这篇教程AE与VAE--AutoEncoder:自编码器-VAE:变分自编码器写得很实用,希望能帮到您。
AE与VAE
- AutoEncoder:自编码器
- 不同种类的自编码器
- VAE:变分自编码器
- 总结
AutoEncoder:自编码器
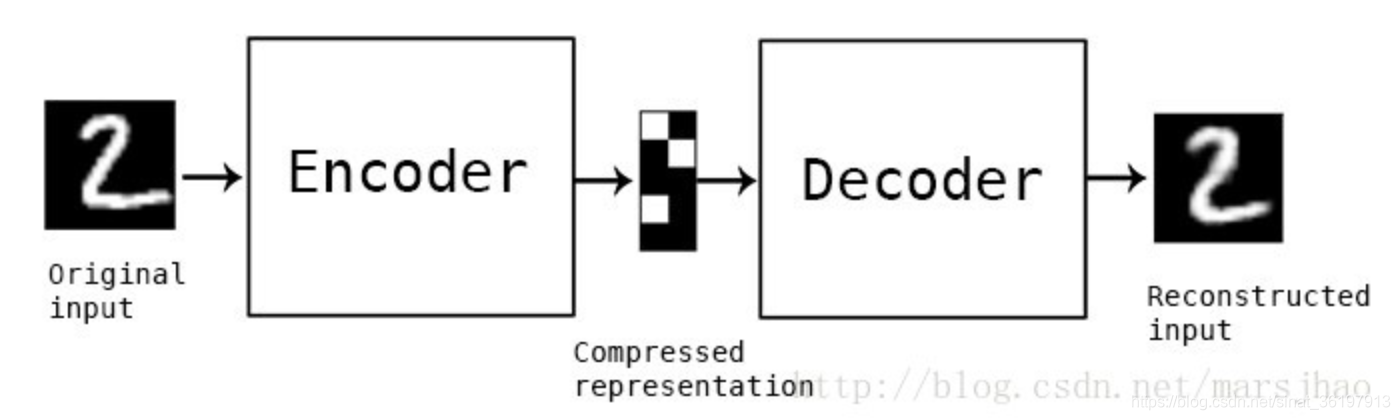
自动编码器是一种数据的压缩算法,其中数据的压缩和解压缩函数是数据相关的、有损的、从样本中自动学习的。在大部分提到自动编码器的场合,压缩和解压缩的函数是通过神经网络实现的。
- 自动编码器是数据相关的(data-specific 或 data-dependent),这意味着自动编码器只能压缩那些与训练数据类似的数据。比如,使用人脸训练出来的自动编码器在压缩别的图片,比如树木时性能很差,因为它学习到的特征是与人脸相关的。
- 自动编码器是有损的,意思是解压缩的输出与原来的输入相比是退化的,MP3,JPEG等压缩算法也是如此。这与无损压缩算法不同。
- 自动编码器是从数据样本中自动学习的,这意味着很容易对指定类的输入训练出一种特定的编码器,而不需要完成任何新工作。
搭建一个自动编码器需要完成下面三样工作:搭建编码器,搭建解码器,设定一个损失函数,用以衡量由于压缩而损失掉的信息。编码器和解码器一般都是参数化的方程,并关于损失函数可导,典型情况是使用神经网络。编码器和解码器的参数可以通过最小化损失函数而优化,例如SGD。
自编码器是一个自监督的算法,并不是一个无监督算法。自监督学习是监督学习的一个实例,其标签产生自输入数据。要获得一个自监督的模型,你需要一个靠谱的目标跟一个损失函数,仅仅把目标设定为重构输入可能不是正确的选项。
目前自编码器的应用主要有两个方面,第一是数据去噪,第二是为进行可视化而降维。配合适当的维度和稀疏约束,自编码器可以学习到比PCA等技术更有意思的数据投影。
不同种类的自编码器
自编码器(Autoencoder)是神经网络的一种,经过训练后能尝试将输入复制到输出。自编码内部有一个隐藏层 h,可以产生编码(code)表示输入。该网络可以看作由两部分组成:一个由函数 h = f(x) 表示的编码器和一个生成重构的解码器 r = g(h)。如果一个自编码器只是简单地学会将处处设置为 g(f(x)) = x,那么这个自编码器就没什么特别的用处。相反,我们不应该将自编码器设计成输入到输出完全相等。这通常需要向自编码器强加一些约束,使它只能近似地复制,并只能复制与训练数据相似的输入。这些约束强制模型考虑输入数据的哪些部分需要被优先复制,因此它往往能学习到数据的有用特性。
- 欠完备自编码器。从自编码器获得有用特征的一种方法是限制 h h h的维度比 x x x小,这种编码维度小于输入维度的自编码器称为欠完备(undercomplete)自编码器。学习欠完备的表示将强制自编码器捕捉训练数据中最显著的特征。学习过程可以简单地描述为最小化一个损失函数 L ( x , g ( f ( x ) ) ) L(x,g(f(x))) L(x,g(f(x))),其中 L L L是一个损失函数,惩罚 g ( f ( x ) ) g(f(x)) g(f(x))与 x x x的差异,如均方误差。
- 去噪自编码器。去噪自编码器(denoisingautoencoder, DAE)最小化 L ( x , g ( f ( ˜ x ) ) ) L(x,g(f(˜ x))) L(x,g(f(˜x))),其中 ˜ x ˜ x ˜x是被某种噪声损坏的 x x x的副本。因此去噪自编码器必须撤消这些损坏,而不是简单地复制输入。
VAE:变分自编码器
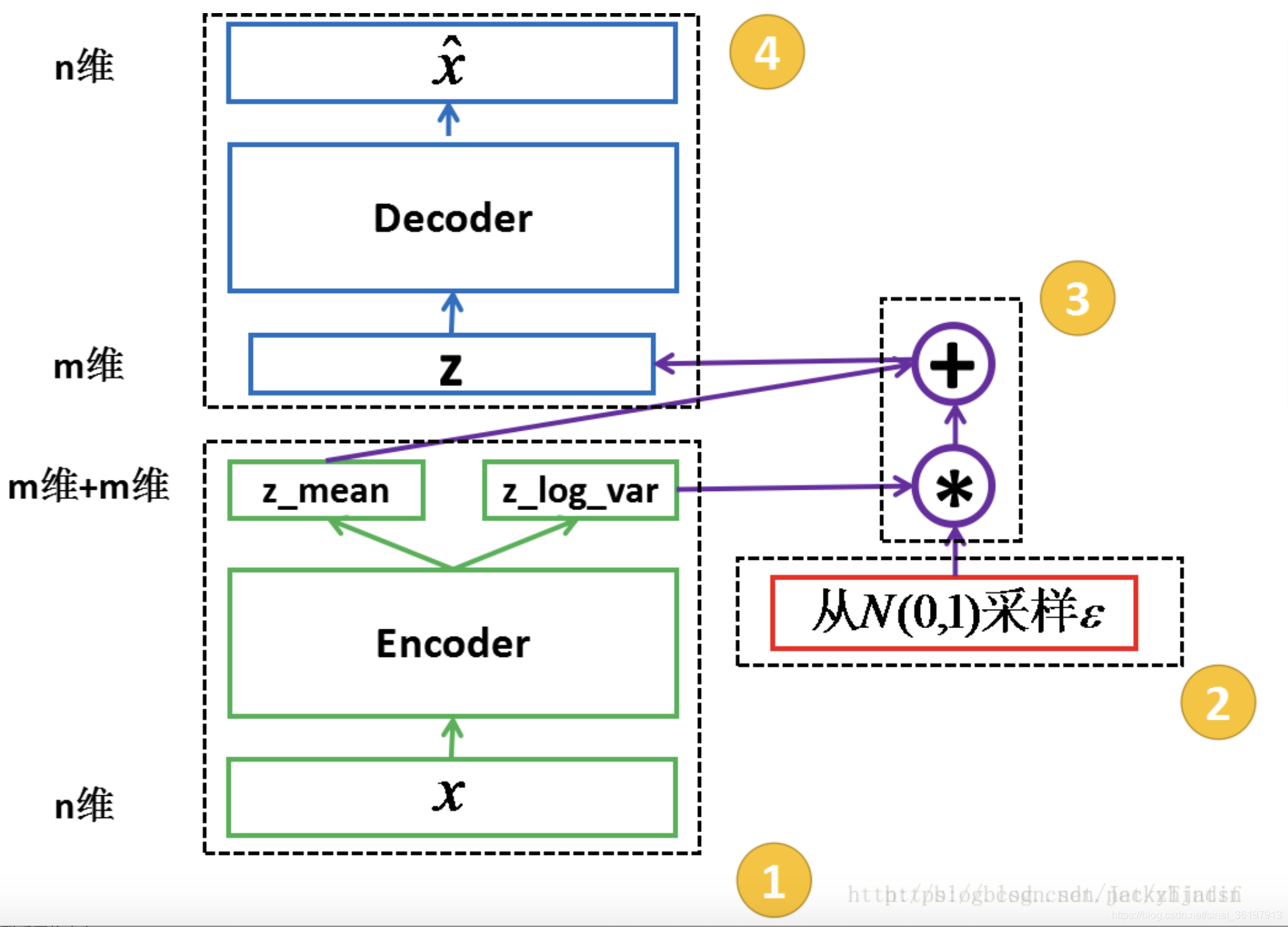
相比于自编码器,VAE更倾向于数据生成。只要训练好了decoder,我们就可以从标准正态分布生成数据作为解码器的输入,来生成类似但不同于训练数据的新样本,作用类似GAN。
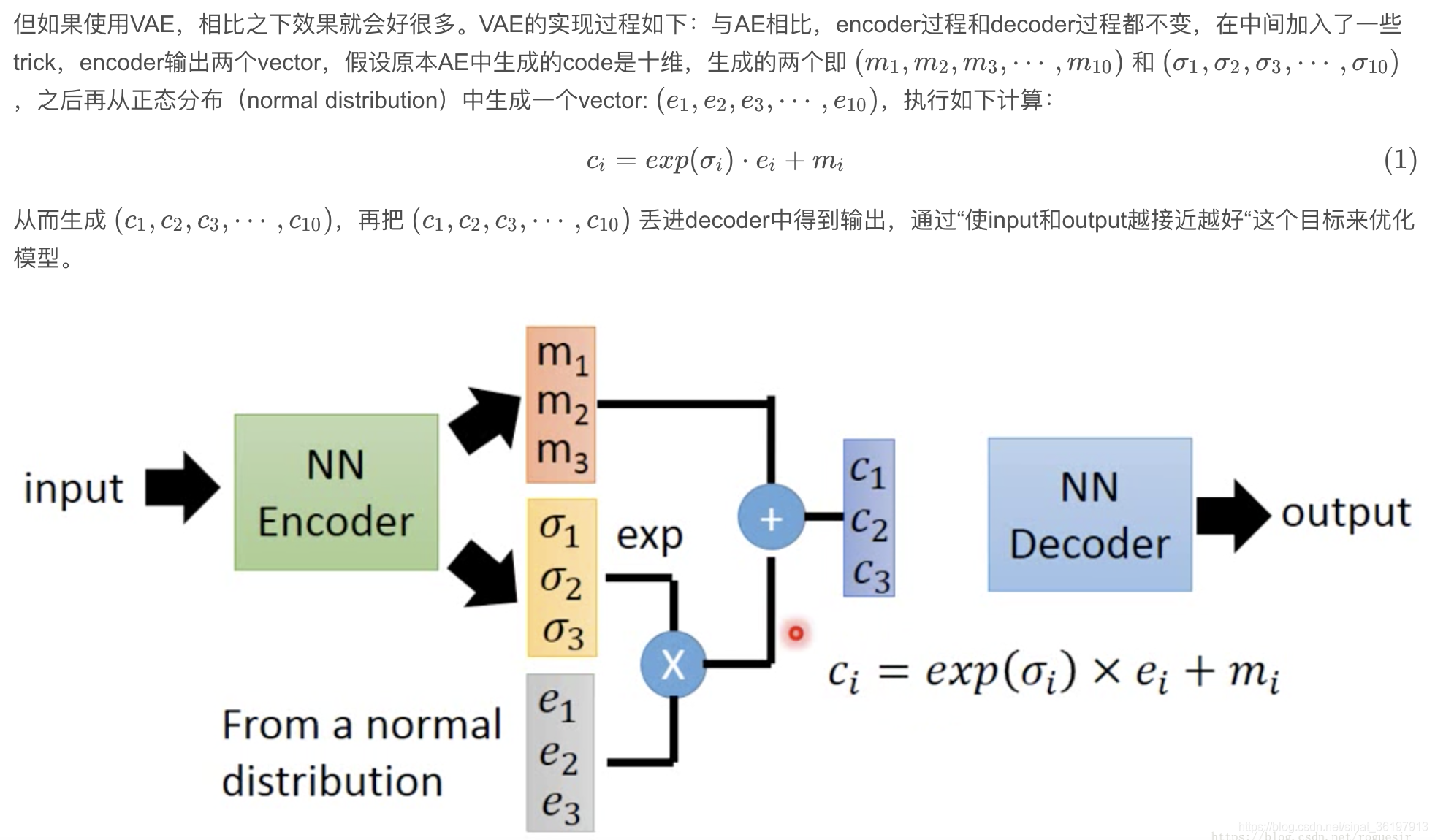
实际上,在AE的基础上通过encoder产生的向量,可以这么理解:
假如在AE中,一张满月的图片作为输入,模型得到的输出是一张满月的图片;一张弦月的图片作为输入,模型得到的是一张弦月的图片。当从满月的code和弦月的code中间sample出一个点,我们希望是一张介于满月和弦月之间的图片,但实际上,对于AE我们没办法确定模型会输出什么样的图片,因为我们并不知道模型从满月的code到弦月的code发生了什么变化。
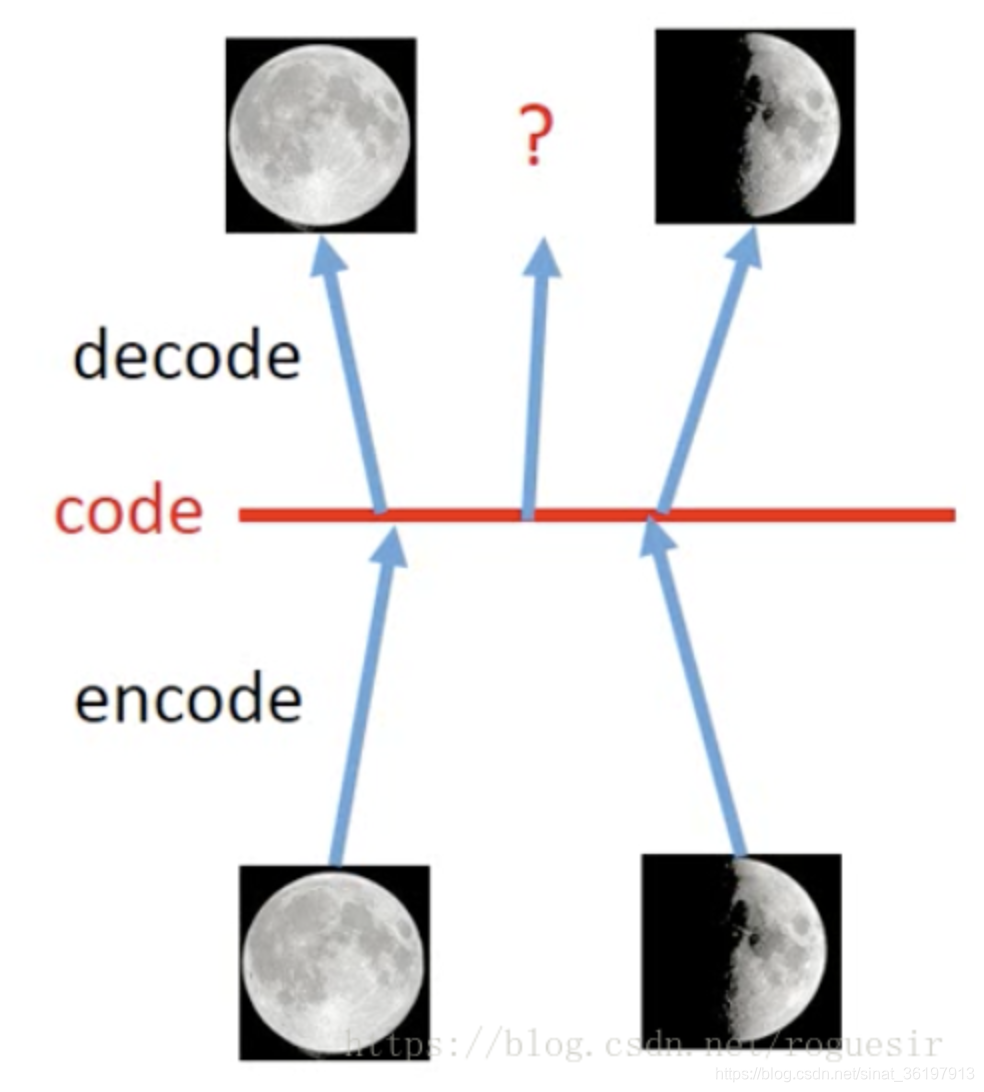
而VAE做的事情,实际上就是在原本满月和弦月生成的code上面加了noise,即在某个数值区间内,每个点理论上都可以输出满月的图片;在某个数值区间内,每个点理论上都可以输出弦月的图片,当调整这个noise的值的时候,也就是改变了这个数值区间,如下图所示,当两个区间出现重合的公共点,那么理论上,这个点既应该像满月,又应该像弦月,因此输出的图片就应该兼具满月和弦月的图片特点,也就生成一张介于满月和弦月之间的月相,而这个月相,在原本的输入中是不存在的,即生成了新的图片。

在下面这个图中,我们通过六个因素来描述最终的人脸形状,而这些因素不同的值则代表了不同的特性:
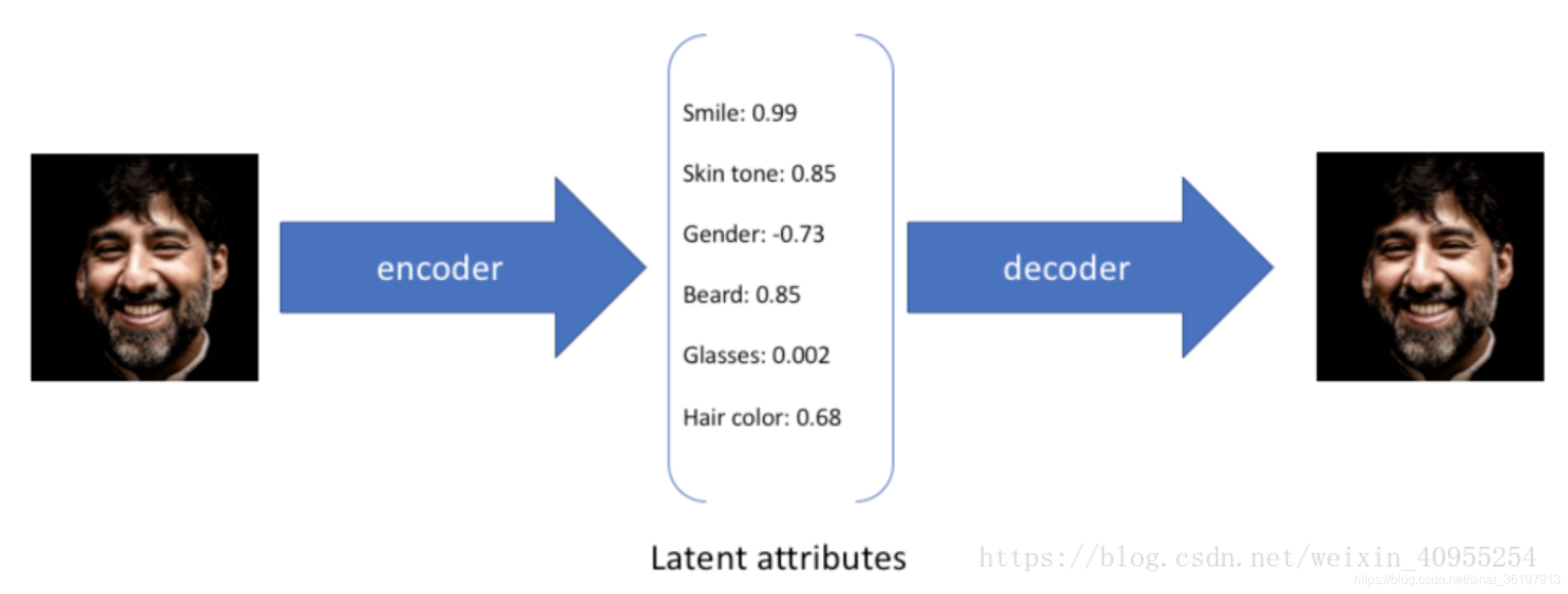
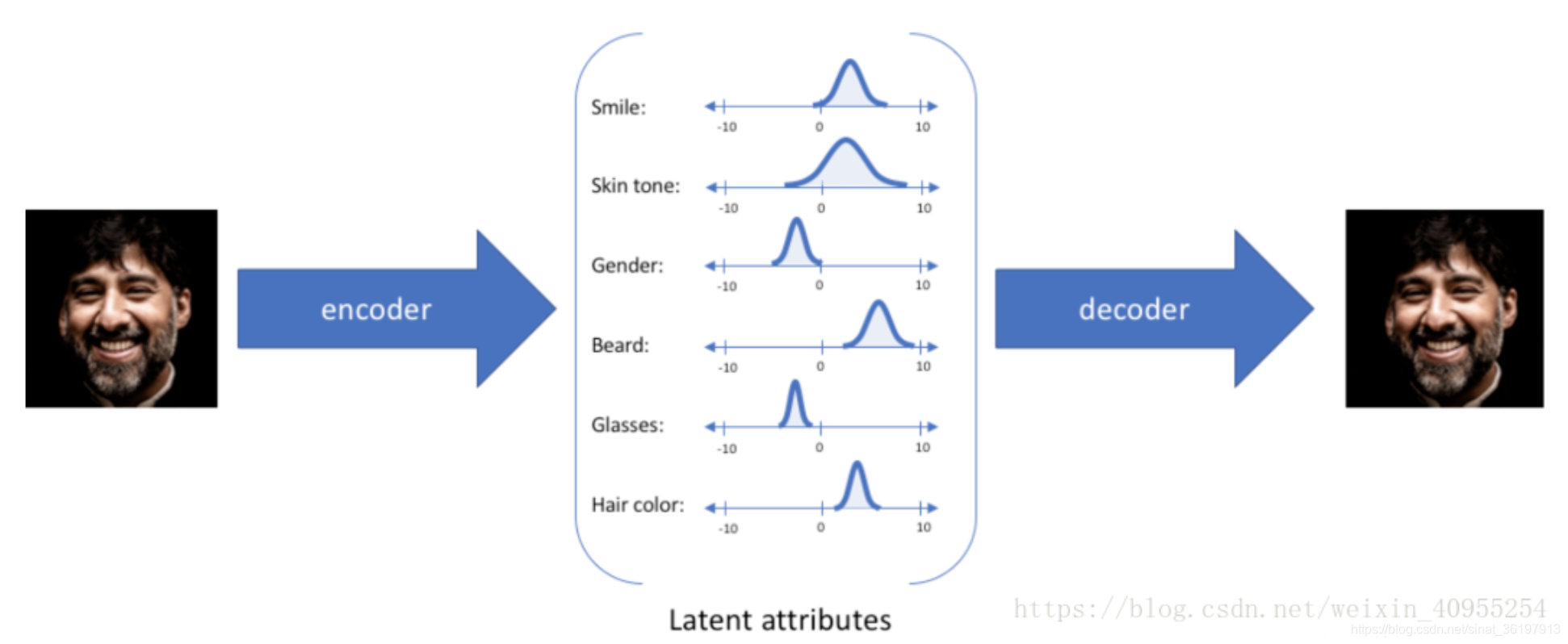
对于每个隐性参数他不会去只生成固定的一个数,而是会产生一个置信值得分布区间,这是一种连续的表达方式,通过采样,我们就可以获得许多从来没有见过的数据了。
总结
VAE和AE的差异在于:
- 两者虽然都是X->Z->X’的结构,但是AE寻找的是单值映射关系,即: z = f ( x ) z=f(x) z=f(x)。
- 而VAE寻找的是分布的映射关系,即:DX→DZ
为什么会有这个差别呢?我们不妨从生成模型的角度考虑一下。既然AE的decoder做的是 Z − > X ’ Z->X’ Z−>X’的变换,那么理论上它也可以作为生成器使用。但这里有个问题,显然不是所有的RZ都是有效的Z。Z的边界在哪里?如何得到有效的Z,从而生成 x x x?这些都不是AE能解决的。VAE映射的是分布,而分布可以通过采样得到有效的z,从而生成相应的 x x x。
三篇最新技术3D点云
什么是PCA? |