这篇教程深度学习中的批标准化(batch normalization)写得很实用,希望能帮到您。
一.概述
1.为什么需要BN
我们知道网络一旦train起来,那么参数就要发生更新,除了输入层的数据外(因为输入层数据,我们已经人为的为每个样本归一化),后面网络每一层的输入数据分布是一直在发生变化的,因为在训练的时候,前面层训练参数的更新将导致后面层输入数据分布的变化。以网络第二层为例:网络的第二层输入,是由第一层的参数和input计算得到的,而第一层的参数在整个训练过程中一直在变化,因此必然会引起后面每一层输入数据分布的改变。我们把网络中间层在训练过程中,数据分布的改变称之为:“Internal Covariate Shift”。BN的提出,就是要解决在训练过程中,中间层数据分布发生改变的情况。
2.作用:
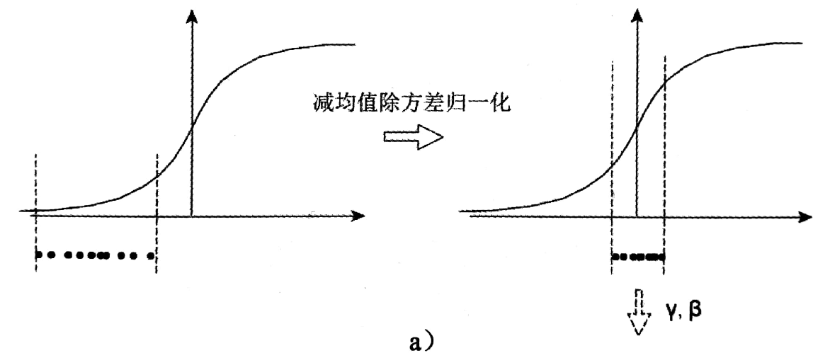

a中左图是没有经过任何处理的输入数据,曲线是sigmoid函数,如果数据在梯度很小的区域,那么学习率就会很慢甚至陷入长时间的停滞。减均值除方差后,数据就被移到中心区域如右图所示,对于大多数激活函数而言,这个区域的梯度都是最大的或者是有梯度的(比如ReLU),这可以看做是一种对抗梯度消失的有效手段。对于一层如此,如果对于每一层数据都那么做的话,数据的分布总是在随着变化敏感的区域,相当于不用考虑数据分布变化了,这样训练起来更有效率。
那么为什么要有第4步,不是仅使用减均值除方差操作就能获得目的效果吗?我们思考一个问题,减均值除方差得到的分布是正态分布,我们能否认为正态分布就是最好或最能体现我们训练样本的特征分布呢?不能,比如数据本身就很不对称,或者激活函数未必是对方差为1的数据最好的效果,比如Sigmoid激活函数,在-1~1之间的梯度变化不大,那么非线性变换的作用就不能很好的体现,换言之就是,减均值除方差操作后可能会削弱网络的性能!针对该情况,在前面三步之后加入第4步完成真正的batch normalization。
BN的本质就是利用优化变一下方差大小和均值位置,使得新的分布更切合数据的真实分布,保证模型的非线性表达能力。BN的极端的情况就是这两个参数等于mini-batch的均值和方差,那么经过batch normalization之后的数据和输入完全一样,当然一般的情况是不同的。
对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。
因为梯度一直都能保持比较大的状态,所以很明显对神经网络的参数调整效率比较高,就是变动大,就是说向损失函数最优值迈动的步子大,也就是说收敛地快。
经过BN后,大部分Activation的值落入非线性函数的线性区内,其对应的导数远离导数饱和区,这样来加速训练收敛过程。
BN在深层神经网络的作用非常明显:若神经网络训练时遇到收敛速度较慢,或者“梯度爆炸”等无法训练的情况发生时都可以尝试用BN来解决。同时,常规使用情况下同样可以加入BN来加速模型训练,甚至提升模型精度。
有轻微正则化的作用,因为BN对隐藏单元施加了噪音。
二.实现

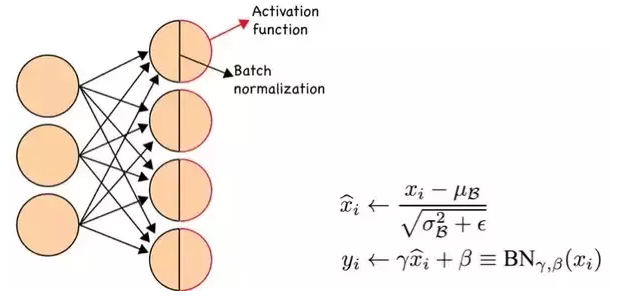
对于每一个mini-batch做BN:

如上图所示,BN步骤主要分为4步:
- 求每一个训练批次数据的均值
- 求每一个训练批次数据的方差
- 使用求得的均值和方差对该批次的训练数据做归一化,获得0-1分布。其中εε是为了避免除数为0时所使用的微小正数。
- 尺度变换和偏移:将xi乘以γ调整数值大小,再加上β增加偏移后得到yi,这里的γ是尺度因子,β是平移因子。这一步是BN的精髓,由于归一化后的xi基本会被限制在正态分布下,使得网络的表达能力下降。为解决该问题,我们引入两个新的参数:γ,β。 γ和β是在训练时网络自己学习得到的。
三.预测过程
在训练时,我们会对同一批的数据的均值和方差进行求解,进而进行归一化操作。但是对于预测时我们的均值和方差怎么求呢?比如我们预测单个样本时,那还怎么求均值和方法呀!其实是这种样子的,对于预测阶段时所使用的均值和方差,其实也是来源于训练集。比如我们在模型训练时我们就记录下每个batch下的均值和方差,待训练完毕后,我们求整个训练样本的均值和方差期望值,作为我们进行预测时进行BN的的均值和方差:

最后测试阶段,BN的使用公式就是:
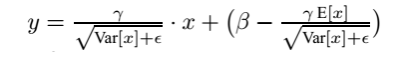
四.补充说明
关于BN的使用位置,在CNN中一般应作用与非线性激活函数之前,s型函数s(x)的自变量x是经过BN处理后的结果。因此前向传导的计算公式就应该是:

其实因为偏置参数b经过BN层后其实是没有用的,最后也会被均值归一化,当然BN层后面还有个β参数作为偏置项,所以b这个参数就可以不用了。因此最后把BN层+激活函数层就变成了:

vgg16模型参数量和使用的的内存计算
标准卷积和深度可分离卷积以及Inception系列 |