这篇教程基于PaddlePaddle框架利用RNN(循环神经网络)生成古诗句写得很实用,希望能帮到您。
基于PaddlePaddle框架利用RNN(循环神经网络)生成古诗句
在本项目中,将使用PaddlePaddle实现循环神经网络模型(即RNN模型,以下循环神经网络都称作RNN),并实现基于RNN语言模型进行诗句的生成。
本项目利用全唐诗数据集对RNN语言模型进行训练,能够实现根据输入的前缀诗句,自动生成后续诗句。
本实验所用全唐诗数据集下载地址:https://pan.baidu.com/s/1OgIdxjO2jh5KC8XzG-j8ZQ
1.背景知识
RNN是一个序列模型,基本思路是:在时刻t,将前一时刻t−1的隐藏层输出和t时刻的词向量一起输入到隐藏层从而得到时刻t的特征表示,然后用这个特征表示得到t时刻的预测输出,如此在时间维上递归下去。可以看出RNN善于使用上文信息、历史知识,具有“记忆”功能。理论上RNN能实现“长依赖”(即利用很久之前的知识),但在实际应用中发现效果并不理想,研究提出了LSTM和GRU等变种,通过引入门机制对传统RNN的记忆单元进行了改进,弥补了传统RNN在学习长序列时遇到的难题。本次实验模型使用了LSTM或GRU,可通过配置进行修改。下图是RNN(广义上包含了LSTM、GRU等)语言模型“循环”思想的示意图: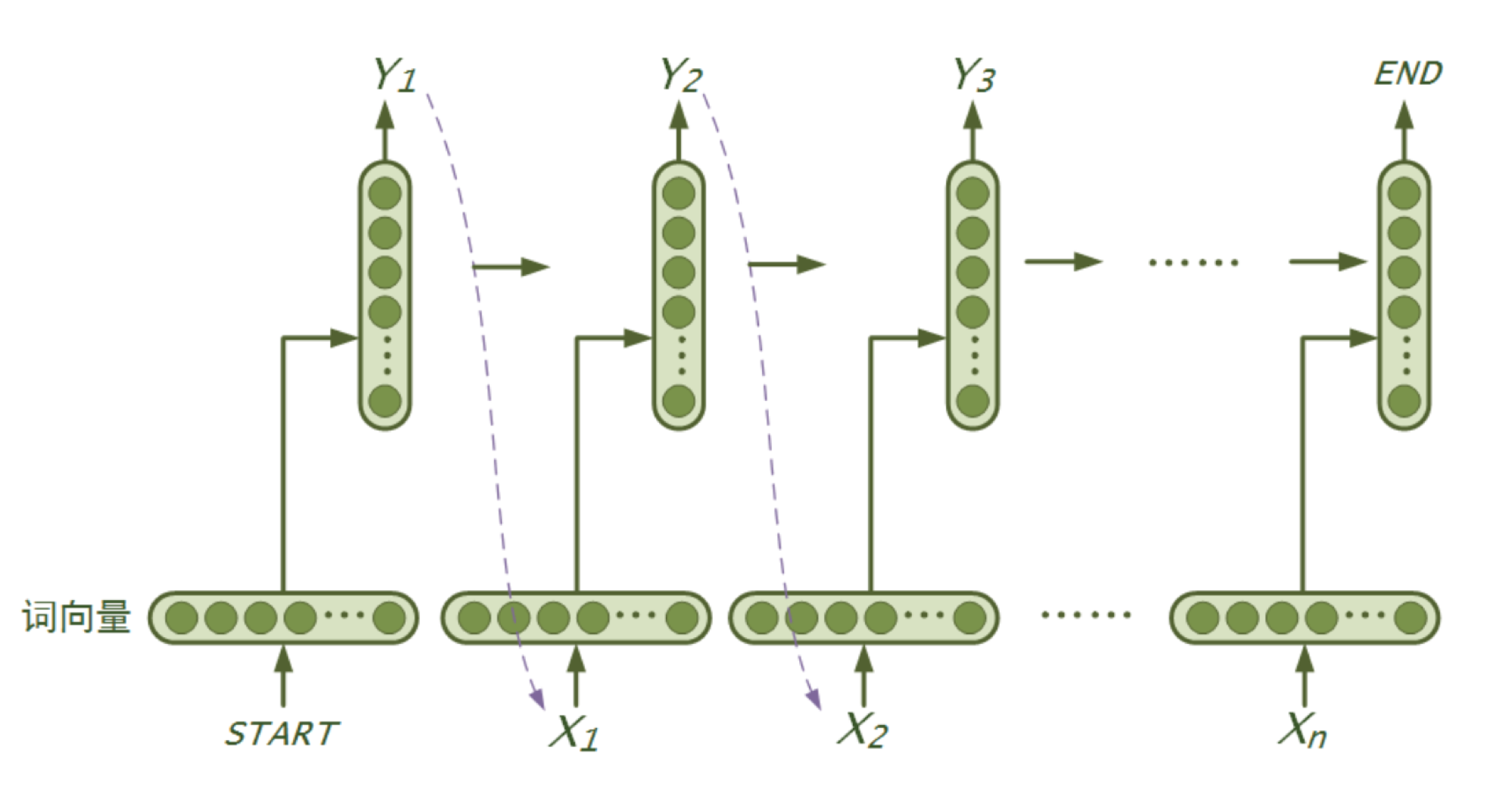
本项目要用到的RNN语言模型(Language Model)是一个概率分布模型,简单来说,就是用来计算一个句子的概率的模型。利用它可以确定生成的哪个词序列的可能性更大,或者给定若干个词,可以预测下一个最可能出现的词。基于RNN语言模型的特点,因此,我们打算利用该模型进行古诗句的生成。
另外,语言模型也是自然语言处理领域里一个重要的基础模型。
简单了解以上原理后,我们就可以正式开始本项目了。
数据预处理:
这里简单介绍数据集及其结构。本实验使用的全唐诗数据集,数据集以txt文件的形式存储,已经过以下初步处理并直接提供。
- 清洗语料:去除了数据集中的诗的标题、标点符号、注释、乱码及特殊符号等。
- 内容格式:每首诗占一行;每行中的各个字之间使用一个空格符分开。
数据集样式为:

2.项目实现过程
2.1 引入相关库 
1 import os
2 import sys
3 import gzip
4 import collections
5 import logging
6 from collections import defaultdict
7 import numpy as np
8 import math
9 import config as conf #config.py中定义了模型的参数变量
10
11 import paddle.v2 as paddle
2.2 设置默认logging配置
1 #设置默认logging配置
2 logger = logging.getLogger("paddle")
3 logger.setLevel(logging.DEBUG)
2.3 定义构建字典函数
1 #定义构建字典函数
2 def build_dict(data_file,
3 save_path,
4 max_word_num,
5 cutoff_word_fre=5,
6 insert_extra_words=["<unk>", "<e>"]):
7 #使用defaultdict()任何未定义的key都会默认返回一个默认值,避免在使用不存在的key时dict()返回KeyError的问题。
8 word_count = defaultdict(int)
9 with open(data_file, "r") as f:
10 for idx, line in enumerate(f):
11 if not (idx + 1) % 100000:
12 logger.debug("processing %d lines ... " % (idx + 1))
13 words = line.strip().lower().split()
14 for w in words:
15 word_count[w] += 1
16 #将字按字频排序
17 sorted_words = sorted(
18 word_count.iteritems(), key=lambda x: x[1], reverse=True)
19
20 stop_pos = len(sorted_words) if sorted_words[-1][
21 1] > cutoff_word_fre else next(idx for idx, v in enumerate(sorted_words)
22 if v[1] < cutoff_word_fre)
23
24 stop_pos = min(max_word_num, stop_pos)
25 with open(save_path, "w") as fdict:
26 for w in insert_extra_words:
27 fdict.write("%s\t-1\n" % (w))
28 for idx, info in enumerate(sorted_words):
29 if idx == stop_pos: break
30 fdict.write("%s\t%d\n" % (info[0], info[-1]))
2.4 定义加载字典函数
1 #定义加载字典函数
2 def load_dict(dict_path):
3 """
4 load word dictionary from the given file. Each line of the give file is
5 a word in the word dictionary. The first column of the line, seperated by
6 TAB, is the key, while the line index is the value.
7
8 """
9 return dict((line.strip().split("\t")[0], idx)
10 for idx, line in enumerate(open(dict_path, "r").readlines()))
11
12
13 def load_reverse_dict(dict_path):
14 """
15 load word dictionary from the given file. Each line of the give file is
16 a word in the word dictionary. The line index is the key, while the first
17 column of the line, seperated by TAB, is the value.
18
19 """
20 return dict((idx, line.strip().split("\t")[0])
21 for idx, line in enumerate(open(dict_path, "r").readlines()))
2.5 定义Beam search类
1 #定义BeamSearch类
2 class BeamSearch(object):
3 """
4 Generating sequence by beam search
5 NOTE: this class only implements generating one sentence at a time.
6 """
7
8 def __init__(self, inferer, word_dict_file, beam_size=1, max_gen_len=100):
9 """
10 constructor method.
11
12 :param inferer: object of paddle.Inference that represents the entire
13 network to forward compute the test batch
14 :type inferer: paddle.Inference
15 :param word_dict_file: path of word dictionary file
16 :type word_dict_file: str
17 :param beam_size: expansion width in each iteration
18 :type param beam_size: int
19 :param max_gen_len: the maximum number of iterations
20 :type max_gen_len: int
21 """
22 self.inferer = inferer
23 self.beam_size = beam_size
24 self.max_gen_len = max_gen_len
25 self.ids_2_word = load_reverse_dict(word_dict_file)
26 logger.info("dictionay len = %d" % (len(self.ids_2_word)))
27
28 try:
29 self.eos_id = next(x[0] for x in self.ids_2_word.iteritems()
30 if x[1] == "<e>")
31 self.unk_id = next(x[0] for x in self.ids_2_word.iteritems()
32 if x[1] == "<unk>")
33 except StopIteration:
34 logger.fatal(("the word dictionay must contain an ending mark "
35 "in the text generation task."))
36
37 self.candidate_paths = []
38 self.final_paths = []
39
40 def _top_k(self, softmax_out, k):
41 """
42 get indices of the words with k highest probablities.
43 NOTE: <unk> will be excluded if it is among the top k words, then word
44 with (k + 1)th highest probability will be returned.
45
46 :param softmax_out: probablity over the dictionary
47 :type softmax_out: narray
48 :param k: number of word indices to return
49 :type k: int
50 :return: indices of k words with highest probablities.
51 :rtype: list
52 """
53 ids = softmax_out.argsort()[::-1]
54 return ids[ids != self.unk_id][:k]
55
56 def _forward_batch(self, batch):
57 """
58 forward a test batch.
59
60 :params batch: the input data batch
61 :type batch: list
62 :return: probablities of the predicted word
63 :rtype: ndarray
64 """
65 return self.inferer.infer(input=batch, field=["value"])
66
67 def _beam_expand(self, next_word_prob):
68 """
69 In every iteration step, the model predicts the possible next words.
70 For each input sentence, the top k words is added to end of the original
71 sentence to form a new generated sentence.
72
73 :param next_word_prob: probablities of the next words
74 :type next_word_prob: ndarray
75 :return: the expanded new sentences.
76 :rtype: list
77 """
78 assert len(next_word_prob) == len(self.candidate_paths), (
79 "Wrong forward computing results!")
80 top_beam_words = np.apply_along_axis(self._top_k, 1, next_word_prob,
81 self.beam_size)
82 new_paths = []
83 for i, words in enumerate(top_beam_words):
84 old_path = self.candidate_paths[i]
85 for w in words:
86 log_prob = old_path["log_prob"] + math.log(next_word_prob[i][w])
87 gen_ids = old_path["ids"] + [w]
88 if w == self.eos_id:
89 self.final_paths.append({
90 "log_prob": log_prob,
91 "ids": gen_ids
92 })
93 else:
94 new_paths.append({"log_prob": log_prob, "ids": gen_ids})
95 return new_paths
96
97 def _beam_shrink(self, new_paths):
98 """
99 to return the top beam_size generated sequences with the highest
100 probabilities at the end of evey generation iteration.
101
102 :param new_paths: all possible generated sentences
103 :type new_paths: list
104 :return: a state flag to indicate whether to stop beam search
105 :rtype: bool
106 """
107
108 if len(self.final_paths) >= self.beam_size:
109 max_candidate_log_prob = max(
110 new_paths, key=lambda x: x["log_prob"])["log_prob"]
111 min_complete_path_log_prob = min(
112 self.final_paths, key=lambda x: x["log_prob"])["log_prob"]
113 if min_complete_path_log_prob >= max_candidate_log_prob:
114 return True
115
116 new_paths.sort(key=lambda x: x["log_prob"], reverse=True)
117 self.candidate_paths = new_paths[:self.beam_size]
118 return False
119
120 def gen_a_sentence(self, input_sentence):
121 """
122 generating sequence for an given input
123
124 :param input_sentence: one input_sentence
125 :type input_sentence: list
126 :return: the generated word sequences
127 :rtype: list
128 """
129 self.candidate_paths = [{"log_prob": 0., "ids": input_sentence}]
130 input_len = len(input_sentence)
131
132 for i in range(self.max_gen_len):
133 next_word_prob = self._forward_batch(
134 [[x["ids"]] for x in self.candidate_paths])
135 new_paths = self._beam_expand(next_word_prob)
136
137 min_candidate_log_prob = min(
138 new_paths, key=lambda x: x["log_prob"])["log_prob"]
139
140 path_to_remove = [
141 path for path in self.final_paths
142 if path["log_prob"] < min_candidate_log_prob
143 ]
144 for p in path_to_remove:
145 self.final_paths.remove(p)
146
147 if self._beam_shrink(new_paths):
148 self.candidate_paths = []
149 break
150
151 gen_ids = sorted(
152 self.final_paths + self.candidate_paths,
153 key=lambda x: x["log_prob"],
154 reverse=True)[:self.beam_size]
155 self.final_paths = []
156
157 def _to_str(x):
158 text = " ".join(self.ids_2_word[idx]
159 for idx in x["ids"][input_len:])
160 return "%.4f\t%s" % (x["log_prob"], text)
161
162 return map(_to_str, gen_ids)
2.6 定义RNN网络结构函数
1 #定义RNN网络结构函数
2 def rnn_lm(vocab_dim,
3 emb_dim,
4 hidden_size,
5 stacked_rnn_num,
6 rnn_type="lstm",
7 is_infer=False):
8 """
9 RNN language model definition.
10
11 """
12
13 # 定义输入层,input layers
14 input = paddle.layer.data(
15 name="input", type=paddle.data_type.integer_value_sequence(vocab_dim))
16 if not is_infer:
17 target = paddle.layer.data(
18 name="target",
19 type=paddle.data_type.integer_value_sequence(vocab_dim))
20
21 # 定义词向量层,embedding layer
22 input_emb = paddle.layer.embedding(input=input, size=emb_dim)
23
24 # 定义 RNN 层,预先提供“lstm"与"gru"两种类别的RNN,可在配置文件中选择 rnn layer
25 if rnn_type == "lstm": #本实验使用的是lstm
26 for i in range(stacked_rnn_num):
27 rnn_cell = paddle.networks.simple_lstm(
28 input=rnn_cell if i else input_emb, size=hidden_size)
29 elif rnn_type == "gru":
30 for i in range(stacked_rnn_num):
31 rnn_cell = paddle.networks.simple_gru(
32 input=rnn_cell if i else input_emb, size=hidden_size)
33 else:
34 raise Exception("rnn_type error!")
35
36 # 定义全连接输出层,fc(full connected) and output layer
37 output = paddle.layer.fc(input=[rnn_cell],
38 size=vocab_dim,
39 act=paddle.activation.Softmax())
40
41 if is_infer:
42 last_word = paddle.layer.last_seq(input=output)
43 return last_word
44 else:
45 cost = paddle.layer.classification_cost(input=output, label=target) #定义损失函数
46
47 return cost
2.7 定义reader及一些参数
1 # 限定读取文本的最短长度 sentence's min length.
2 MIN_LEN = 3
3
4 # 限定读取文本的最长长度 sentence's max length.
5 MAX_LEN = 100
6
7 # 定义RNNreader
8 def rnn_reader(file_name, word_dict):
9 """
10 create reader for RNN, each line is a sample.
11
12 """
13
14 def reader():
15 UNK_ID = word_dict['<unk>']
16 with open(file_name) as file:
17 for line in file:
18 words = line.strip().lower().split()
19 if len(words) < MIN_LEN or len(words) > MAX_LEN:
20 continue
21 ids = [word_dict.get(w, UNK_ID)
22 for w in words] + [word_dict['<e>']]
23 yield ids[:-1], ids[1:]
24
25 return reader
2.8 定义模型训练函数
1 # 定义模型训练函数
2 def train(topology,
3 train_reader,
4 test_reader,
5 model_save_dir="models",
6 num_passes=10):
7 """
8 train model.
9
10 """
11 # 创建训练模型参数保存目录
12 if not os.path.exists(model_save_dir):
13 os.mkdir(model_save_dir)
14
15 # 初始化 PaddlePaddle
16 paddle.init(use_gpu=conf.use_gpu, trainer_count=conf.trainer_count)
17
18 # 创建 optimizer,使用Adam优化算法
19 adam_optimizer = paddle.optimizer.Adam(
20 learning_rate=1e-3,
21 regularization=paddle.optimizer.L2Regularization(rate=1e-3),
22 model_average=paddle.optimizer.ModelAverage(
23 average_window=0.5, max_average_window=10000))
24
25 # 创建 parameters
26 parameters = paddle.parameters.create(topology)
27
28 # 创建 sum evaluator
29 sum_eval = paddle.evaluator.sum(topology)
30
31 # 创建 trainer 其中paddle.trainer.SGD() 函数定义一个随机梯度下降trainer,
32 # 配置4个参数cost、parameters、update_equation、extra_layers,它们分别表示损失函数、参数、更新公式以及评估器。
33 trainer = paddle.trainer.SGD(cost=topology,
34 parameters=parameters,
35 update_equation=adam_optimizer,
36 extra_layers=sum_eval)
37
38 # 定义 event_handler 以打印训练进度
39 def event_handler(event):
40 if isinstance(event, paddle.event.EndIteration):
41 # 每隔一个 log_period 打印一下训练信息
42 if not event.batch_id % conf.log_period:
43 logger.info("Pass %d, Batch %d, Cost %f, %s" % (
44 event.pass_id, event.batch_id, event.cost, event.metrics))
45
46 #每隔一个 log_period 保存一次训练模型参数
47 if (not event.batch_id %
48 conf.save_period_by_batches) and event.batch_id:
49 save_name = os.path.join(model_save_dir,
50 "rnn_lm_pass_%05d_batch_%03d.tar.gz" %
51 (event.pass_id, event.batch_id))
52 with gzip.open(save_name, "w") as f:
53 trainer.save_parameter_to_tar(f)
54
55 if isinstance(event, paddle.event.EndPass):
56 if test_reader is not None:
57 result = trainer.test(reader=test_reader)
58 logger.info("Test with Pass %d, %s" %
59 (event.pass_id, result.metrics))
60 save_name = os.path.join(model_save_dir, "rnn_lm_pass_%05d.tar.gz" %
61 (event.pass_id))
62 with gzip.open(save_name, "w") as f:
63 trainer.save_parameter_to_tar(f)
64 # 输出训练运行日志
65 logger.info("start training...")
66 trainer.train(
67 reader=train_reader, event_handler=event_handler, num_passes=num_passes)
68
69 logger.info("Training is finished.")
2.9 开始训练
1 # 进行训练工作
2
3 def main():
4 # 构建并加载词典文件
5 if not (os.path.exists(conf.vocab_file) and
6 os.path.getsize(conf.vocab_file)):
7 logger.info(("word dictionary does not exist, "
8 "build it from the training data"))
9 build_dict(conf.train_file, conf.vocab_file, conf.max_word_num,
10 conf.cutoff_word_fre)
11 logger.info("load word dictionary.")
12 word_dict = load_dict(conf.vocab_file)
13 logger.info("dictionay size = %d" % (len(word_dict)))
14
15 cost = rnn_lm(
16 len(word_dict), conf.emb_dim, conf.hidden_size, conf.stacked_rnn_num,
17 conf.rnn_type)
18
19 # 使用 reader
20 reader_args = {
21 "file_name": conf.train_file,
22 "word_dict": word_dict,
23 }
24 # paddle.reader.shuffle(train(), buf_size=102400)表示trainer从 rnn_reader 中读取了 buf_size=102400大小的数据并打乱顺序
25 # batch_size 表示从打乱的数据中再取出 batch_size=con.batch_size 大小的数据进行一次迭代训练
26 train_reader = paddle.batch(
27 paddle.reader.shuffle(
28 rnn_reader(**reader_args), buf_size=102400),
29 batch_size=conf.batch_size)
30 test_reader = None
31 if os.path.exists(conf.test_file) and os.path.getsize(conf.test_file):
32 test_reader = paddle.batch(
33 paddle.reader.shuffle(
34 rnn_reader(**reader_args), buf_size=65536),
35 batch_size=conf.batch_size)
36 # 正式开始训练,相关参数调用自 config.py 文件
37 train(
38 topology=cost,
39 train_reader=train_reader,
40 test_reader=test_reader,
41 model_save_dir=conf.model_save_dir,
42 num_passes=conf.num_passes)
43
44
45
46 main()
2.10 定义生成诗句函数
1 # 定义生成诗句函数
2 def rnn_generate(gen_input_file, model_path, max_gen_len, beam_size,
3 word_dict_file):
4 """
5 use RNN model to generate sequences.
6
7 """
8
9 assert os.path.exists(gen_input_file), "test file does not exist!"
10 assert os.path.exists(model_path), "trained model does not exist!"
11 assert os.path.exists(
12 word_dict_file), "word dictionary file does not exist!"
13
14 # 加载词典文件
15 word_2_ids = load_dict(word_dict_file)
16 try:
17 UNK_ID = word_2_ids["<unk>"]
18 except KeyError:
19 logger.fatal("the word dictionary must contain a <unk> token!")
20 sys.exit(-1)
21
22 # 初始化 PaddlePaddle
23 paddle.init(use_gpu=conf.use_gpu, trainer_count=conf.trainer_count)
24
25 # 加载训练好的模型
26 pred_words = rnn_lm(
27 len(word_2_ids),
28 conf.emb_dim,
29 conf.hidden_size,
30 conf.stacked_rnn_num,
31 conf.rnn_type,
32 is_infer=True)
33 # 使用训练完成的模型参数
34 parameters = paddle.parameters.Parameters.from_tar(
35 gzip.open(model_path, "r"))
36
37 inferer = paddle.inference.Inference(
38 output_layer=pred_words, parameters=parameters)
39
40 generator = BeamSearch(inferer, word_dict_file, beam_size, max_gen_len)
41 # 生成诗句文本
42 with open(conf.gen_file, "r") as fin, open(conf.gen_result, "w") as fout:
43 for idx, line in enumerate(fin):
44 fout.write("%d\t%s" % (idx, line))
45 for gen_res in generator.gen_a_sentence([
46 word_2_ids.get(w, UNK_ID)
47 for w in line.lower().strip().split()
48 ]):
49 fout.write("%s\n" % gen_res)
50 fout.write("\n")
51
52
53
54 rnn_generate(conf.gen_file, conf.model_path, conf.max_gen_len,
55 conf.beam_size, conf.vocab_file)
2.11 打印生成的诗句
1 # 查看看一下生成的诗句效果
2 print("生成诗句展示:\n")
3 for i in open("data/gen_result.txt"):
4 print i
生成的诗句展示:
0 黄 河 远 上 白 云 间
-12.4769 今 日 逢 君 泪 满 缨
-12.7528 今 日 逢 君 泪 满 衣
-13.8208 今 日 逢 君 泪 满 巾
-13.8563 今 日 将 军 汉 水 边
-14.0999 今 日 逢 君 不 见 春
1 羌 笛 何 须 怨 杨 柳
-8.9801 不 知 何 处 草 萋 萋
-9.3334 不 知 何 处 是 春 风
-10.4879 不 知 何 处 是 花 枝
-11.1031 不 知 人 不 知 何 人
-11.2889 不 知 何 处 是 春 山
2 无 边 落 木 萧 萧 下
-12.0765 日 暮 孤 舟 何 处 来
-12.5019 独 自 撄 宁 逆 鼓 鼙
-13.0668 日 暮 孤 舟 何 处 期
-13.7688 日 暮 孤 舟 何 处 村
-13.8054 日 暮 孤 舟 何 处 寻
3 凤 凰 台 上 凤 凰 游
-14.9325 年 少 恩 深 万 岁 同
-14.9472 年 少 恩 华 事 可 知
-15.1605 年 少 恩 深 万 里 馀
-15.1802 年 少 恩 深 万 里 同
-15.1948 年 少 恩 深 万 里 人
4 日 出 江 花 红 胜 火
-10.9732 春 风 袅 袅 百 花 枝
-11.9631 春 风 袅 袅 春 风 起
-12.2523 春 风 袅 袅 满 池 塘
-12.8227 春 风 袅 袅 百 花 时
-12.9489 春 风 袅 袅 百 花 飞
3.相关补充
对于导入模块与库过程中,引入的config.py文件,其全部代码如下,可以根据自己的语料与期望生成调整相关参数,其中examples.txt文件可自拟,但是由于本项目是按字训练,因此examples.txt文件要注意每两字之间用空格隔开:
1 import os
2
3 ################## for building word dictionary ##################
4
5 max_word_num = 51200 - 2
6 cutoff_word_fre = 0
7
8 ################## for training task #########################
9 # path of training data
10 train_file = "data/poetrys.txt"
11
12 # path of testing data, if testing file does not exist,
13 # testing will not be performed at the end of each training pass
14 test_file = ""
15
16 # path of word dictionary, if this file does not exist,
17 # word dictionary will be built from training data.
18 vocab_file = "data/word_vocab.txt"
19
20 # directory to save the trained model
21 # create a new directory if the directoy does not exist
22 model_save_dir = "models"
23
24 batch_size = 32 # the number of training examples in one forward/backward pass
25 num_passes = 50 # how many passes to train the model
26
27 log_period = 50
28 save_period_by_batches = 50
29
30 use_gpu = False # to use gpu or not
31 trainer_count = 1 # number of trainer
32
33 ################## for model configuration ##################
34 rnn_type = "lstm" # "gru" or "lstm"
35 emb_dim = 256
36 hidden_size = 256
37 stacked_rnn_num = 2
38
39 ################## for poetry generation ##################
40 gen_file = "data/examples.txt"
41 gen_result = "data/gen_result.txt"
42 max_gen_len = 7 # the max number of words to generate
43 beam_size = 5
44 model_path = "models/rnn_lm_pass_00044_batch_750.tar.gz"
45
46 if not os.path.exists(model_save_dir):
47 os.mkdir(model_save_dir)
python在线学习
基于python语言,自动生成文章摘要(中文) |