这篇教程为什么研究轻量级深度学习网络模型写得很实用,希望能帮到您。
计算机视觉领域内的卷积神经网络模型也层出不穷。从1998年的LeNet,到2012年引爆深度学习热潮的AlexNet,再到后来2014年的VGG,2015年的ResNet,深度学习网络模型在图像处理中应用的效果越来越好。神经网络体积越来越大,结构越来越复杂,预测和训练需要的硬件资源也逐步增多,往往只能在高算力的服务器中运行深度学习神经网络模型。移动设备因硬件资源和算力的限制,很难运行复杂的深度学习网络模型。
从MobileNet看轻量级神经网络的发展
深度学习领域内也在努力促使神经网络向小型化发展。在保证模型准确率的同时体积更小,速度更快。到了2016年直至现在,业内提出了SqueezeNet、ShuffleNet、NasNet、MnasNet以及MobileNet等轻量级网络模型。这些模型使移动终端、嵌入式设备运行神经网络模型成为可能。而MobileNet在轻量级神经网络中较具代表性。
谷歌在2019年5月份推出了最新的MobileNetV3。新版MobileNet使用了更多新特性,使得MobileNet非常具有研究和分析意义,本文将对MobileNet进行详细解析。
MobileNet的优势
MobileNet网络拥有更小的体积,更少的计算量,更高的精度。在轻量级神经网络中拥有极大的优势。
1、更小的体积
从MobileNet看轻量级神经网络的发展
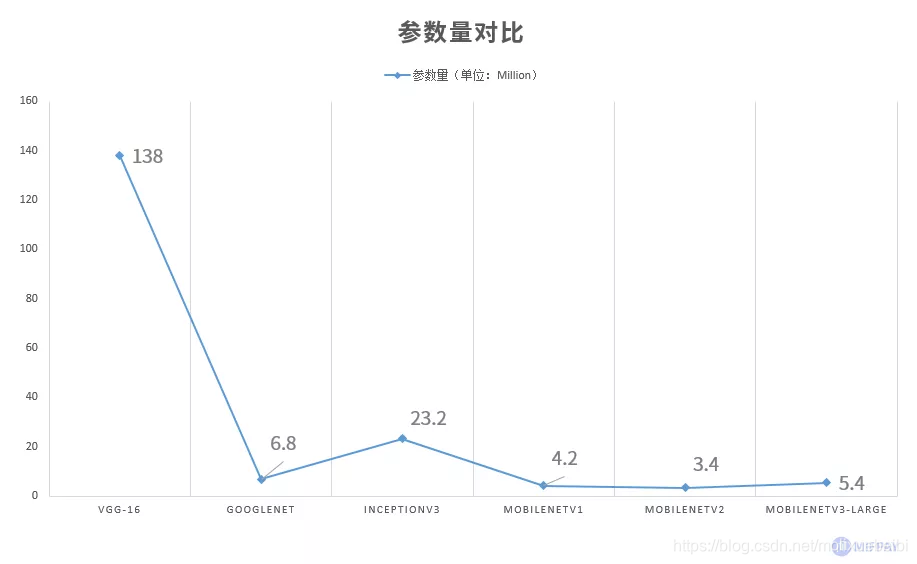
MobileNet相比经典的大型网络,参数量明显更少,参数量越少模型体积越小。
2、更少的计算量
从MobileNet看轻量级神经网络的发展
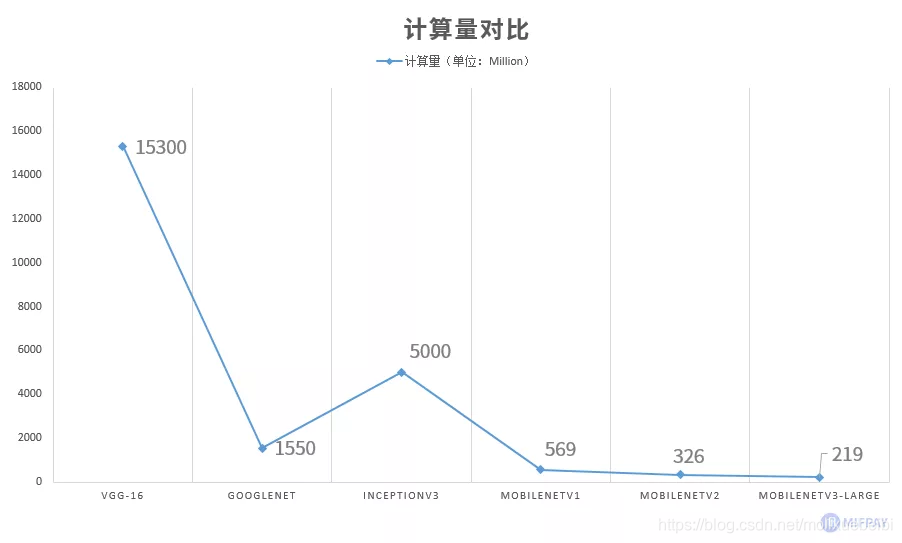
MobileNet优化网络结构使模型计算量成倍下降。
3、更高的准确率
从MobileNet看轻量级神经网络的发展
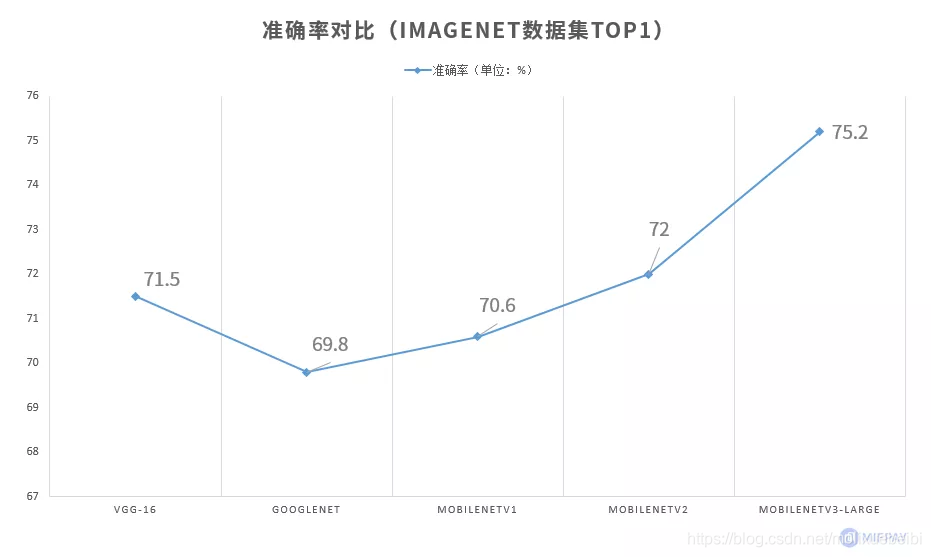
MobileNet凭借网络结构优化,在更少的参数及更少的计算量情况下,网络精度反而超过了部分大型神经网络。在最新的MobileNetV3-Large中,实现ImageNet数据集Top1准确率达到75.2%。
4、更快的速度
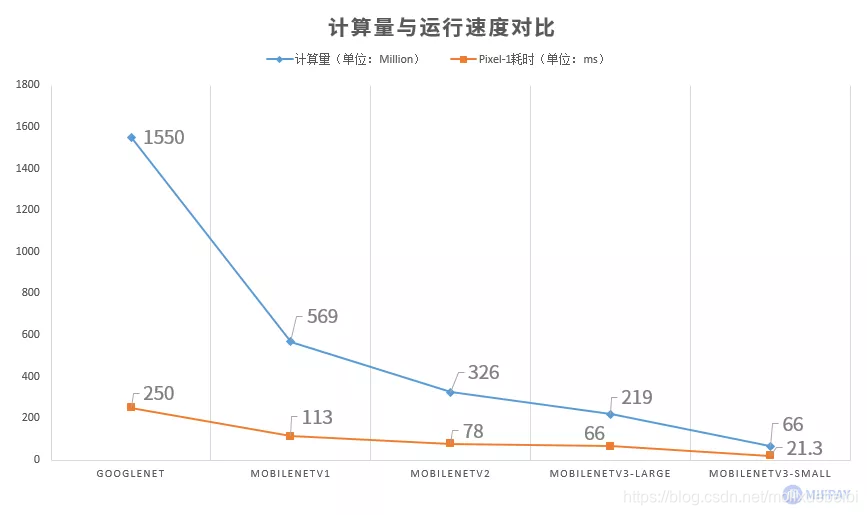
从MobileNet看轻量级神经网络的发展
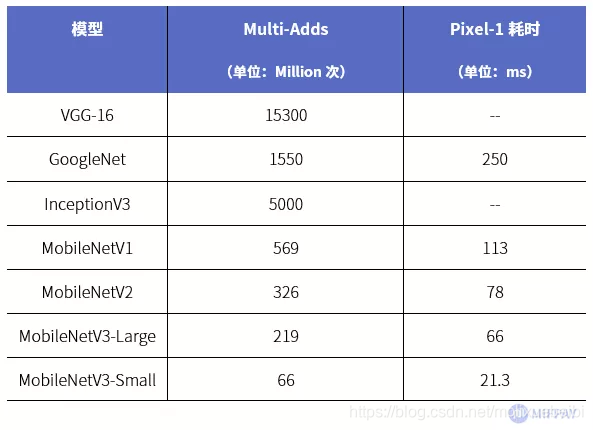
使用Google Pixel-1手机测试,MobileNet各版本都能保持运行时间在120ms以下,最新版MobileNetV3-Large运行时间达到66ms,参数量和计算量更低的MobileNetV3-Small更是能达到22ms;GoogleNet运行速度约为250ms,而VGG-16由于一次性需要加载至内存的空间已超过500MB,手机系统会报内存溢出错误导致无法运行。
5、多种应用场景
MobileNet可以在移动终端实现众多的应用,包括目标检测,目标分类,人脸属性识别和人脸识别等。

从MobileNet看轻量级神经网络的发展
MobileNet各版本介绍
1、MobileNetV1网络结构

从MobileNet看轻量级神经网络的发展
整个网络不算平均池化层与softmax层,共28层;
在整个网络结构中步长为2的卷积较有特点,卷积的同时充当下采样的功能;
第一层之后的26层都为深度可分离卷积的重复卷积操作;
每一个卷积层(含常规卷积、深度卷积、逐点卷积)之后都紧跟着批规范化和ReLU激活函数;
最后一层全连接层不使用激活函数。
2、MobileNetV2网络结构

从MobileNet看轻量级神经网络的发展
MobileNetV2中主要引入线性瓶颈结构和反向残差结构。
MobileNetV2网络模型中有共有17个Bottleneck层(每个Bottleneck包含两个逐点卷积层和一个深度卷积层),一个标准卷积层(conv),两个逐点卷积层(pw conv),共计有54层可训练参数层。MobileNetV2中使用线性瓶颈(Linear Bottleneck)和反向残差(Inverted Residuals)结构优化了网络,使得网络层次更深了,但是模型体积更小,速度更快了。
3、MobileNetV3网络结构

从MobileNet看轻量级神经网络的发展
MobileNetV3分为Large和Small两个版本,Large版本适用于计算和存储性能较高的平台,Small版本适用于硬件性能较低的平台。
Large版本共有15个bottleneck层,一个标准卷积层,三个逐点卷积层。
Small版本共有12个bottleneck层,一个标准卷积层,两个逐点卷积层。
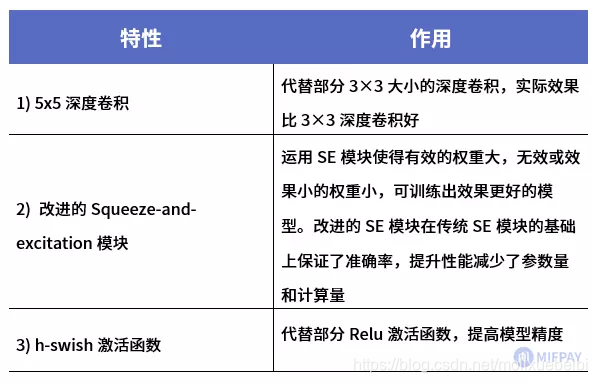
MobileNetV3中引入了5×5大小的深度卷积代替部分3×3的深度卷积。引入Squeeze-and-excitation(SE)模块和h-swish(HS)激活函数以提高模型精度。结尾两层逐点卷积不使用批规范化(Batch Norm),MobileNetV3结构图中使用NBN标识。
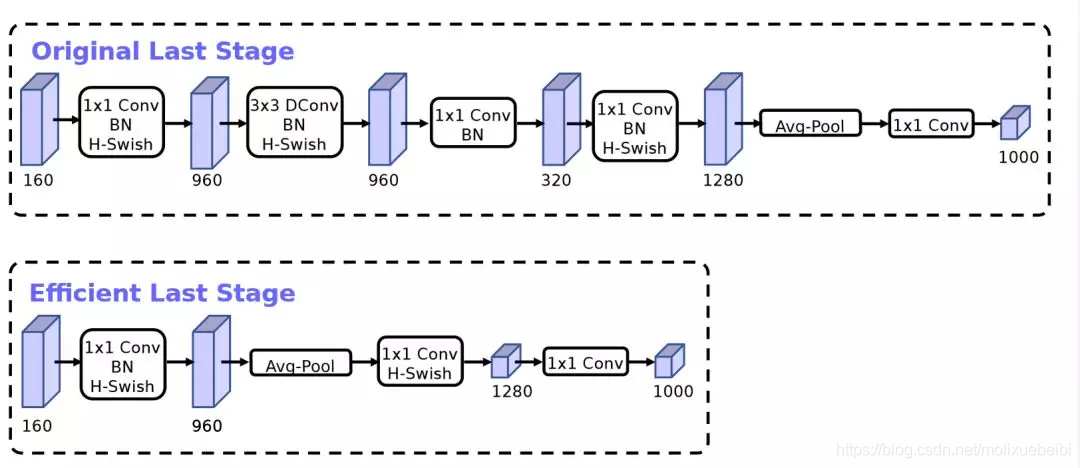
从MobileNet看轻量级神经网络的发展
(图片来源https://arxiv.org/pdf/1905.02244.pdf)
网络结构上相对于MobileNetV2的结尾部分做了优化,去除三个高阶层,如上图所示。去除后减少了计算量和参数量,但是模型的精度并没有损失。
值得一提的是,不论是Large还是Small版本,都是使用神经架构搜索(NAS)技术生成的网络结构。
4、MobileNet各版本特性
MobileNet实现计算量减小、参数量减少的同时保证了较高的准确率,这和其拥有的特性息息相关:
MobileNetV1提出的特性
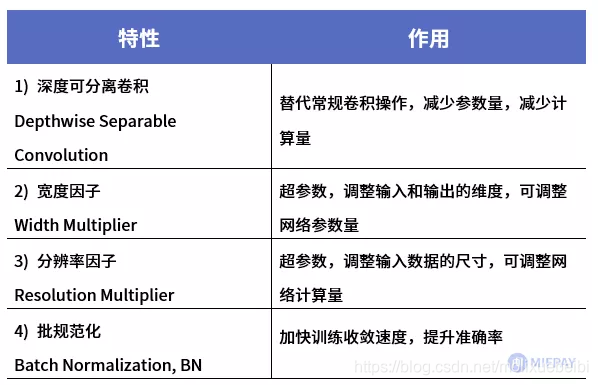
从MobileNet看轻量级神经网络的发展
MobileNetV2提出的特性
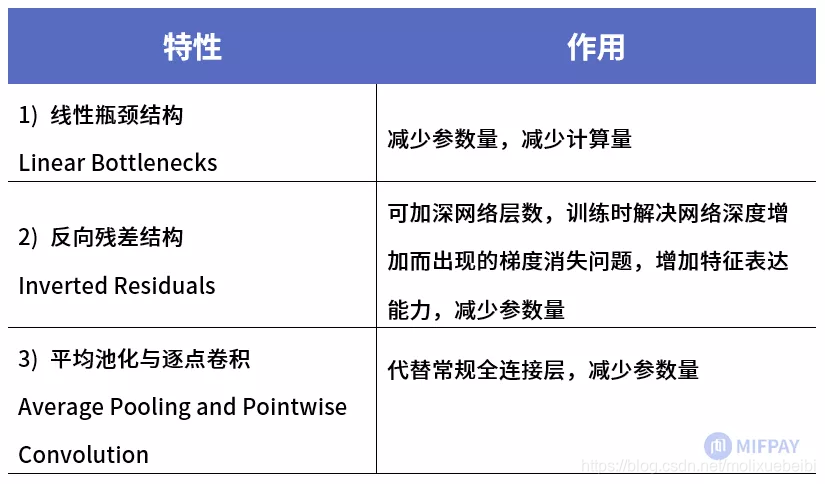
从MobileNet看轻量级神经网络的发展
MobileNetV3提出的特性
从MobileNet看轻量级神经网络的发展
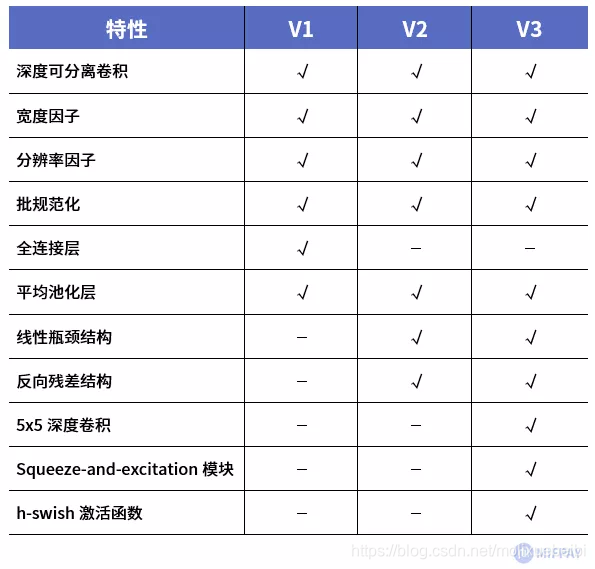
MobileNet各个版本拥有的特性汇总
从MobileNet看轻量级神经网络的发展
下文将对上表中的各个特性详细阐述。
MobileNet的特性详解
1、深度可分离卷积
从MobileNetV1开始,到V2、V3的线性瓶颈结构都大量使用了深度可分离卷积。
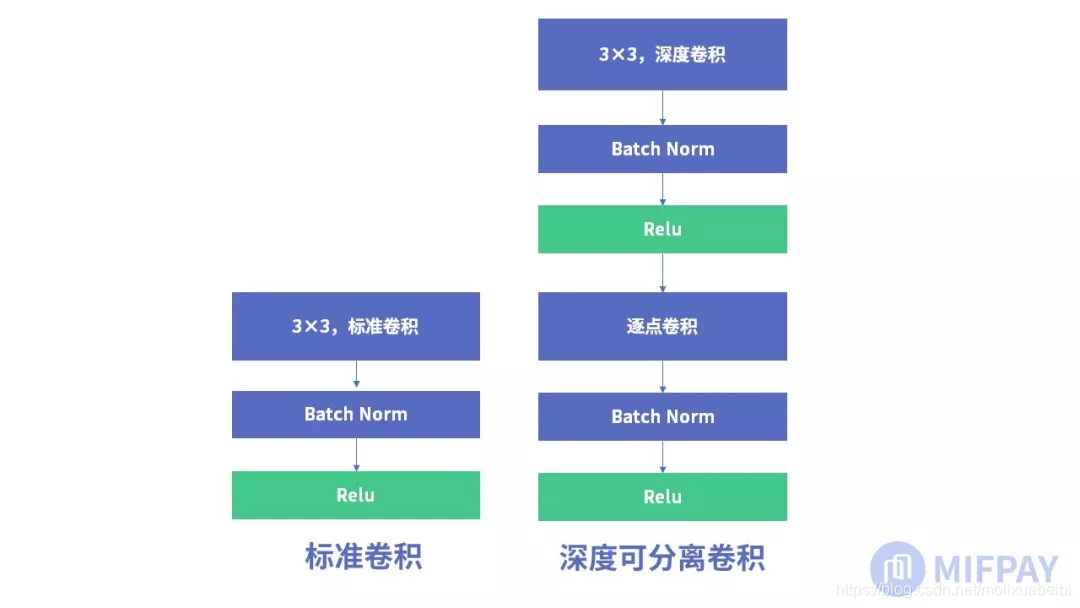
深度可分离卷积(Depthwise Separable Convolution)是一种卷积结构。它是由一层深度卷积(Depthwise convolution)与一层逐点卷积(Pointwise Convolution)组合而成的,每一层卷积之后都紧跟着批规范化和ReLU激活函数。跟标准卷积的区别就是精度基本不变的情况下,参数与计算量都明显减少。
从MobileNet看轻量级神经网络的发展
深度卷积
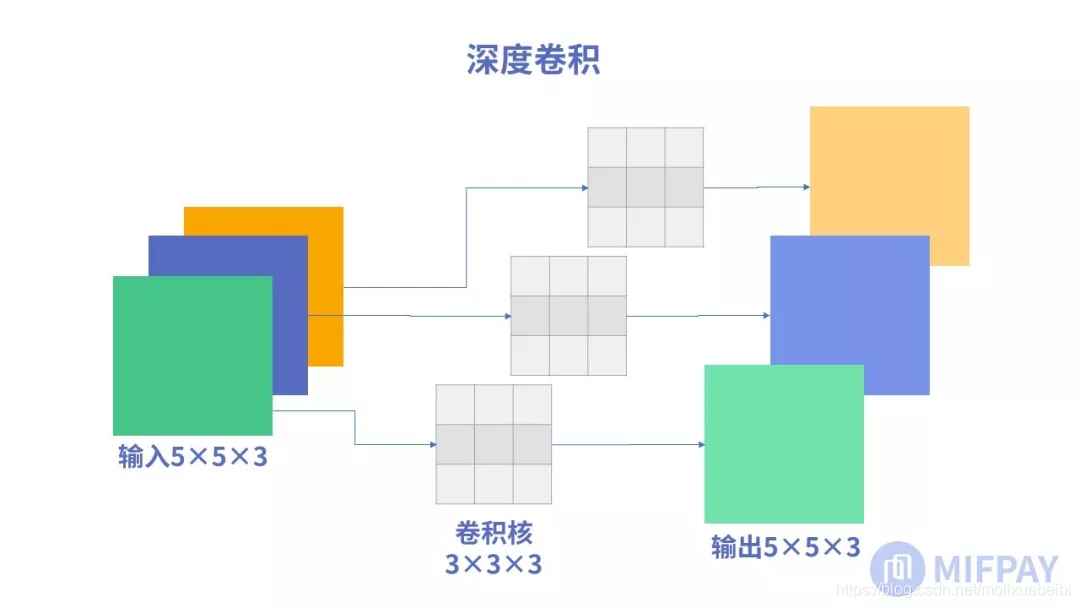
深度卷积(Depthwise convolution, DW)不同于常规卷积操作,深度卷积中一个卷积核只有一维,负责一个通道,一个通道只被一个卷积核卷积;常规卷积每个卷积核的维度与输入维度相同,每个通道单独做卷积运算后相加。
以一张5x5x3(长和宽为5,RGB3通道)的彩色图片举例。每层深度卷积卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。设padding=1,stride=1,一个三通道的图像经过运算后生成了3个特征图,如下图所示:
从MobileNet看轻量级神经网络的发展
深度卷积完成后的输出特征图通道数与输入层的通道数相同,无法扩展通道数。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的特征信息。因此需要逐点卷积来将生成的特征图进行组合生成新的特征图。
逐点卷积
逐点卷积(Pointwise Convolution, PW)的运算与标准卷积运算非常相似。
逐点卷积卷积核大小为1×1xM(M为输入数据的维度),每次卷积一个像素的区域。逐点卷积运算会将上一层的特征图在深度方向上进行加权组合,生成新的特征图,新的特征图的大小与输入数据大小一致;然后组合各通道的特征图,以较少的计算量进行降维或升维操作(改变输出数据的维度)。
以一张5x5x3(长和宽为5,RGB3通道)的彩色图片举例,使用4个1x1x3的逐点卷积核进行卷积,逐点卷积运算后生成了4个特征图。这个例子是使用逐点卷积进行升维的操作,特征图从5x5x3 升维到5x5x4。如下图所示:
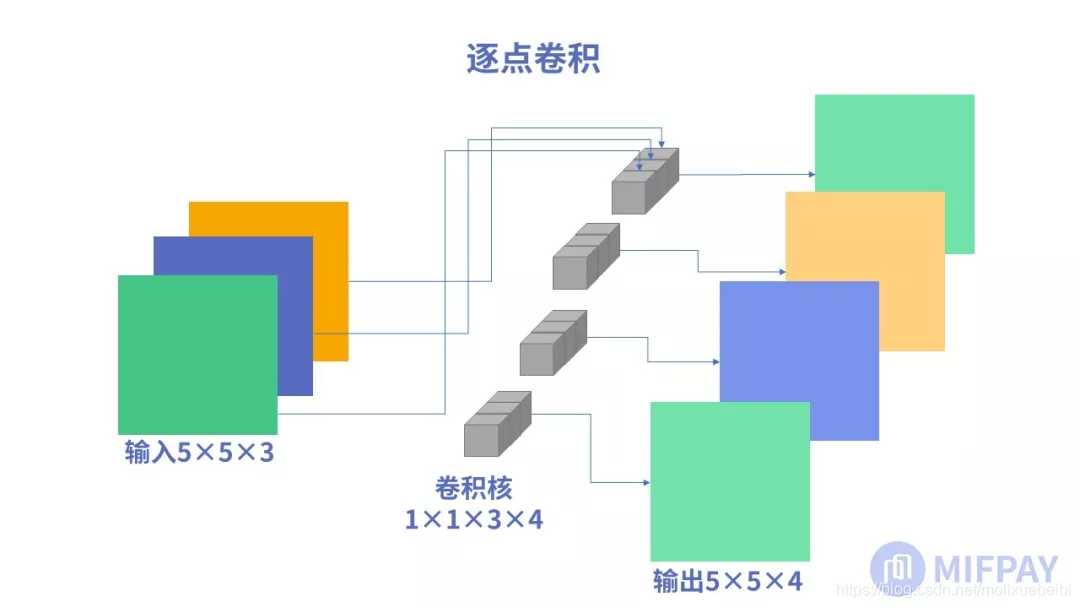
从MobileNet看轻量级神经网络的发展
深度可分离卷积结构解析
将深度卷积和逐点卷积组成深度可分离卷积后的示意图,如下图所示:
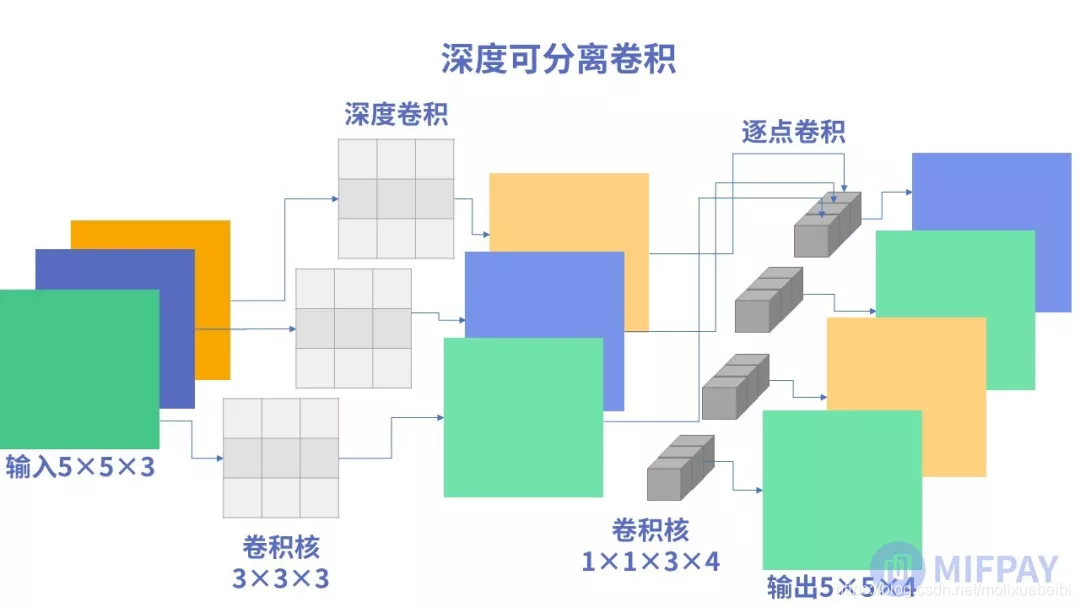
从MobileNet看轻量级神经网络的发展
首先进行深度卷积操作,得出的特征图各通道之间是不关联的。接着进行逐点卷积把深度卷积输出的特征图各通道关联起来。
深度可分离卷积使用了更小的空间代价(参数减少)和更少的时间代价(计算量更少)实现了标准卷积层一样的效果(提取特征)。
一般的设Df为输入特征图边长,Dk为卷积核边长,特征图和卷积核均为长宽一致,输入通道数为M,输出通道数为N,则:
标准卷积计算量为:Df×Df×Dk×Dk×M×N
深度卷积的计算量为:Df×Df×Dk×Dk×M
逐点卷积的计算量为:Df×Df×M×N
上图所示实现输入特征图大小为5×5×3,输出特成图大小为5×5×4,设padding=1,stride=1,深度卷积卷积核大小为3×3,标准卷积也使用3×3尺寸卷积核。实现相同的卷积效果,参数量(不包含偏置)与计算量对比如下表所示:
从MobileNet看轻量级神经网络的发展

深度可分离卷积的演变
事实上深度可分离卷积不是在MobileNetV1中第一次提出的,而是在2016年由谷歌的Xception网络结构中提出的。MobileNetV1在Xception的基础上,对深度可分离卷积进行了改进,做到了计算量与参数量的下降:
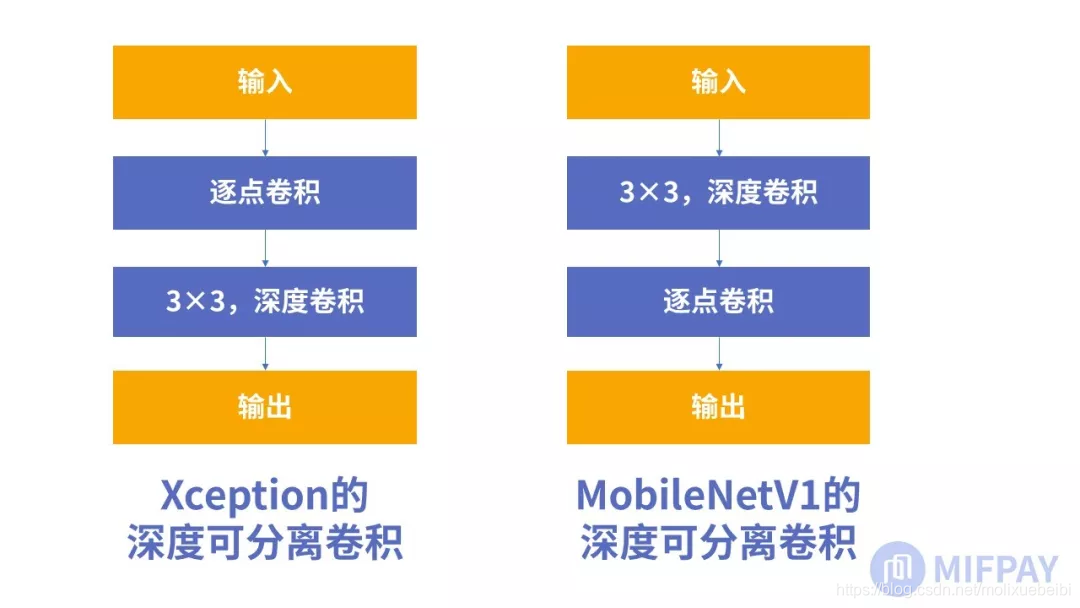
假定M为输入层的通道数,N为输出层的通道数。
Xcenption的深度可分离卷积是由输入参数开始,使用1x1xMxN卷积将输入层的通道数转换为目标通道数,再通过3x3x1卷积核对每个通道进行卷积,每次卷积过后使用ReLU进行激活。
MobileNetV1的深度可分离卷积则是先使用3x3x1xM对输入层的每个通道分别卷积,之后通过1x1xMxN将输入层通道数转换为输出层通道数,每次卷积过后做一次批规范化操作,再使用ReLU进行激活。
这里我们使用MobileNetV1网络结构的第一个深度可分离卷积层来举例,输入层维度为112x112x32,输出层维度为112x112x64,Xception与MobileNet的深度可分离卷积的计算量与参数个数对比如下表:
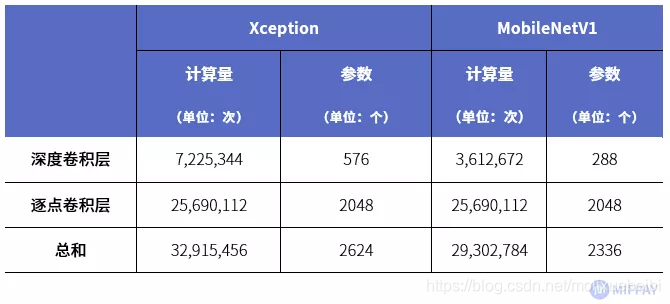
从MobileNet看轻量级神经网络的发展
由此可知将PW卷积与DW卷积的顺序调整后,优化了网络的空间复杂度和时间复杂度。
2、宽度因子
MobileNet本身的网络结构已经比较小并且执行延迟较低,但为了适配更定制化的场景,MobileNet提供了称为宽度因子(Width Multiplier)的超参数给我们调整。宽度因子在MobileNetV1、V2、V3都可以运用。
通过宽度因子,可以调整神经网络中间产生的特征的大小,调整的是特征数据通道数大小,从而调整了运算量的大小。
宽度因子简单来说就是新网络中每一个模块要使用的卷积核数量相较于标准的MobileNet比例。对于深度卷积结合1x1方式的卷积核,计算量为:
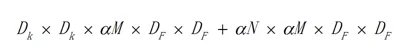
从MobileNet看轻量级神经网络的发展
算式中α即为宽度因子,α常用的配置为1,0.75,0.5,0.25;当α等于1时就是标准的MobileNet。通过参数α可以非常有效的将计算量和参数数量约减到α的平方倍。
下图为MobileNetV1使用不同α系数进行网络参数的调整时,在ImageNet上的准确率、计算量、参数数量之间的关系(每一个项中最前面的数字表示α的取值)。
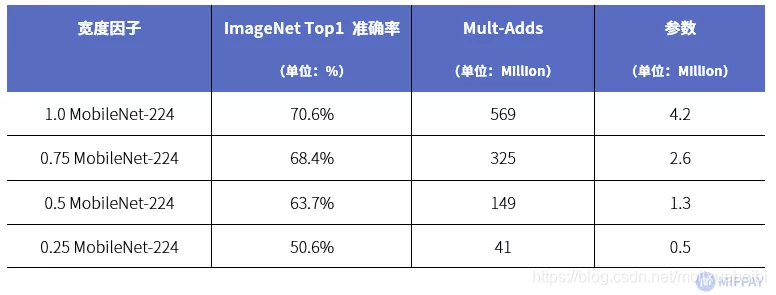
从MobileNet看轻量级神经网络的发展
(数据来源https://arxiv.org/pdf/1704.04861.pdf)
可以看到当输入分辨率固定为224x224时,随着宽度因子的减少,模型的计算量和参数越来越小。从上表可以看到, 0.25 MobileNet的正确率比标准版1.0MobileNet低20%,但计算量和参数量几乎只有标准版1.0MobileNet计算量、参数量的10%!对于计算资源和存储资源都十分紧张的移动端平台,可以通过α宽度因子调节网络的餐数量是非常实用的,在真正使用时我们可以按需调整α宽度因子达到准确率与性能的平衡。
3、分辨率因子
MobileNet还提供了另一个超参数分辨率因子(Resolution Multiplier)供我们自定义网络结构,分辨率因子同样在MobileNetV1、V2、V3都可以运用。
分辨率因子一般用β来指代,β的取值范围在(0,1]之间,是作用于每一个模块输入尺寸的约减因子,简单来说就是将输入数据以及由此在每一个模块产生的特征图都变小了,结合宽度因子α,深度卷积结合1x1方式的卷积核计算量为:
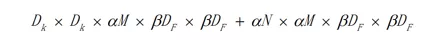
从MobileNet看轻量级神经网络的发展
下图为MobileNetV1使用不同的β系数作用于标准MobileNet时,在ImageNet上对精度和计算量的影响(α固定1.0)
从MobileNet看轻量级神经网络的发展
(数据来源https://arxiv.org/pdf/1704.04861.pdf)
上图中的 224、192、160、128 对应的分辨率因子分别为 1、 6/7、5/7、4/7。
β=1时,输入图片的分辨率为224x224,卷积后的图像大小变化为: 224x224 、112x112、56x56、28x28、14x14、7x7。
β= 6/7时,输入图片的分辨率为192x192,卷积后各层特征图像大小变化为:192x192、96x96、48x48、24x24、12x12、6x6。
卷积特征图像的大小变化不会引起参数量的变化,只改变模型M-Adds计算量。上图中 224分辨率模型测试ImageNet数据集准确率为70.6%,192分辨率的模型准确率为69.1%,但是M-Adds计算量减少了151M,对移动平台计算资源紧张的情况下,同样可以通过β分辨率因子调节网络输入特征图的分辨率,做模型精度与计算量的取舍。
4、规范化
深度学习中的规范化操作(Normalization),有助于加快基于梯度下降法或随机梯度下降法模型的收敛速度,提升模型的精度,规范化的参数能够提升模型泛化能力,提高模型的可压缩性。
按照规范化操作涉及对象的不同可以分为两大类,一类是对输入值进行规范化操作,比如批规范化(Batch Normalization)、层规范化(Layer Normalization)、实例规范化(Instance Normalization)、组规范化(Group Normalization)方法都属于这一类。另外一类是对神经网络中参数进行规范化操作,比如使用L0,L1范数。
批规范化
批规范化(Batch Normalization)几乎存在于MobileNetV1、V2、V3的每个卷积层的后面,目的是加快训练收敛速度,提升准确率。
批规范化是一种对数值的特殊函数变换方法,也就是说假设原始的某个数值是 x,套上一个起到规范化作用的函数,对规范化之前的数值 x 进行转换,形成一个规范化后的数值,即:
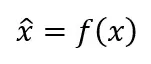
从MobileNet看轻量级神经网络的发展
所谓规范化,是希望转换后的数值满足一定的特性,至于对数值具体如何变换,跟规范化目标有关,不同的规范化目标导致具体方法中函数所采用的形式不同。通过自适应的重新参数化的方法,克服神经网络层数加深导致模型难以训练的问题。
参数规范化
参数规范化(Weight Normalization, WN)是规范化的一种, 通过人为的设定稀疏算法,去除模型中多余的参数(置为0)使得模型参数稀疏化,可以通过L1范式实现。
参数规范化是防止模型过分拟合训练数据。当训练一批样本的时候,随着训练的推移模型会越来越趋向于拟合样本数据。因为参数太多,会导致模型复杂度上升,容易过拟合。
需要保证模型"简单"的基础上最小化训练误差,这样得到的参数才具有好的泛化性能(也就是测试误差也小),而模型"简单"就是通过规则函数来实现的。
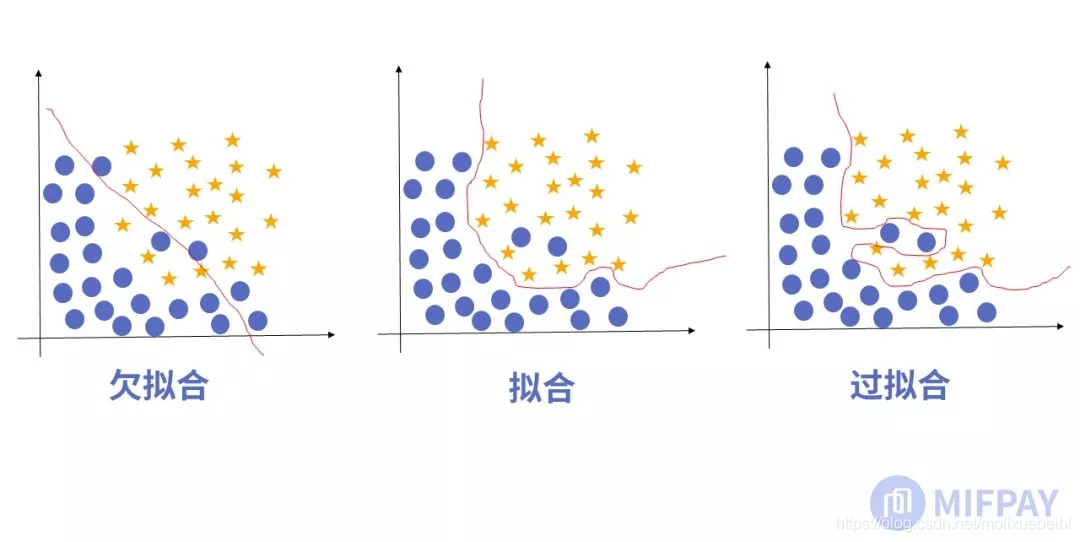
从MobileNet看轻量级神经网络的发展
如上图所示,左侧分类明显的是欠拟合,模型并没有能够拟合数据。中间图示为合适的拟合,右边图示是过拟合,模型在训练样本中拟合度是很好的,但是却违背了特征分类规律,在新的测试样本中表现糟糕,影响模型的泛化能力。显然右侧模型在训练是受到额外参数干扰。参数规则化能够使参数稀疏,减少额外参数的干扰,提高泛化能力。
模型拥有稀疏的参数(模型中有大量参数为0),也有利于通过压缩算法压缩模型的大小。
5、线性瓶颈
线性瓶颈英文为Linear Bottleneck,是从Bottleneck结构演变而来的,被用于MobileNetV2与V3。
Bottleneck结构首次被提出是在ResNet网络中。该结构第一层使用逐点卷积,第二层使用3×3大小卷积核进行深度卷积,第三层再使用逐点卷积。MobileNet中的瓶颈结构最后一层逐点卷积使用的激活函数是Linear,所以称其为线性瓶颈结构(Linear Bottleneck)。线性瓶颈结构有两种,第一种是步长为1时使用残差结构,第二种是步长为2时不使用残差结构。
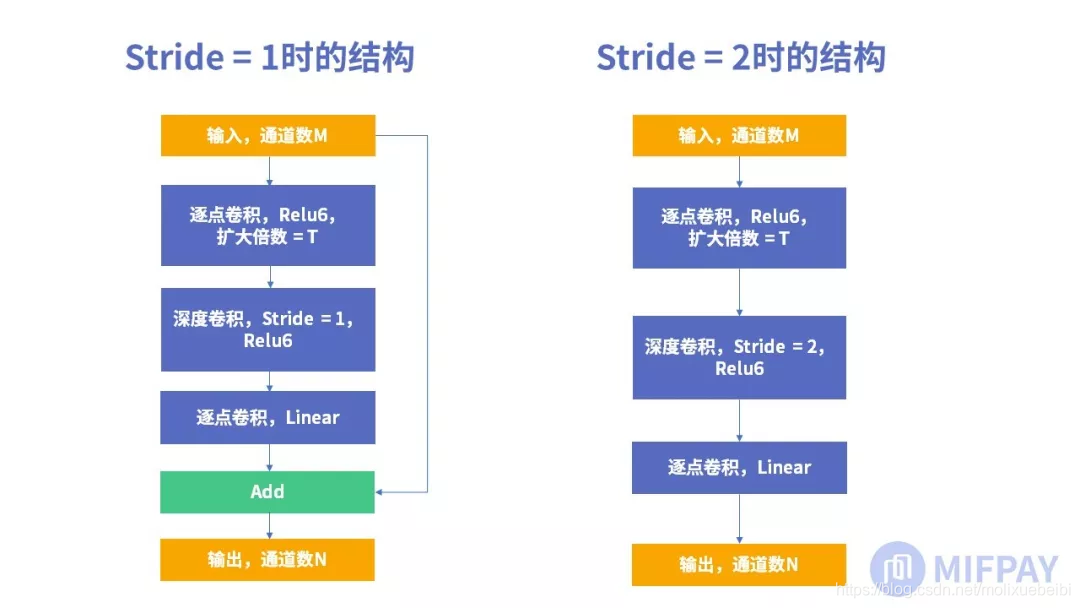
其中输入通道数为M,扩大倍数系数为T。T的值为大于0 的正数,当 0<T<1时,第一层逐点卷积起到的作用是降维。当 1<T时,第一层逐点卷积起到的作用是升维。
第二层为深度卷积,输入通道数 = 输出通道数 = M×T。
第三层为逐点卷积,作用是关联深度卷积后的特征图并输出指定通道数N。
线性瓶颈结构相对标准卷积能够减少参数数量,减少卷积计算量。从空间和时间上优化了网络。
6、反向残差
MobileNetV2中以ResNet的残差(Residuals)结构为基础进行优化,提出了反向残差(Inverted Residuals)的概念,之后也同样运用与MobileNetV3中。
ResNet中提出的残差结构解决训练中随着网络深度增加而出现的梯度消失问题,使反向传播过程中深度网络的浅层网络也能得到梯度,使浅层网络的参数也可训练,从而增加特征表达能力。
ResNet的残差结构实际是在线性瓶颈结构的基础上增加残差传播。如下图所示:
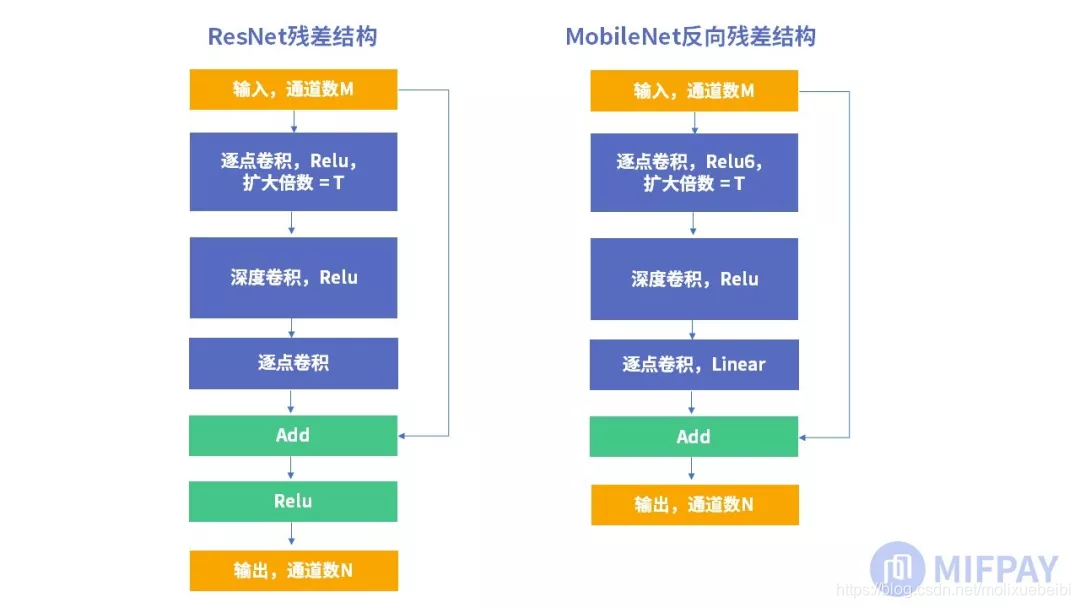
从MobileNet看轻量级神经网络的发展
ResNet中的残差结构使用第一层逐点卷积降维,后使用深度卷积,再使用逐点卷积升维。
MobileNetV2版本中的残差结构使用第一层逐点卷积升维并使用Relu6激活函数代替Relu,之后使用深度卷积,同样使用Relu6激活函数,再使用逐点卷积降维,降维后使用Linear激活函数。这样的卷积操作方式更有利于移动端使用(有利于减少参数与M-Adds计算量),因维度升降方式与ResNet中的残差结构刚好相反,MobileNetV2将其称之为反向残差(Inverted Residuals)。
7、5x5 的深度卷积
MobileNetV3中,深度卷积大量使用5x5大小的卷积核。这是因为使用神经结构搜索(NAS)技术计算出的MobileNetV3网络结构的过程中,发现了在深度卷积中使用5x5大小的卷积核比使用3x3大小的卷积核效果更好,准确率更高。关于NAS技术将会在下文的单独章节中做介绍。
8、Squeeze-and-excitation 模块
Squeeze-and-Excitation模块(简称SE模块)的首次提出是在2017年的Squeeze-and-Excitation Networks(SENet)网络结构中,在MNasNet中进行了改进,之后在MobileNetV3中大量使用。研究人员期望通过精确的建模卷积特征各个通道之间的作用关系来改善网络模型的表达能力。为了达到这个期望,提出了一种能够让网络模型对特征进行校准的机制,使得有效的权重大,无效或效果小的权重小的效果,这就是SE模块。
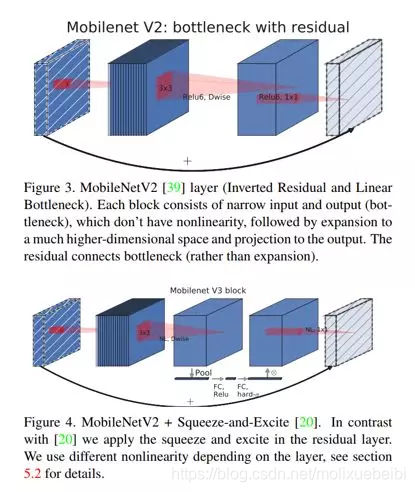
从MobileNet看轻量级神经网络的发展
(图片来源https://arxiv.org/pdf/1905.02244.pdf)
如上图,MobileNetV3的SE模块被运用在线性瓶颈结构最后一层上,代替V2中最后的逐点卷积,改为先进行SE操作再逐点卷积。这样保持了网络结构每层的输入和输出,仅在中间做处理,类似于软件开发中的钩子。
SE模块结构详解
下图表示一个SE 模块。主要包含Squeeze和Excitation两部分。W,H表示特征图宽,高。C表示通道数,输入特征图大小为W×H×C。
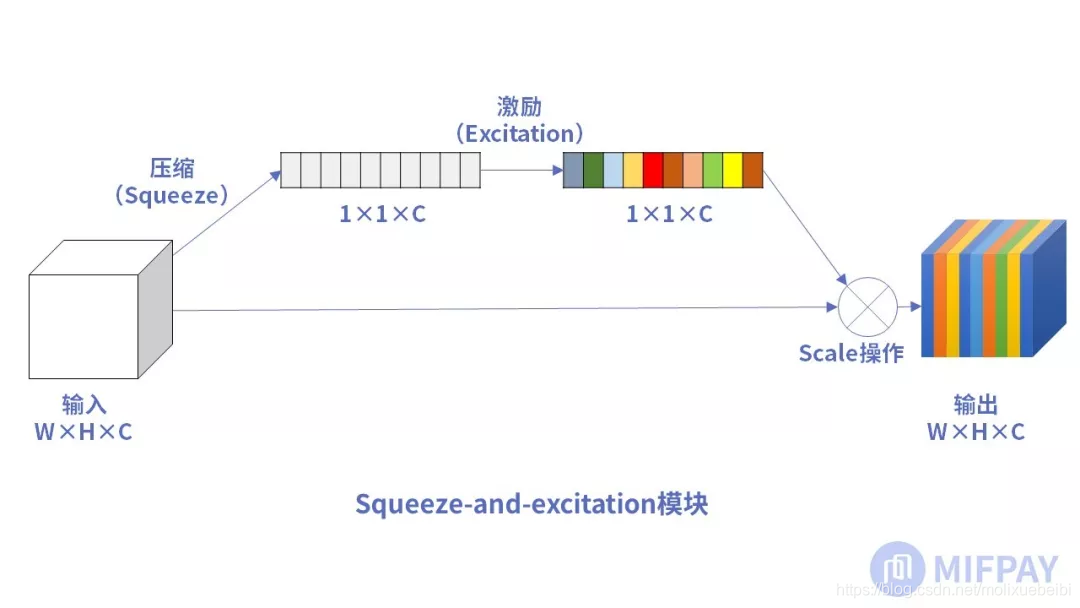
从MobileNet看轻量级神经网络的发展
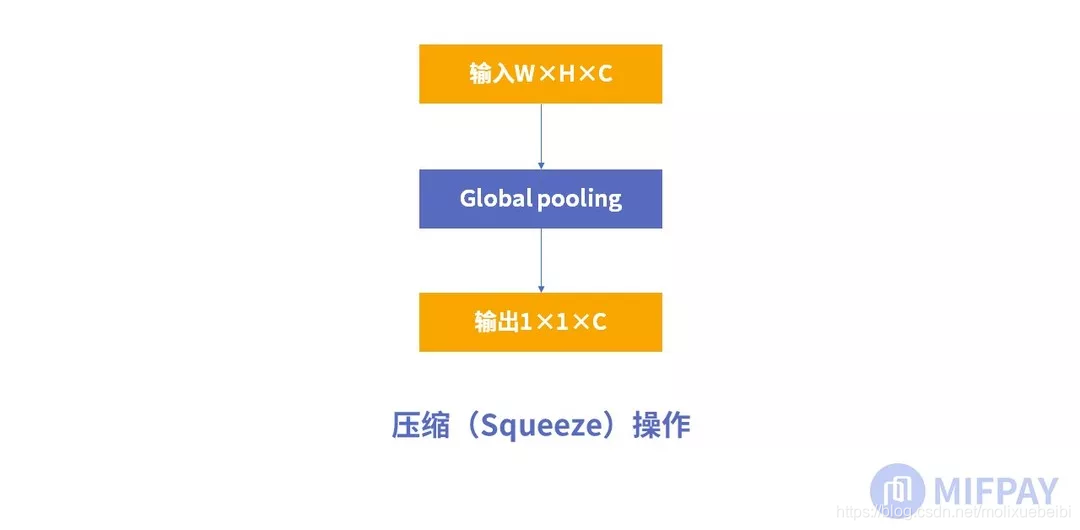
压缩(Squeeze)
第一步是压缩(Squeeze)操作,如下图所示
从MobileNet看轻量级神经网络的发展
这个操作就是一个全局平均池化(global average pooling)。经过压缩操作后特征图被压缩为1×1×C向量。
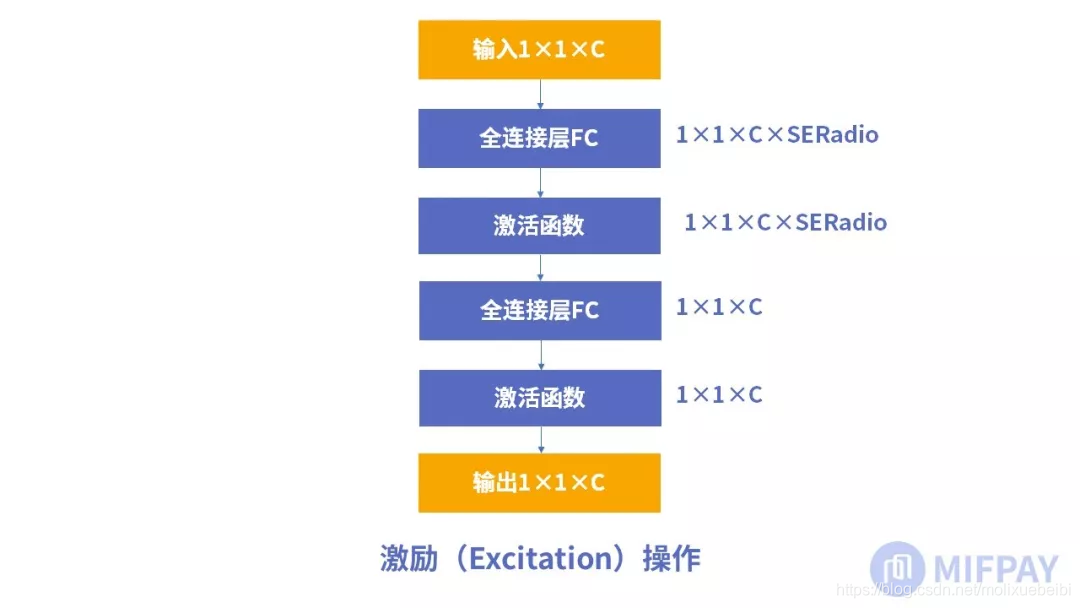
激励(Excitation)
接下来就是激励(Excitation)操作,如下图所示
从MobileNet看轻量级神经网络的发展
由两个全连接层组成,其中SERatio是一个缩放参数,这个参数的目的是为了减少通道个数从而降低计算量。
第一个全连接层有C*SERatio个神经元,输入为1×1×C,输出1×1×C×SERadio。
第二个全连接层有C个神经元,输入为1×1×C×SERadio,输出为1×1×C。
scale操作
最后是scale操作,在得到1×1×C向量之后,就可以对原来的特征图进行scale操作了。很简单,就是通道权重相乘,原有特征向量为W×H×C,将SE模块计算出来的各通道权重值分别和原特征图对应通道的二维矩阵相乘,得出的结果输出。
这里我们可以得出SE模块的属性:
参数量 = 2×C×C×SERatio
计算量 = 2×C×C×SERatio
总体来讲SE模块会增加网络的总参数量,总计算量,因为使用的是全连接层计算量相比卷积层并不大,但是参数量会有明显上升,所以MobileNetV3-Large中的总参数量比MobileNetV2多了2M。
MobileNetV3中的SE模块
SE模块的使用是很灵活的,可以在已有网络上添加而不打乱网络原有的主体结构。
ResNet中添加SE模块形成SE-ResNet网络,SE模块是在bottleneck结构之后加入的,如下图左边所示。
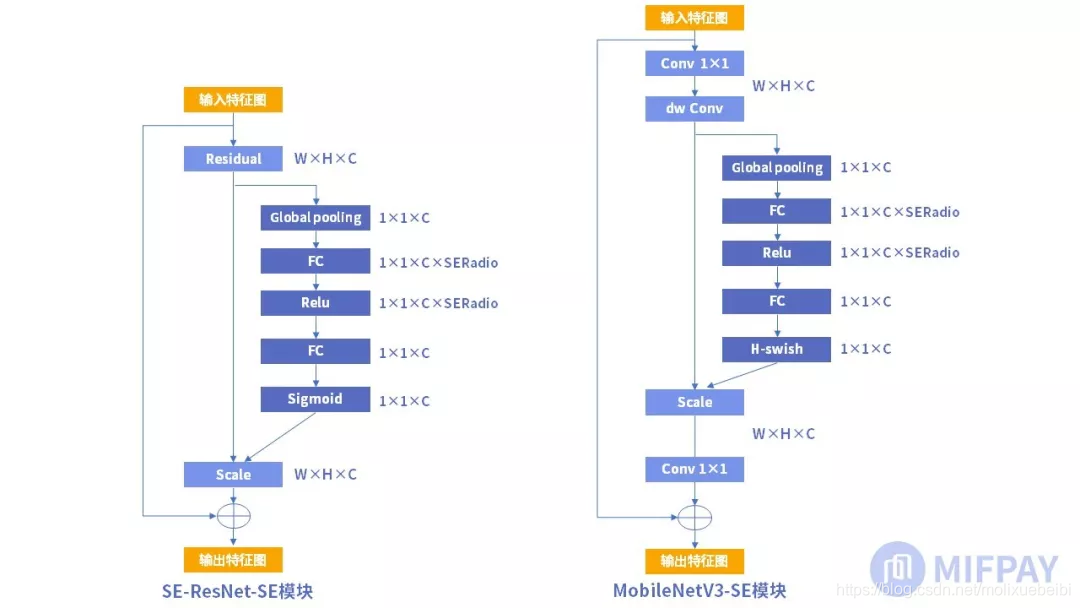
从MobileNet看轻量级神经网络的发展
MobileNetV3版本中SE模块加在了bottleneck结构的内部,在深度卷积后增加SE块,scale操作后再做逐点卷积,如上图右边所示。MobileNetV3版本的SERadio系数为0.25。使用SE模块后的MobileNetV3的参数量相比MobileNetV2多了约2M,达到5.4M,但是MobileNetV3的精度得到了很大的提升,在图像分类和目标检测中准确率都有明显提升。
9 h-swish激活函数
MobileNetV3中发现swish激活函数能够有效提高网络的精度,但是swish的计算量太大了,并不适合轻量级神经网络。MobileNetV3找到了类似swish激活函数但是计算量却少很多的替代激活函数h-swish(hard version of swish)如下所示:
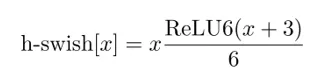
从MobileNet看轻量级神经网络的发展
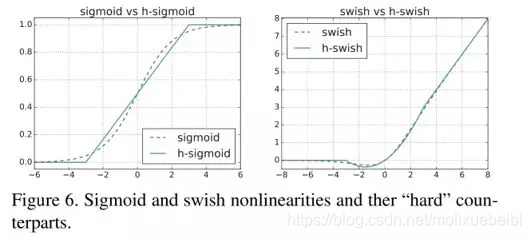
sigmoid、h-sigmoid、swish、h-swish激活函数的比较:
从MobileNet看轻量级神经网络的发展
(图片来源https://arxiv.org/pdf/1905.02244.pdf)
这种非线性在保持精度的情况下带来了很多优势,首先ReLU6在众多软硬件框架中都可以实现,其次量化时避免了数值精度的损失,运行快。这一非线性改变将模型的延时增加了15%。但它带来的网络效应对于精度和延时具有正向促进,剩下的开销可以通过融合非线性与先前层来消除。
MobileNet与其他模型对比
1、模型参数量对比
MobileNet模型拥有更小的空间复杂度。空间复杂度主要是指模型的大小,包括可训练参数和每一层生成的特征图大小。参数数量(params)关系到模型大小,单位通常为百万(Million),通常参数用32位浮点型表示,所以模型大小是参数数量的 4 倍左右。这里我们将对MobileNetV3-Large网络参数做一个全面的分析。
MobileNet与当前流行的模型参数大小对比,如下表所示:
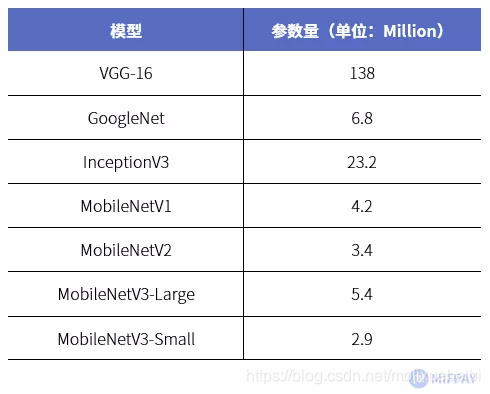
从MobileNet看轻量级神经网络的发展
(数据来源https://arxiv.org/pdf/1905.02244.pdf)
这里拿VGG-16与MobileNetV3-Large进行对比,下图为VGG-16的结构。

从MobileNet看轻量级神经网络的发展
VGG-16可训练参数分别位于 13 个卷积层 和 3个全连接层,共计16个,所以称为 VGG-16。
VGG网络特征:
小卷积核。将卷积核全部替换为3x3(极少用了1x1);
小池化核。相比AlexNet的3x3的池化核,VGG全部为2x2的池化核;
层数更深特征图更宽。基于前两点外,由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,计算量的增加放缓;
我们先来分析VGG-16 网络各层可训练参数,如下图所示:
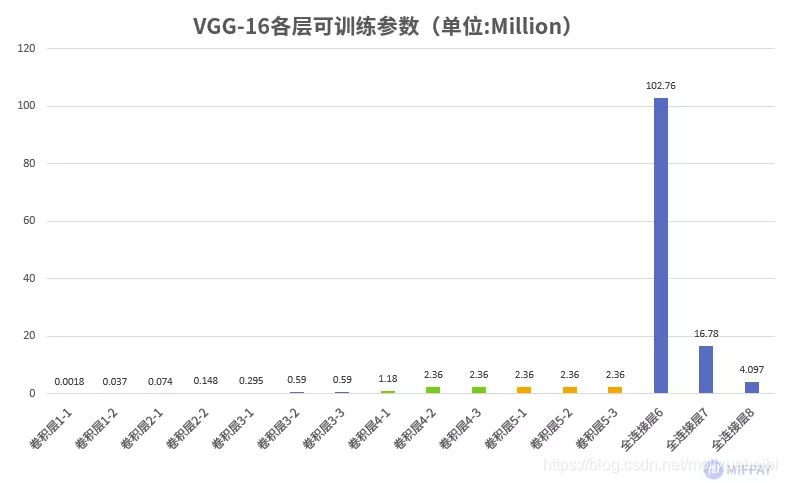
从MobileNet看轻量级神经网络的发展
VGG-16的参数主要分布在全连接层。
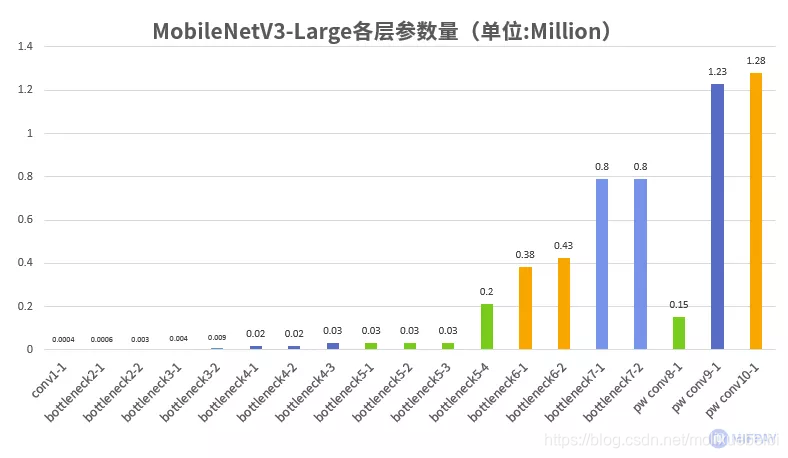
对比MobileNetV3-Large版本的各层可训练参数,如下图所示:
从MobileNet看轻量级神经网络的发展
MobileNetV3-Large中去除了全连接层,并使用优化后的卷积结构,总可训练参数数约5.4M个。而VGG-16 的可训练参数约138.36M个,参数量是MobileNetV3-Large的约25.6倍。
MobileNetV3-Large参数更少的原因:
去除全连接层
对比分析表1中,VGG-16网络后面三层全连接层的参数数量占整个网络是最多的, MobileNetV3-Large中使用了平均池化与逐点卷积代替了常规的全连接层,减少了参数量。
使用线性瓶颈结构
大量使用逐点卷积与深度卷积,通过线性瓶颈结构有效的减少了参数数量。
过多的训练参数会造成训练好的模型过大,MobileNetV3-Large训练得出的模型只有约22MB,VGG-16模型则高达 500多MB。模型体积的缩小同时带来的是计算量的缩小,在同等配置的硬件条件下,模型体积越小时训练或预测的过程会更快。所以对于移动场景来说,在空间尺寸上MobileNetV3-Large是更适合移动设备。
2 模型计算量对比
网络的时间复杂度主要是网络的训练时间和网络的预测时间。网络的训练时间和预测时间都跟网络的计算量有关。
时间复杂度统计,通常只考虑乘加操作(Multi-Adds)的数量,而且只考虑卷积层和全连接层等参数层的计算量,忽略批规范化操作和激活层等等。一般情况,卷积层和全连接层也会忽略仅纯加操作的计算量,如偏置加(bias)和残差加(shotcut)等。
MobileNet与其他流行深度模型计算量及使用google Pixel-1手机运行速度的对比(单次从输入到输出的耗时)。
从MobileNet看轻量级神经网络的发展
(数据来源综合https://arxiv.org/pdf/1905.02244.pdf;https://arxiv.org/pdf/1801.04381.pdf)
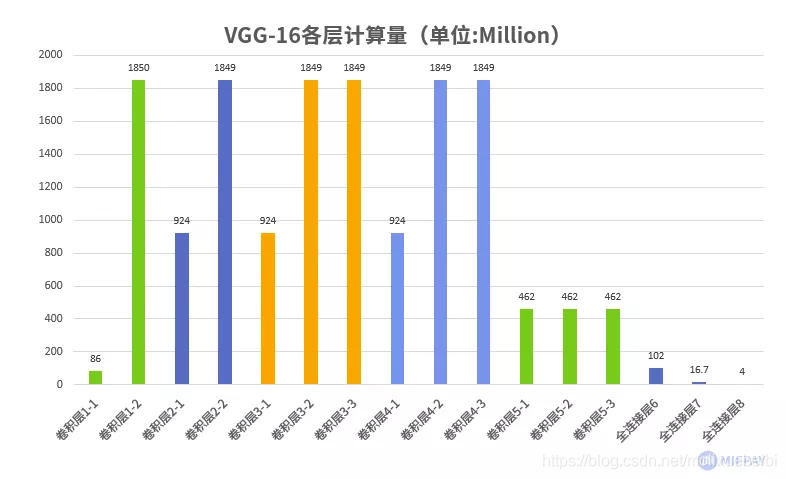
下图所示为VGG-16各层计算量统计,VGG-16使用标准卷积结构,计算量主要集中在卷积层,可看出标准卷积是十分耗费计算量的。VGG-16总计算量为:约15300M次。
从MobileNet看轻量级神经网络的发展
下图所示为MobileNetV3-Large各层计算量统计,MobileNetV3-Large优化后的卷积结构计算量得以降低很多,计算量总计 约219M次。
从MobileNet看轻量级神经网络的发展
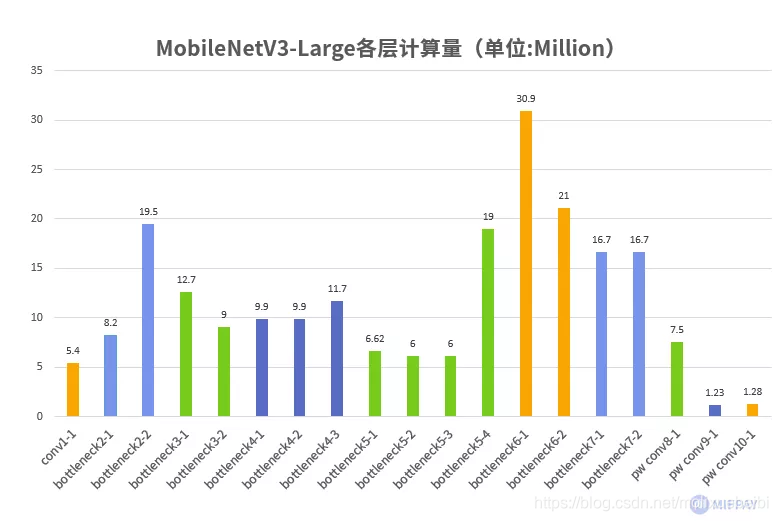
MobileNetV3-Large计算量更少的原因:
深度卷积和逐点卷积的大量使用
使用深度卷积和逐点卷积替换标准卷积,计算量成倍减少。
使用反向残差结构
大量反向残差结构,使得MobileNetV3-Large网络层数增加为49层,比VGG-16的层数更多(VGG-16为16层)。层数增加后参数反而比VGG-16更少,并保证了模型的准确率。
MobileNetV3-Large输入图片经过一次模型需要的浮点计算量为219M次,而VGG-16模型则需要使用的浮点计算量为15300M次,是MobileNetV3-Large的约70.8倍。计算量的减少使MobileNetV3-Large在时间尺寸上更适合移动设备。
3、具有竞争力的准确率
图像分类
MobileNet具有行业竞争力的准确率,在图像分类领域中分别和主流网络进行对比。
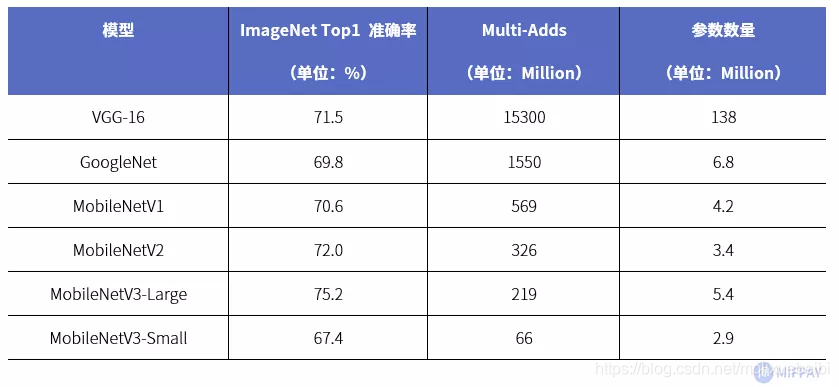
MobileNet在减少模型参数,减少计算量的同时也保证了模型具有优良的准确率。使用ImageNet 数据集分类,宽度因子和分辨率因子都为1,对比Top1准确率(识别出概率最高的类别准确率),如下表所示
从MobileNet看轻量级神经网络的发展
(数据来源https://arxiv.org/pdf/1905.02244.pdf)
在ImageNet数据集分类中,MobileNetV1、MobileNetV2网络在分类准确率上达到了VGG-16和GoogleNet的水平。最新推出的MobileNetV3性能更强悍。
MobileNetV3-Large版在ImageNet数据集上Top1准确率达到75.2%,计算量和参数量分别约为VGG-16的1.43%和3.9%。MobileNet使用极少的参数与计算量就能够使性能达到甚至超过大型神经网络。
目标检测
SSDLite是以标准SSD模型为基础,使用深度可分离卷积替换SSD模型中的标准卷积而形成的全新网络结构。
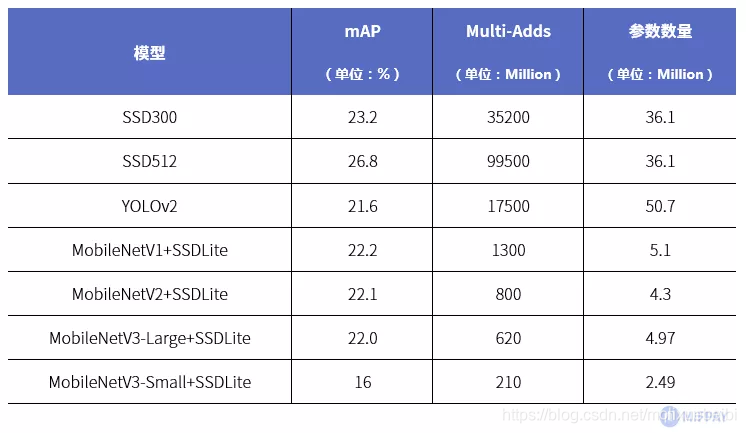
将SSD模型中原本作为特征提取网络的VGG-16替换为MobileNet。在MS COCO数据集中跑目标检测任务,其性能和当前流行的目标检测网络对比如下表所示:
从MobileNet看轻量级神经网络的发展
(数据来源https://arxiv.org/pdf/1905.02244.pdf)
MobileNetV1+SSDLite 的mAP(平均精度)能达到22.2%,比SSD300少1%,计算量为SSD300的3.7%,参数量为SSD300的14.1%。
最新的MobileNetV3-Large+SSDLite 的mAP为22.0%,近似MobileNetV1+SSDLite,但是计算量为MobileNetV1+SSDLite的47.7%, 参数量为MobileNetV1+SSDLite的97.4%。对比SSD和YOLO目标检测网络,MobileNet实现的目标检测网络,在保证检测正确率的同时成倍的降低了计算量和参数数量。
MobileNet各版本的指标对比
上文中将MobileNetV3-Large与VGG-16等的参数量、计算量、准确率(ImageNet数据集Top1)、在google Pixel-1手机上的实际运行速度等指标进行了对比。本章节将针对MobileNet自身各版本的指标进行对比。可以看到的的趋势是参数量、计算量越来越小,准确率越来越高,运行速度越来越快。
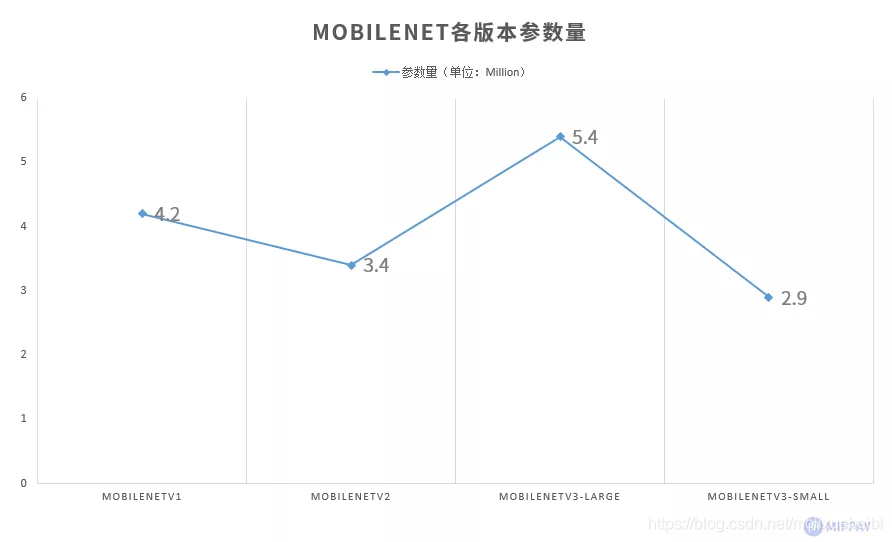
1、参数量对比
从MobileNet看轻量级神经网络的发展
MobileNetV3版本使用SE结构,造成参数量比MobileNetV2增加。这样牺牲了部分模型空间,换取模型精度的提高。
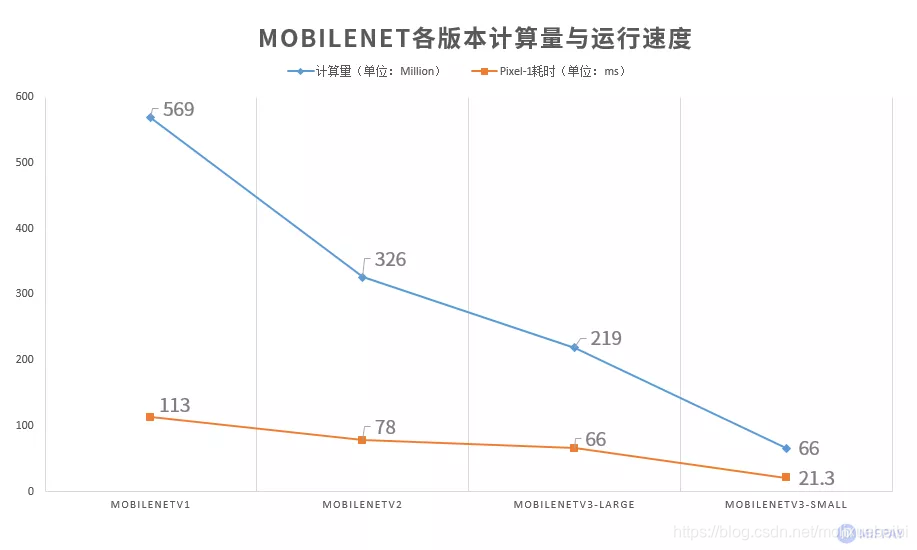
2、计算量对比
从MobileNet看轻量级神经网络的发展
MobileNet计算量逐步减少,在Pixel-1手机上的运行速度越来越快。
3、准确率对比
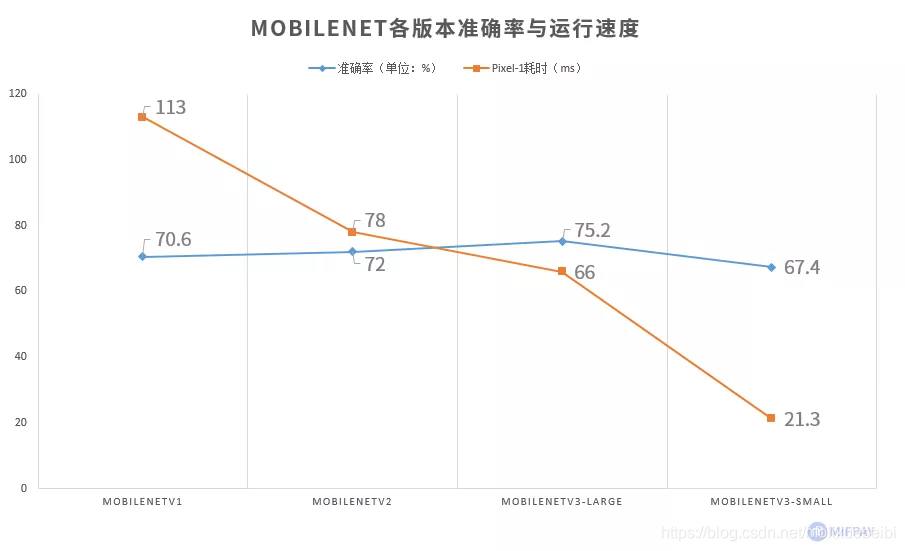
从MobileNet看轻量级神经网络的发展
最新的MobileNetV3实现了模型精度的大幅提升,同时Pixel-1手机实际运行速度还更快了。
MobileNetV3与NAS
单从MobileNetV3的网络结构和特性去看,相对于V1和V2版本也许不够特别,但V3的特别之处在于网络结构是使用基于神经架构搜索技术(NAS)学习出来的,使得V3得以将其他很多网络中的优秀特性都集于一身,而在V3之前的V1、V2版本中,网络结构则是由研究人员经过人工设计和计算得到的。本章节仅介绍MobileNetV3与NAS的一些相关内容,不对NAS的技术细节展开。
1、NAS简介
神经架构搜索(Network Architecture Search, NAS),是一种试图使用机器自动的在指定数据集的基础上通过某种算法,找到一个在此数据集上效果最好的神经网络结构和超参数的方法,可以一定程度上解决研究人员设计一个网络的耗时的问题。NAS甚至可以发现某些人类之前未曾提出的网络结构,这可以有效的降低神经网络的使用和实现成本。
目前市面上也已经出现了许多运用NAS技术的产品,如AutoML、OneClick.AI、Custom Vision Service、EasyDL等。
NAS技术不是在MobileNetV3中第一次使用的,在此之前也已经运用到了一些网络模型中,如NasNet、MNasNet、AmoebaNet、MobileNet。
2、NAS原理
NAS的原理是给定一个称为搜索空间的候选神经网络结构集合(即搜索空间包含了如:深度卷积、逐点卷积、常规卷积、卷积核、规范化、线性瓶颈、反向残差结构、SE模块、激活函数等等可作为原子的结构),用某种策略从中搜索出最优网络结构。神经网络结构的优劣即性能用某些指标如精度、速度来度量,称为性能评估。这一过程如下图所示:
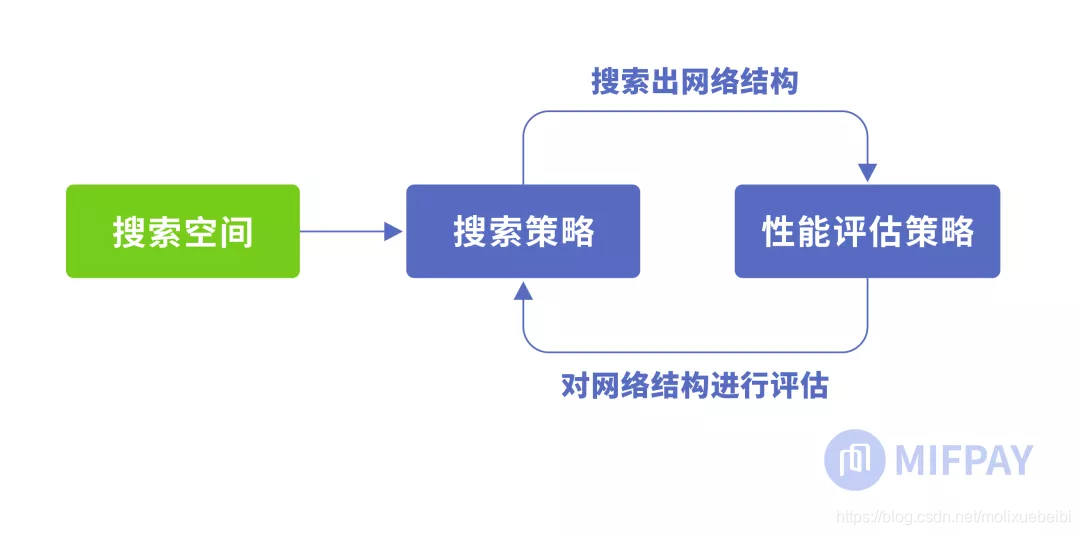
从MobileNet看轻量级神经网络的发展
搜索空间,搜索策略,性能评估策略是NAS算法的核心要素。搜索空间定义了可以搜索的神经网络结构的集合,即解的空间。搜索策略定义了如何在搜索空间中寻找最优网络结构。性能评估策略定义了如何评估搜索出的网络结构的性能。对这些要素的不同实现得到了各种不同的NAS算法。常见的算法有:全局搜索空间、cell-based 搜索空间、factorized hierarchical search space分层搜索空间、one-shot 架构搜索等,其中的优化算法又有:基于强化学习的算法、基于进化算法的算法、基于代理模型的算法等。
3、MobileNetV3中的NAS
MobileNetV3使用platform-aware NAS搜索全局网络结构的优化block,也就是从搜索空间的集合中根据预定义的网络模板搜索出网络结构;之后使用NetAdapt算法针对block中的每一层搜索需要使用的卷积核个数。搜索出一种网络后需要进行性能评估。这时候需使用真实手机的cpu(MobileNetV3中使用pixel-1手机)运行TFLite Benchmark Tool进行性能评估。
搜索网络流程如下图:
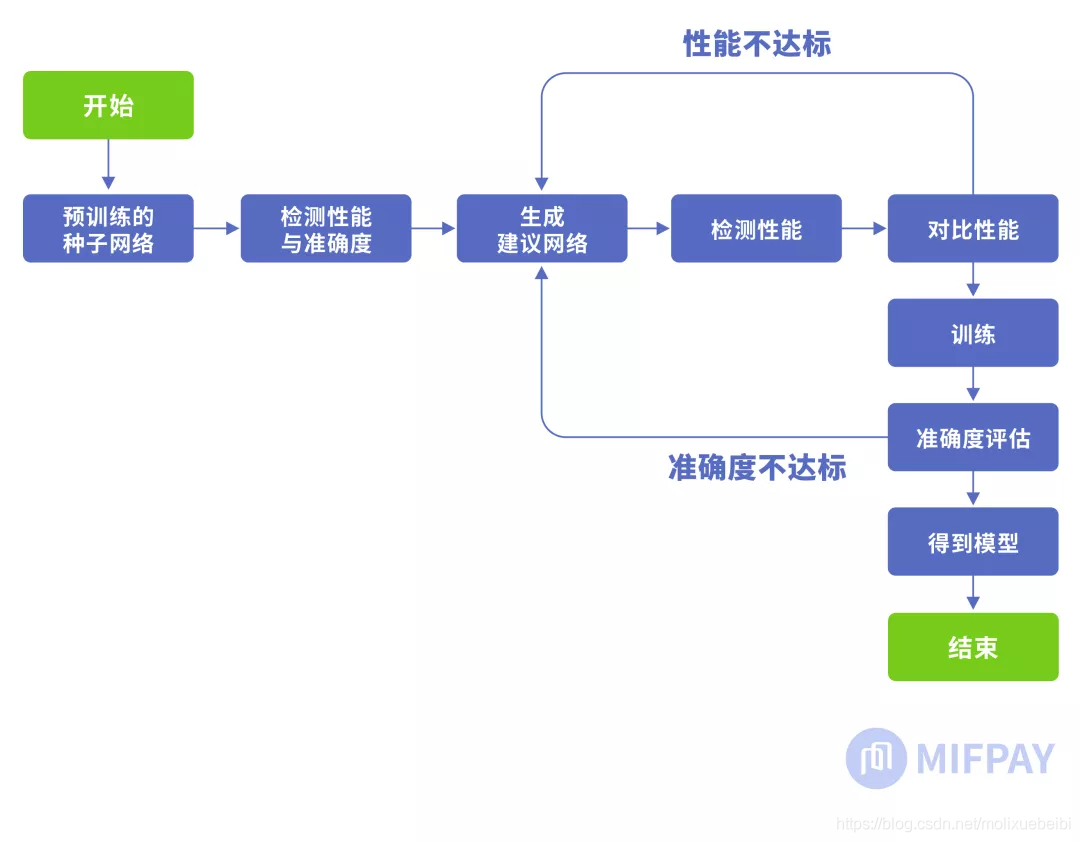
从MobileNet看轻量级神经网络的发展
MobileNet与其他网络结合
1、目标检测
SSDLite是使用深度可分离卷积替换SSD模型中的标准卷积而形成的。如下图所示,SSDLite对比SSD模型参数量降低了7倍,乘法计算量降低了3.5倍。
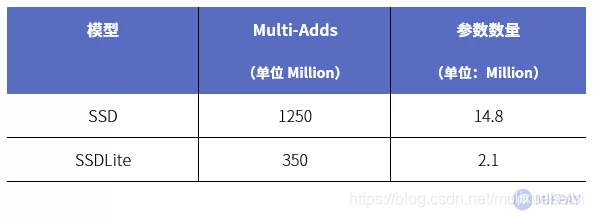
从MobileNet看轻量级神经网络的发展
(数据来源https://arxiv.org/pdf/1801.04381.pdf)
2、语义分割
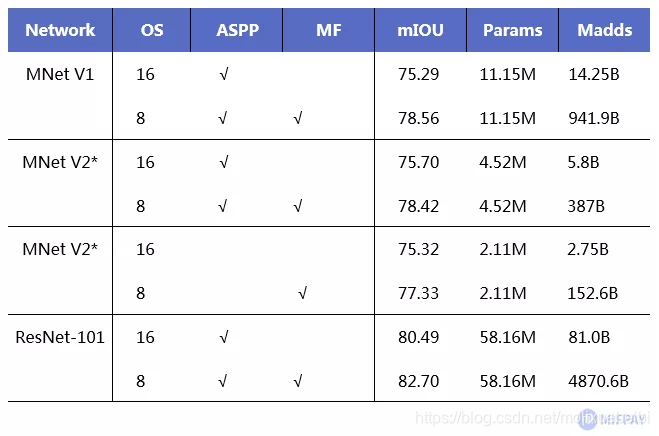
将DeepLabv3的特征提取网络ResNet-101更换为MobileNetV1或V2。使用MobileNetV1时乘法计算量减少了4.9-5.7倍,用了MobileNetV2后加法数量比MobileNetV1还降低了2.5倍。
从MobileNet看轻量级神经网络的发展
(数据来源https://arxiv.org/pdf/1801.04381.pdf)
上图为相对ResNet-101的参数量和正确率的对比,可见使用MobileNet作为基础网络,在准确率下降幅度不大的情况下,可以做到参数量和计算量大幅度下降。
3、人脸识别
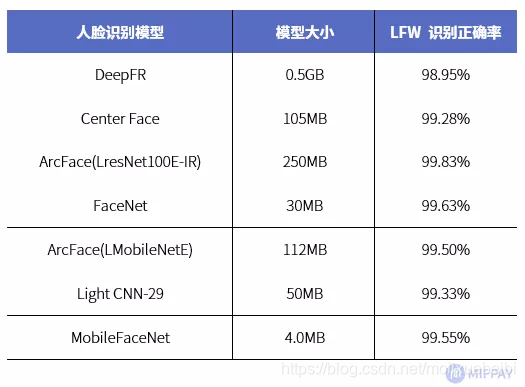
MobilefaceNets是一个从MobileNetV2衍生而来的拥有工业级精度和速度的轻量级人脸识别网络,模型大小只有4MB,专为人脸识别任务设计,精度比肩大模型(FaceNet,Deep Face,Center Face等)。
MobilefaceNets从三个方面改进了MobileNetV2。即针对平均池化层,采用了可分离卷积代替平均池化层。针对人脸识别任务,采用ArcFace的损失函数进行训练。针对网络结构,通道扩张倍数变小,使用Prelu激活函数代替relu激活函数。
在LFW人脸识别训练集中与当前流行人脸识别模型对比。MobilefaceNets明显准确率更高,速度更快,体积更小。
从MobileNet看轻量级神经网络的发展
(数据来源https://arxiv.org/ftp/arxiv/papers/1804/1804.07573.pdf)
未来
MobileNet从V1到V3的进化,就是在保证模型准确率的基础上,尽可能的减少神经网络参数、减少计算量,并在此之上尽可能提升准确率。但我们更应该关注的并不是MobileNet网络结构本身,而是它的每个特性。
MobileNet使用了批规范化,参考并优化了Xception结构中的深度可分离卷积、ResNet中的瓶颈结构和残差结构、MNasNet中的Squeeze-and-excitation结构,使用了全新的h-swish激活函数等,从而进化出了现在良好的效果。可见MobileNet的演进之路是轻量级神经网络演进之路的缩影,业内各个模型的结构和优势都是相互借鉴参考、改进。
新推出的MobileNetV3的特别之处在于网络结构是使用基于神经架构搜索NAS技术学习出来的,将很多网络中的优点都集于一身,也许会由此带起NAS研究的热潮,让机器自动为我们找寻更合适的神经网络结构,为生活中的各种场景的AI应用带来无限可能!
机器学习的明天是在小数据、个性化、可靠性上面
混淆矩阵详细说明 |