dict [ tagcode_unicode ]
if not os . path . exists ( dir_name ):
os . makedirs ( dir_name )
im . convert ( 'RGB' ) . save ( dir_name + '/' + str ( test_counter ) + '.png' )
test_counter += 1
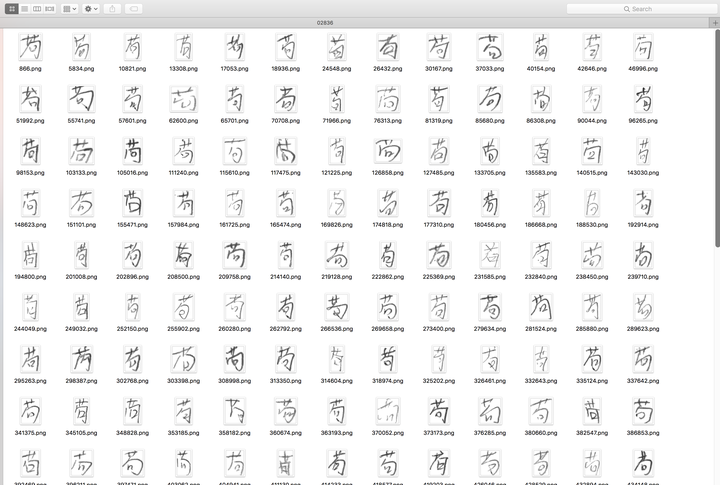
我把原始数据转成了png,而且也顺便看看数据集长啥样,转完后光训练数据集就有近90万张图片,选择了其中一个文件夹看了下
可以看到一个字有挺多文件的,每个图片都是不同笔迹的同一个字。
你问我为啥要选这个字来参考?我也母鸡啊,随手一点,就是这个字了,可能是缘分吧。反正,一月份枪毙清单已满,水表已拆,快递不收。
最后我还是没把原始数据转成png,而是直接读出来就开始使用了。毕竟读大量小文件比较耗时。
修改后的读取数据代码见【2】 :
至于预处理,我们还是要做的,看解码后的图片,发现他们分辨率不一样,有的长,有的宽,但都不会太夸张。所以我们统一把数据转成64x64,对输入(train X)的预处理如下
from PIL import Image
def read_convert_image ( self , image ):
im = Image . fromarray ( image )
im = im . resize ([ 64 , 64 ])
new_image = np . asarray ( im )
new_image = new_image . reshape ( new_image . shape [ 0 ], new_image . shape [ 1 ], 1 )
return new_image
模型的输出是一个类别。数据集有3755个常用汉字,我们输出的结果不能是一个数字,而应该输出每个汉字的概率,所以我们要把y,也就是类别,转成松散的(Sparse)表示, sklearn库提供LabelBinarizer,可以把输出转成sparse的表示:
from sklearn.preprocessing import LabelBinarizer
def generate_char_list ( self ):
if os . path . isfile ( 'char_list' ):
with open ( 'char_list' , 'rb' ) as f :
print 'char dict had been generated, just load'
char_list = pickle . load ( f )
return char_list
else :
char_list = []
for _ , tagcode in self . train . read_from_gnt_dir ( gnt_dir = 'HWDB1.1trn_gnt' ):
char_list . append ( tagcode )
with open ( 'char_list' , 'wb' ) as f :
pickle . dump ( char_list , f )
return char_list
lb = LabelBinarizer ()
lb . fit ( chars . generate_char_list ())
3.数据增强(data augmentation)
采用数据增强(data augmentation),可以活得更多时间。。。呸呸呸打错,是获得更多数据。该死的输入法,我打的是“huode gengduo sj”,况且是刚才尬膜了,不-1s已经不错了。
玩笑归玩笑,言归正传。常用的数据增强方法包括图像翻转,图像旋转,图像偏移,图像对比度变化,图像滤镜等等。
观察了下图像,发现有的写得歪,有的写得正;有的写得粗,有的写得细。所以我这里决定采用了图像旋转和图像滤镜。之所以不打算采用图像偏移和图像翻转,是因为这个数据集里的手写字体图片里面的文字都写得比较靠中间,偏移下未必好使;而且也没有人会写翻转的字,把文字翻转过来加入训练集,只会引入噪声,例如“人”字和“入”字,翻转就会出现严重的混淆问题,减弱训练结果。数据增强(data augmentation)核心代码非常简单,如下:
from PIL import Image
from PIL import ImageFilter
import PIL
def rotate ( self , image ):
im = Image . fromarray ( image )
im . rotate ( random . randint ( 1 , 15 )) # rotate slightly and randomly
im = im . resize ([ 64 , 64 ])
new_image = np . asarray ( im )
new_image = new_image . reshape ( new_image . shape [ 0 ], new_image . shape [ 1 ], 1 )
return new_image
def apply_filter ( self , image ):
im = Image . fromarray ( image )
filters = [ ImageFilter . BLUR , ImageFilter . CONTOUR , ImageFilter . EMBOSS ]
im . filter ( random . choice ( filters ))
im = im . resize ([ 64 , 64 ])
new_image = np . asarray ( im )
new_image = new_image . reshape ( new_image . shape [ 0 ], new_image . shape [ 1 ], 1 )
return new_image
4.搭建模型
用了四个卷积层,两个maxpooling层。keras的模型接口是高层次的抽象,直接创建一个sequential,然后一直add layer,最后加个softmax来输出。softmax的输出是每个类别的可能性,softmax各项加起来结果是1。例如有三个类,softmax输出是[0.9,0.09.0.01],则预测结果是第一个类。
def build_model ():
model = Sequential ()
model . add ( Conv2D ( 128 , ( 3 , 3 ), input_shape = ( 64 , 64 , 1 )))
model . add ( BatchNormalization ( axis =- 1 ))
model . add ( Activation ( 'relu' ))
model . add ( Conv2D ( 64 , ( 3 , 3 )))
model . add ( BatchNormalization ( axis =- 1 ))
model . add ( Activation ( 'relu' ))
model . add ( MaxPooling2D ( pool_size = ( 2 , 2 )))
model . add ( Conv2D ( 64 , ( 3 , 3 )))
model . add ( BatchNormalization ( axis =- 1 ))
model . add ( Activation ( 'relu' ))
model . add ( Conv2D ( 64 , ( 3 , 3 )))
model . add ( BatchNormalization ( axis =- 1 ))
model . add ( Activation ( 'relu' ))
model . add ( MaxPooling2D ( pool_size = ( 2 , 2 )))
model . add ( Flatten ())
# Fully connected layer
model . add ( Dense ( 1024 ))
model . add ( BatchNormalization ())
model . add ( Activation ( 'relu' ))
model . add ( Dropout ( 0.4 ))
model . add ( Dense ( 3755 ))
model . add ( Activation ( 'softmax' ))
return model
5.训练
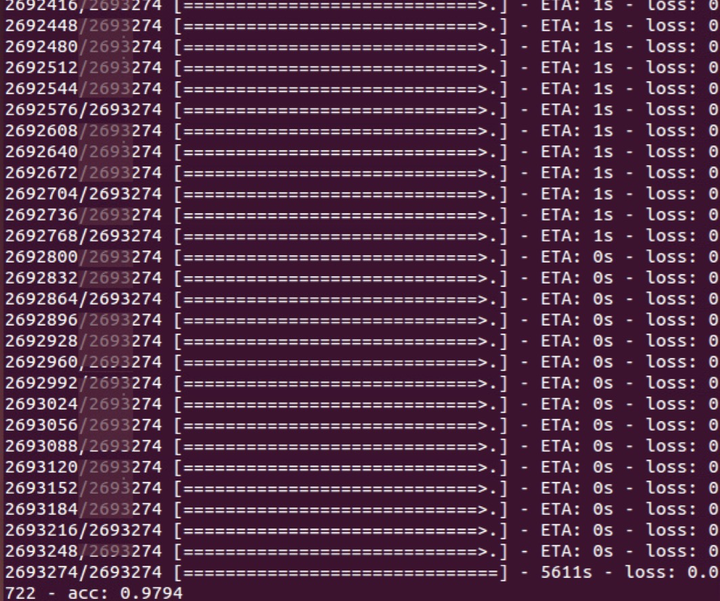
训练好后,模型在训练集上准确率为97.9%,wow, impressive. 但测试结果如何呢?
6.测试
测试准确率要比训练准确率低,只有87.5%。其实最开始时只有80%不到,我增加了第一个卷积层的filter数量(从原先的64增加到128),同时增加dropout rate,但目前模型已经足够复杂了,dropout层的参数也够大了。如果读者有什么好的想法,欢迎测试下并告知我结果。
7.结论与展望
本文实现了一个卷积神经网络模型,达到了87.57%的准确率。代码已传到我的github
orange90/HandWrittenChineseRecogntion
本文还可以尝试以下研究方向,有兴趣的读者可以研究下。
用grid search来寻找最佳dropout率。但目前每次训练都要20小时,这个事情我就不做了。
这个数据集是一级常用汉字,一共3755个。可以把二级常用汉字的也加进来一起训练。
记得大学思修考试可以带手写版笔记考试,但不允许带打印版,但用手写字体打印出来的话,同一个字体写法完全一样,不完美。利用GAN生成手写字体,用这个方法就可以伪造手写版啦。
文中引用
【1】【2】https:// github.com/orange90/Han dWrittenChineseRecogntion/blob/master/fast_read_data.py