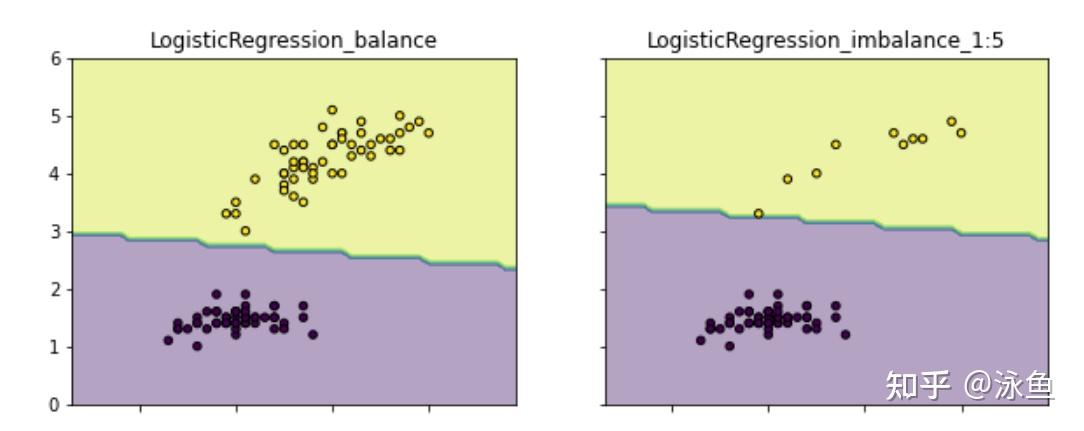
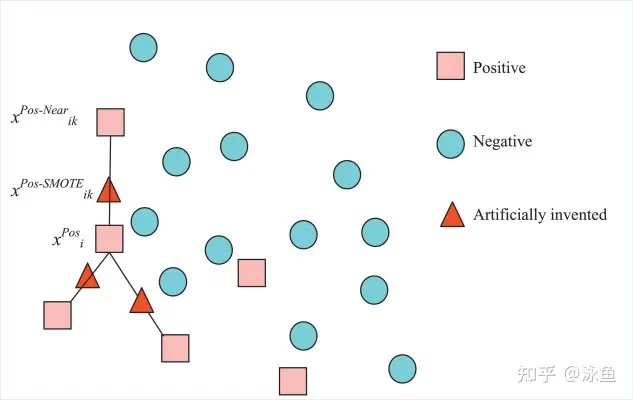
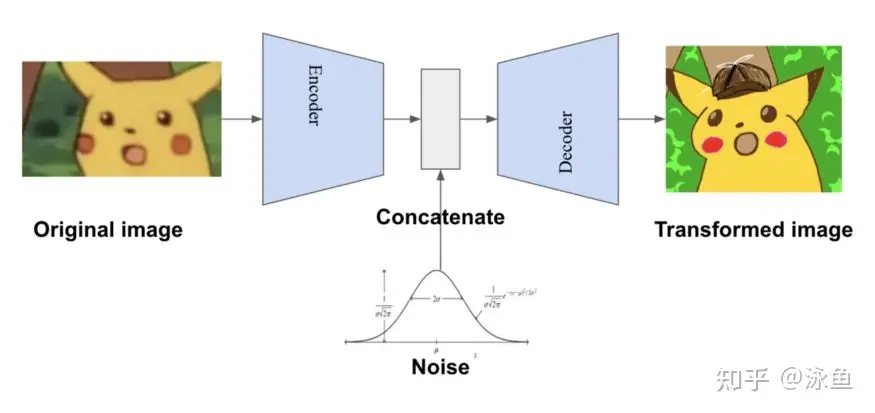
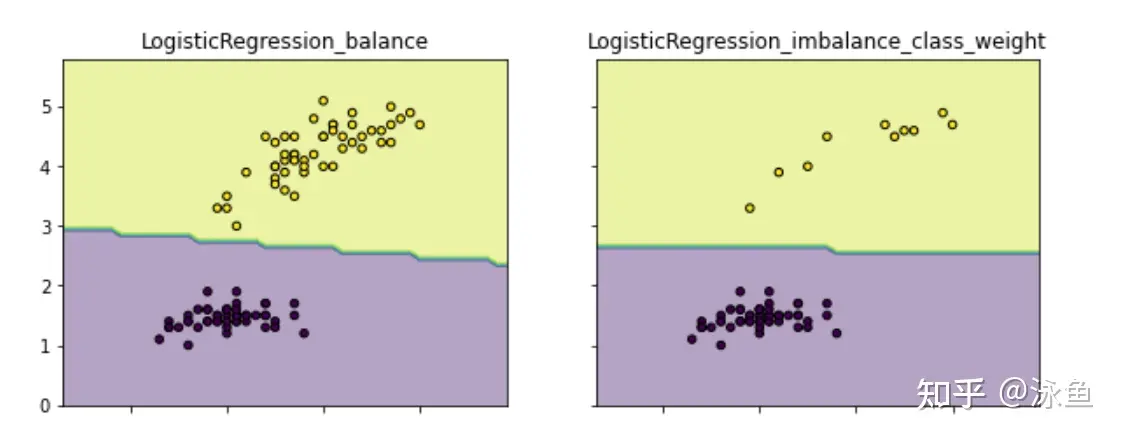
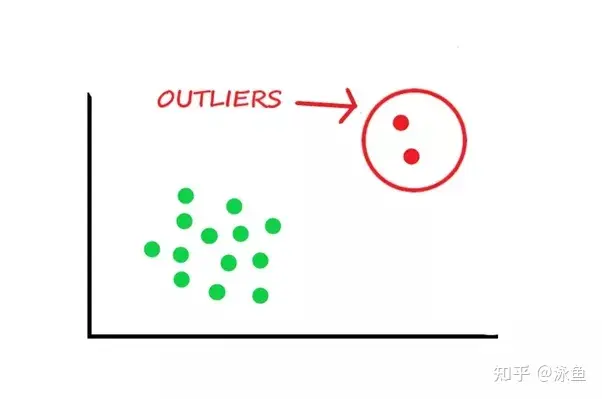
这最常用也就是scikit模型的’class weight‘方法,If ‘balanced’, class weights will be given by n_samples / (n_classes * np.bincount(y)). If a dictionary is given, keys are classes and values are corresponding class weights. If None is given, the class weights will be uniform.,class weight可以为不同类别的样本提供不同的权重(少数类有更高的权重),从而模型可以平衡各类别的学习。 如下图(具体代码请见github.com/aialgorithm)通过为少数类做更高的权重(类别权重除了设定为balanced,还可以作为一个超参搜索),避免决策边界偏重多数类的现象:
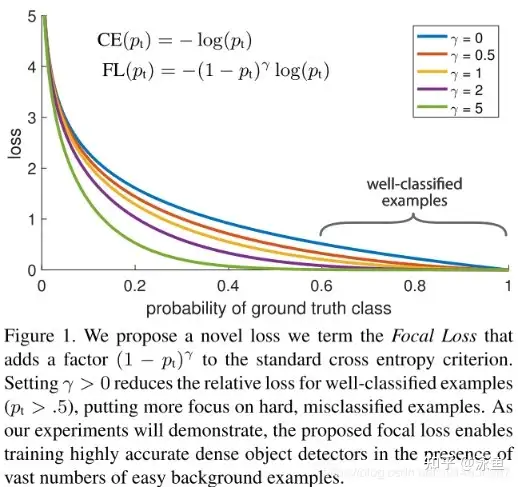
In this work, we first point out that the class imbalance can be summarized to the imbalance in difficulty and the imbalance in difficulty can be summarized to the imbalance in gradient norm distribution.--原文可见《Gradient Harmonized Single-stage Detector 》