ХвЖӘҪМіМ¶ю·ЦАаОКМвөДҪ»ІжмШЛрК§әҜКэ¶а·ЦАаөДОКМвөДәҜКэҪ»ІжмШЛрК§әҜКэЗуҪвРҙөГәЬКөУГЈ¬ПЈНыДЬ°пөҪДъЎЈ
¶ю·ЦАаОКМвөДҪ»ІжмШЛрК§әҜКэ;
ФЪ¶ю·ЦАаОКМвЦРЈ¬ЛрК§әҜКэОӘҪ»ІжмШЛрК§әҜКэЎЈ¶ФУЪСщұҫЈЁx,yЈ©АҙҪІЈ¬xОӘСщұҫ yОӘ¶ФУҰөДұкЗ©ЎЈФЪ¶ю·ЦАаОКМвЦРЈ¬ЖдИЎЦөөДјҜәПҝЙДЬОӘ{0Ј¬1}Ј¬ОТГЗјЩЙиДіёцСщұҫөДХжКөұкЗ©ОӘytЈ¬ёГСщұҫөДyt=1өДёЕВКОӘypЈ¬ФтёГСщұҫөДЛрК§әҜКэОӘЈә

Из№ы¶ФУЪХыёцКэҫЭјҜЙПөДДЈРН¶шСФЈәЖдЛрК§әҜКэҫНКЗЛщУРСщұҫөДөгөДЛрК§әҜКэөДЖҪҫщЦөЎЈ
¶а·ЦАаөДОКМвөДәҜКэҪ»ІжмШЛрК§әҜКэЈә
ФЪ¶а·ЦАаОКМвЦРЈ¬ЛрК§әҜКэТІКЗҪ»ІжмШЛрК§әҜКэЈ¬¶ФУЪСщұҫЈЁx,yЈ©АҙҪІЈ¬yКЗХжКөөДұкЗ©Ј¬ФӨІвұкЗ©ОӘЛщУРұкЗ©өДјҜәПЈ¬ОТГЗјЩЙиУРkёцұкЗ©ЦөЈ¬өЪiёцСщұҫФӨІвОӘөЪKёцұкЗ©өДёЕВКОӘpi,kЈ¬Т»№ІУРNёцСщұҫЈ¬ФтЧЬөДКэҫЭјҜЛрК§әҜКэОӘЈә
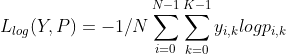
ПВГжКЗ¶ю·ЦАаәН¶а·ЦАаОКМвөДҙъВлЈәАыУГsklearnҝвұаРҙ
from sklearn.metrics import log_loss
#from sklearn.preprocessing import LabelBinarizer
from math import log
y_true = [0,1]
y_pred = [[.48,.52],[.48,.52]]
sk_log_loss = log_loss(y_true,y_pred)
print('Loss by sklearn: %s.'% sk_log_loss)
loss = 0
for lable,prob in zip(y_true,y_pred):
loss -= (lable * log(prob[0])+(1-lable)*log(1-prob[1]))
loss = loss/len(y_true)
print('loss by equation: %s.'%loss)
from sklearn.metrics import log_lossfrom math import log -
-
y_true = [0,0,1,1]y_pred = [[.9,.1],[.8,.2],[.2,.8],[.3,.7]]sk_log_loss = log_loss(y_true,y_pred)print('Loss by sklearn: %s.'% sk_log_loss)-
loss = 0for lable,prob in zip(y_true,y_pred)Loss -= (lable * log(prob[0])+(1-lable)*log(1-prob[1]))Loss = Loss/len(y_true)print('Loss by equation: %s.'%Loss)
from sklearn.metrics import log_lossfrom sklearn.preprocessing import LabelBinarizerfrom math import log-
y_true = ['1', '4', '5'] # СщұҫөДХжКөұкЗ©y_pred = [[0.1, 0.6, 0.3, 0, 0, 0, 0, 0, 0, 0],[0, 0.3, 0.2, 0, 0.5, 0, 0, 0, 0, 0],[0.6, 0.3, 0, 0, 0, 0.1, 0, 0, 0, 0]] # СщұҫөДФӨІвёЕВКlabels = ['0','1','2','3','4','5','6','7','8','9'] # ЛщУРұкЗ©-
-
# АыУГsklearnЦРөДlog_loss()әҜКэјЖЛгҪ»ІжмШsk_log_loss = log_loss(y_true, y_pred, labels=labels)print("Loss by sklearn is:%s." %sk_log_loss)-
# ¶ФСщұҫөДХжКөұкЗ©ҪшРРұкЗ©¶юЦө»Ҝlb = LabelBinarizer()print(lb.fit(labels))transformed_labels = lb.transform(y_true)print(transformed_labels)#ЧӘ»ҜҙъВлОӘҫШХу-
N = len(y_true) # СщұҫёцКэK = len(labels) # ұкЗ©ёцКэ-
eps = 1e-15 # ФӨІвёЕВКөДҝШЦЖЦөLoss = 0 # ЛрК§ЦөіхКј»Ҝ-
for i in range(N):for k in range(K):# ҝШЦЖФӨІвёЕВКФЪ[eps, 1-eps]ДЪЈ¬ұЬГвЗу¶ФКэКұіцПЦОКМвif y_pred[i][k] < eps:y_pred[i][k] = epsif y_pred[i][k] > 1-eps:y_pred[i][k] = 1-eps# ¶а·ЦАаОКМвөДҪ»ІжмШјЖЛ㹫КҪLoss -= transformed_labels[i][k]*log(y_pred[i][k])-
Loss /= Nprint("Loss by equation is:%s." % Loss)
Softmax»ъЖчС§П°ЦШТӘөД№ӨҫЯПкПёНЖөј№«КҪәНКөПЦҙъВл
Йо¶ИС§П°ЧсСӯЎ°А¬»шИлЈ¬А¬»шіцЎұЈЁЎ°garbage in, garbage outЎұЈ©өД»щұҫ·ЁФтAndrej Karpathy ФЪTrain AI СЭҪІ:ёДЙЖКэҫЭјҜ |