ХвЖӘҪМіМ3DөгФЖРОЧҙ·ЦАајтҪйРҙөГәЬКөУГЈ¬ПЈНыДЬ°пөҪДъЎЈ
3DөгФЖРОЧҙ·ЦАајтҪй
3DРОЧҙ·ЦАаЦчТӘУРИэЦЦ·Ҫ·ЁЈә»щУЪ¶аКУНјөДЈЁmulti-viewЈ©Ј¬»щУЪМе»эөДЈЁvolumetric-basedЈ©Ј¬»щУЪөгөДЈЁpoint-basedЈ©ЎЈ
»щУЪ¶аКУНјөД·Ҫ·ЁҪ«·ЗҪб№№»ҜөДөгФЖН¶У°ОӘ2DНјПсЈ¬¶ш»щУЪМе»эөД·Ҫ·ЁҪ«өгФЖЧӘ»»ОӘ3DМе»эұнКҫЎЈИ»әуАыУГ2D»т3Dҫн»эНшВзАҙКөПЦРОЧҙ·ЦАаЎЈПа·ҙЈ¬»щУЪөгөД·Ҫ·ЁЦұҪУФЪФӯөгФЖНјПсЙПФЛРРЈ¬І»»бФміЙРЕПў¶ӘК§Ј¬ХэФЪЦрҪҘіЙОӘЦчБчЎЈ
»щУЪ¶аКУНјөДөгФЖ·ЦАаЛг·Ё
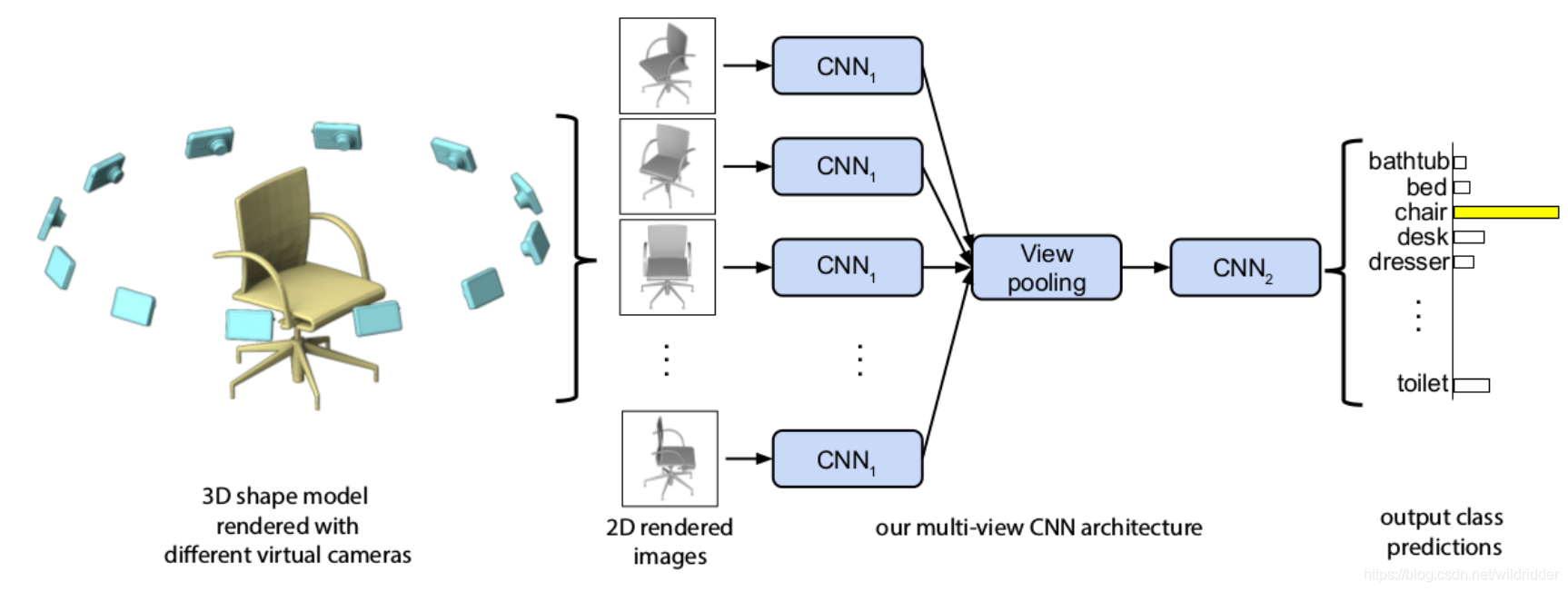
»щУЪ¶аКУНјөД·Ҫ·ЁКЧПИҪ«3DРОЧҙН¶У°өҪ¶аёцКУНјЦРЈ¬И»әуМбИЎКУНјөДМШХчЈ¬ИЪәПХвР©МШХчТФҪшРРЧјИ·өДРОЧҙ·ЦАаЎЈЛщТФ№ШјьФЪУЪИзәОИЪәПХвР©МШХчЎЈёГ·Ҫ·ЁҝӘҙҙРФөД№ӨЧчКЗ15ДкМбіцөДMVCNNЈ¬ИзНјЛщКҫЈ¬ЖдЦРЛщУР·ЦЦ§өДCNN1№ІПнИЁЦШЈ¬ЛьҪ«¶аКУНјМШХчmaxpool»ҜОӘИ«ҫЦГиКц·ыЎЈ ө«КЗЈ¬ЧоҙуіШ»ҜЦ»ДЬұЈБфМШ¶ЁКУНјЦРөДЧоҙуФӘЛШЈ¬ҙУ¶шөјЦВРЕПў¶ӘК§ЎЈ
Ц®әуЈ¬ YangөИИЛМбіц¶Ф¶аКУНјөД№ШПөҪшРРҪЁДЈЈ¬МбіцБЛТ»ЦЦ№ШПөНшВзЈ¬УГБҪёцДЈҝй·ЦұрМбИЎІ»Н¬КУНјјдөДregion№ШПөТФј°ХыёцКҫНјЦ®јдөД№ШПөЈ¬ЧоЦХЙъіЙ3DГиКц·ыЈ¬ИзНјЛщКҫ:
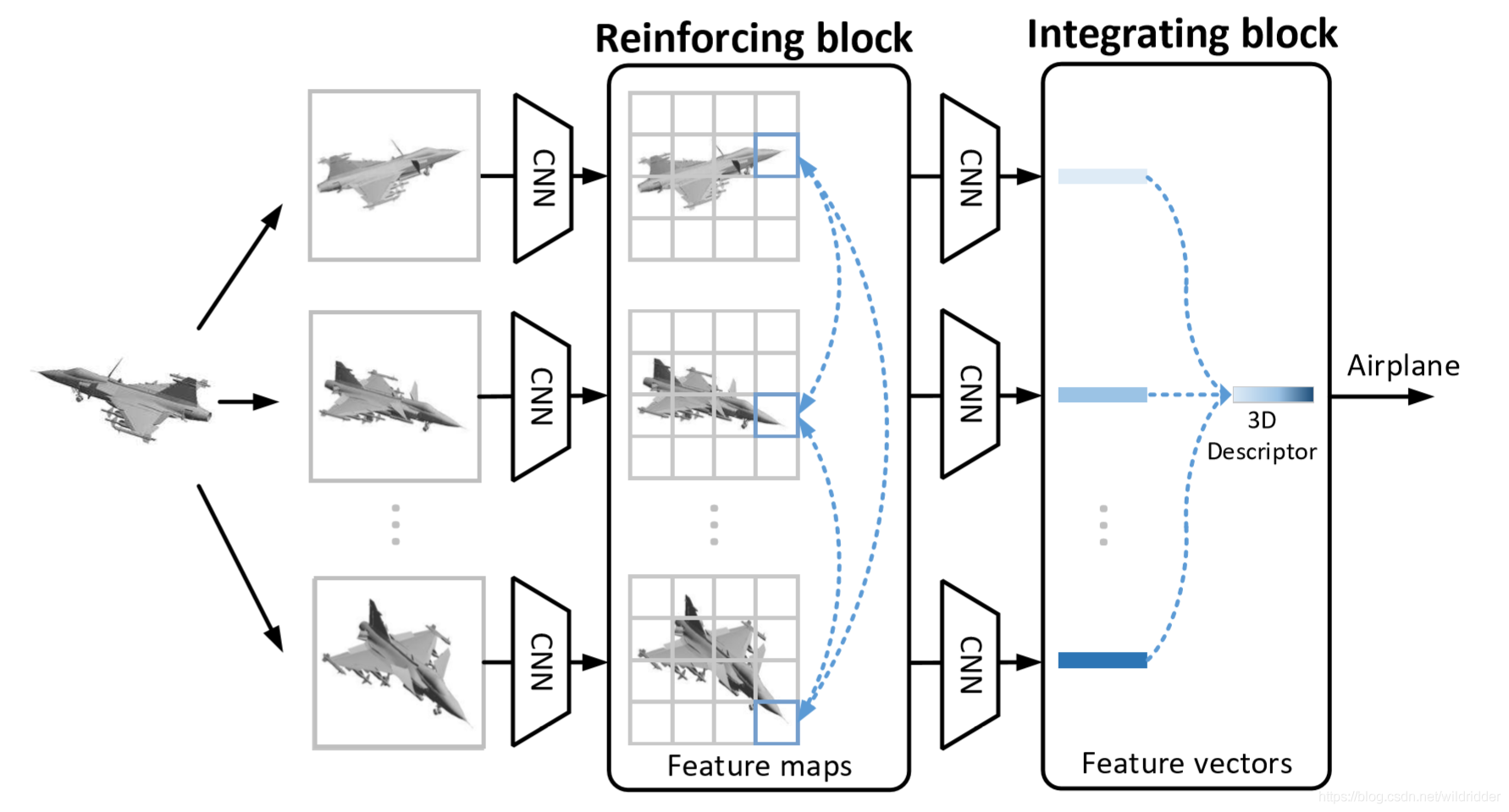
WeiөИИЛМбіцК№УГНјҫн»эНшВзҪЁДЈ¶аёцКУНјЦ®јдөД№ШПөЈ¬ГҝёцКУНјЧчОӘТ»ёцНјҪЪөгЈ¬И»әуҪ«УЙҫЦІҝНјҫн»эЈ¬non-localПыПўҙ«өЭәНСЎФсРФКУНјІЙСщЧйіЙөДәЛРДІгУҰУГУЪ№№ҪЁөДНјЎЈ№ШУЪёГОДХВөДПкПёҪйЙЬҝЙТФІОҝјТ»ЖӘЦӘәхөДҪІҪвЎЈ
»щУЪМе»эөД·Ҫ·Ё
НЁ№эМеЛШНшёсҪшРРС§П°ҝЙТФҪвҫц¶аКУНјұнКҫөДЦчТӘИұөгЎЈМеЛШНшёсЛхРЎБЛ¶юО¬әНИэО¬Ц®јдөДІоҫаЈ¬ЛьГЗКЗЧоҪУҪьНјПсөДИэО¬ұнКҫРОКҪЈ¬ХвК№өГ¶юО¬Йо¶ИС§П°өДёЕДоЈЁұИИзҫн»эІЩЧчЈ©ДЬ№»ИЭТЧөШУҰУГУЪИэО¬Зйҫ°ЎЈ
ФЪ 2015 ДкМбіцөД VoxNetЈ¬КЗЧоФзФЪёш¶ЁМеЛШНшёсКдИлөДЗйҝцПВФЪОпМе·ЦАаИООсЙПИЎөГУЕТмұнПЦөДЙо¶ИС§П°·Ҫ·ЁЎЈVoxNet К№УГөДКЗёЕВКХјУГНшёсЈ¬ЖдЦРөДГҝёцМеЛШ¶ј°ьә¬БЛёГМеЛШФЪҝХјдЦРұ»ХјУГөДёЕВКЎЈХвСщЧцөДТ»ёцәГҙҰҫНКЗЈ¬ЛьФКРнНшВзЗш·ЦТСЦӘКЗЧФУЙөДМеЛШЎЈХыёцБчіМИзПВЈә
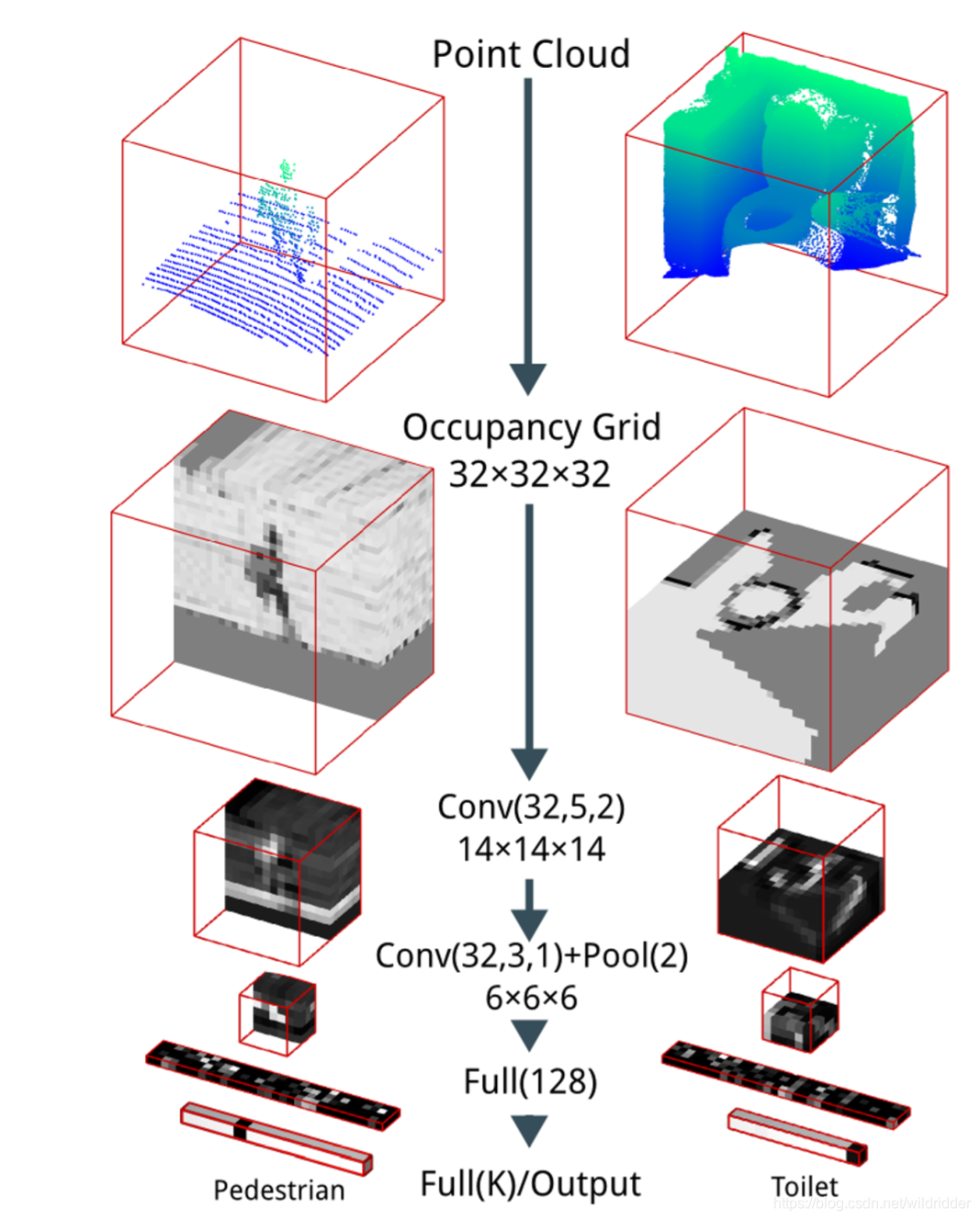
УЙУЪМеЛШНшёсУлНјПсК®·ЦПаЛЖЈ¬ЛьГЗКөјКЙПК№УГөДҙшІҪіӨөДҫн»эәНіШ»ҜФЛЛг¶јКЗҙУ¶юО¬ПсЛШөД№ӨЧч·ҪКҪҪшРРөчХыЗЁТЖөҪИэО¬МеЛШЙПАҙөДЎЈҫн»эЛгЧУК№УГөДКЗ d×d×d×c өДҫн»эәЛ¶шІ»КЗ¶юО¬ҫн»эЙсҫӯНшВзЦРК№УГөД d×d×cЈ¬іШ»ҜФЛЛгҝјВЗөДКЗІ»ЦШөюөДИэО¬МеЛШҝй¶шІ»КЗ¶юО¬ПсЛШҝйЎЈНјЦРConv(f,d,s) fұнКҫҫн»эЛгЧУёцКэЈ¬dОӘҫн»эәЛіЯҙзЈ¬ТФј°ІҪіӨsЎЈ
МеЛШөДИұөгКЗЈәРиТӘәЬёЯөД·ЦұжВКІЕДЬДЈДвіцТ»ёцОпМеөДҫ«ЧјҪб№№ЎЈ¶шёЯ·ЦұжВКНщНщТвО¶ЧЕҙуБҝөДДЪҙжәНјЖЛгБҝЎЈХвАа·Ҫ·ЁДСТФҙҰАнГЬјҜөД3DКэҫЭЈ¬ТтОӘјЖЛгБҝЛжЧЕ·ЦұжВКИэҙО·ҪФціӨЎЈ
ОӘБЛҪвҫцХвёцОКМвЈ¬OctNetМбіцЈ¬ФЪөгФЖөИұнКҫ·Ҫ·ЁЦРөД3DКэҫЭұҫЙнКЗПЎКиөДЈЁҝХјдЦРУРТ»Р©өШ·ҪûûУРОпМеҙжФЪЈ©Ј¬ХвҫНөјЦВБЛФЪК№УГ3Dҫн»эКұөДјЖЛгЧКФҙАЛ·СЎЈЛщТФOCNetК№УГТ»ЧйІ»ЖҪәвөД°ЛІжКчАҙ¶ФҝХјдҪшРР·ЦІг»®·ЦЈ¬ёьҫЯМеөШЛөЈ¬ТФөЭ№й·ҪКҪІр·ЦФЪЖдУтЦР°ьә¬КэҫЭөгөД°ЛІжКчҪЪөгЈ¬ІўФЪКчөДЧојС·ЦұжВКНЈЦ№ЎЈТІҫНКЗЛөOCNetёщҫЭ3DҪб№№¶ҜМ¬өД·ЦІјјЖЛгәНҙжҙўЈ¬ХвСщҝЙТФФЪёЯ·ЦұжВКөДКұәтҪЪКЎјЖЛгәНҙжҙўЎЈ
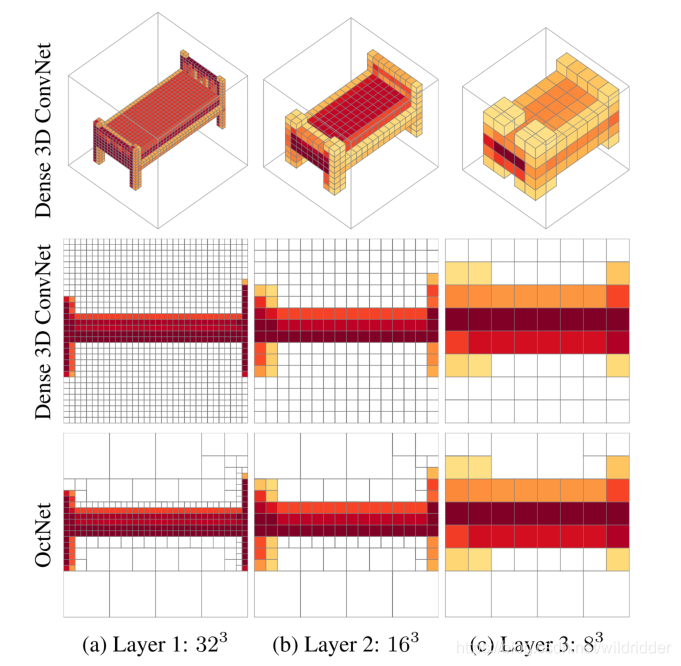
ИзНјЛщКҫЈ¬өЪ¶юРРКЗЖХНЁөД3D ConvNetЈ¬ҝЙТФҝҙөҪИз№ыК№УГёЯ·ЦұжВКјЖЛгЈ¬ДЗГҙИ«Нј¶јКЗГЬјҜөДНшёсөгЈ¬ҙъұнёГҙҰөДҫн»эјЖЛгО»ЦГЈ¬¶шөЪИэРРөДOCNetҝЙТФёщҫЭКдИлОпМеөДРОЧҙЈ¬¶ҜМ¬өчҪЪГҝёцО»ЦГөД·ЦұжВКЈЁНЁ№э°ЛІжКчКөПЦЈ¬№ШУЪ°ЛІжКчҝЙІОҝјЈә°ЛІжКчЈ©Ј¬ҙУ¶шФЪК№УГН¬өИ·ЦұжВКөДКұәтҪөөНјЖЛгБҝәНДЪҙжХјУГЎЈ
ө«КЗМеЛШНшёсИФИ»ҫЯУРТ»Р©ИұөгЎЈКЧПИЈ¬УлөгФЖПаұИЈ¬ЛьГЗ¶ӘК§БЛ·ЦұжВКЎЈТтОӘИз№ыҙъұнёҙФУҪб№№өДІ»Н¬өгҫаАләЬҪьЈ¬ЛьГЗ»бұ»ұ»°у¶ЁФЪН¬Т»ёцМеЛШЦРЎЈУлҙЛН¬КұЈ¬УлПЎКи»·ҫіЦРөДөгФЖПаұИЈ¬МеЛШНшёсҝЙДЬөјЦВІ»ұШТӘөДёЯДЪҙжК№УГВКЎЈХвКЗТтОӘЛьГЗЦч¶ҜПыәДДЪҙжАҙұнКҫЧФУЙәНОҙЦӘөДҝХјдЈ¬¶шөгФЖЦ»°ьә¬ТСЦӘөгЎЈ
»щУЪөгФЖөДЛг·Ё
Pointwise MLP
ёГАа·Ҫ·ЁНЁ№эјёёцMLPҪЁДЈөгУлөгЦ®јдөД№ШПөҝЙЈ¬И»әу»гҫЫіЙИ«ҫЦМШХчЎЈПИЗэҙъұн№ӨЧчКЗPointNetЈ¬
ОҙНкҙэРш…
·ө»ШБРұн
cuda8.0°ІЧ°°ьј°°ІЧ°·Ҫ·Ё |