现在市场对机器学习的热情居高不下,“机器学习”和“深度学习”正处于2017新科技兴起衰落周期循环(Gartner Hype Cycle)的顶端。Wired杂志的Kevin Kelly甚至说未来10000家初创企业的业务规划很容易预测:某个未知项目再加上人工智能”。虽然这说起来容易但做起来难,医学是这一技术颠覆的主要候选者,因为它天然拥有大量数据,且这些数据还未得到充分利用。在某种程度上按数量来说,医学图像又构成了医学数据中的主要部分。
正如许多人对人工智能带来的潜在危机和即将到来的大规模失业所担忧的一样,放射学家的未来也面临着类似的严峻问题。去年深入学习的教父Geoffrey Hinton教授说,“我们现在就应该停止培训放射学家”,他把放射学家比作郊狼,站在悬崖的边上,不知道脚下是万丈深渊。

北美放射学会( RSNA )和加拿大放射学家协会( CAR )等大型组织已经意识到这一点,他们没有因为恐惧而拒绝这一新兴技术,而是正视它直面挑战,并将这一技术作为即将召开会议的主题。

今年,RSNA举办了一次全球机器学习竞赛,旨在开发根据儿童手部x光片预测骨骼年龄的最佳算法。获取生长异常或激素分泌异常的儿童患者手部x光片,将他们的骨骼年龄与实际年龄进行比较,以确保他们处于生长发育的正常范围内。一般将正常范围定义为该年龄平均值加减两个标准偏差以内。1959年,W. W. Greulich和S.I. Pyle出版了他们的第二版《手和手腕骨骼发育的放射图谱》,该图谱是根据Brush基金支持的“人类生长和发育”的研究编写而成,该研究在1929年由Western Reserve大学医学院的T. Wingate Todd教授完成。

虽然前期已经开发了骨龄分析的自动化方法并且这些方法现在已经上市,但是没有一种方法是可以广泛使用的。放射科医生在每次面对骨龄研究遇到困难时,都要翻查Greulich和Pyle图谱以找到最相似的例子。相比与这种笨拙费时的方法,在人工智能的热潮中,机器学习却能毫不费力地实现骨龄自动化分析。
接下来我们看下Mark Cicero 和 Alexander Bilbily是如何解决这个问题的,他们在200次图像测试中,获得了4.265个月的平均绝对差异( MAD ),并在比赛中名列前茅。
数 据
比赛的数据来自美国两家医院贡献给RSNA的12612个训练样本,这些图像标注有以月为单位的骨骼年龄和患者性别的标签。首先需要确定的是,训练两个神经网络(每个性别一个)还是训练一个某种程度上包含性别信息作为输入内容的神经网络。骨骼成熟程度因性别而异,女性的比男性的骨骼成熟快得多,差异最长可达2年,并且女性青春期开始的更早。忽略这一根本差异将立即妨碍神经网络的表现。在架构部分中,将详细介绍这方面的方法。
其次需要确定的是输入图像的分辨率。标准网络体系结构通常接受8位RGB格式的256×256像素的图像。比赛提供的图像是8位灰度格式,大小约为2000 x 1500像素( 3 MP )。要是放射科医师在256×256像素图像上确定骨骼年龄则得到的诊断结果不会太好,因此要求机器这样做,可能也不会产生最佳结果。相反,放射学家执行该任务不需要看完所有的300万像素,训练能够适应这种输入大小的大型神经网络也将充满其他挑战。因此,Mark Cicero 和 Alexander Bilbily尝试了各种分辨率的图像,最高为750 x 750像素。最终结合数据集和可用的GPU内存,确定了500 x 500像素是解决问题的最佳尺寸。
将提供的数据按照训练:验证=85 : 15的比例进行拆分,生成10720个训练图像和1892个验证图像。考虑到数据集相对较小,Mark Cicero 和 Alexander Bilbily同时扩展了训练集,以最大限度的增加网络学习的范例数量。为了弥补小验证集合的缺点,他们在预测阶段平均几个最佳模型的结果 (下面将详细介绍)。他们没有指定测试集,因为有数据中1425个没有标签的附加图像可服务于此功能。数据归一化并没有在整个集合上使用,因为使用的架构采用了批量归一化,并且证明在减少内部协变量偏移方面是有效的。
架 构
实践中最佳模型结合了Inception V3网络来处理图像输入。他们也尝试了许多其他流行的网络,包括Inception V4、ResNet 152、densent和Inception v3 _SE。Keras提供了许多现成的架构,对测试非常有用。他们对网络进行了修改,从初始V3网络中最后一个级联层后提取一层,将其展平,并将其与性别网络连接,该性别网络用来输入二进制性别信息(女性为0,男性为1 ),并通过32神经元密集连接层对其进行馈送。在最终的单输出线性层之前,级联层通过具有“relu”激活的另外两个1000神经元密集连接层被馈送。
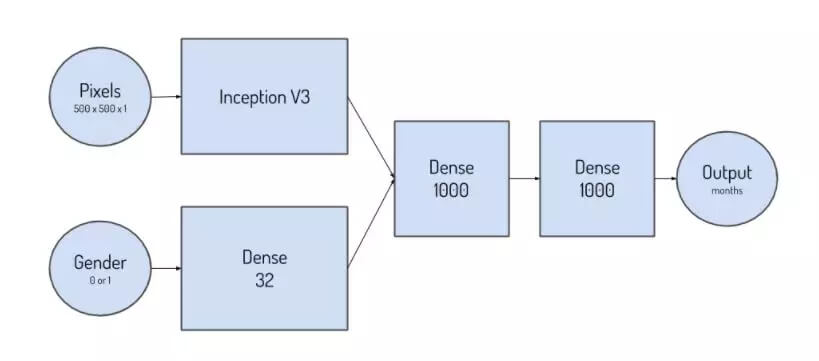
这种设计的动机源于每个输入(像素和性别)对最终决策的相对贡献。在链接层,像素贡献100384个输入,而性别贡献32个输入。之所以选择这个比率,是因为不想网络过分偏向于性别输入,而是希望赋予它影响总体预测的能力。额外的全连接层给网络更多可学习的参数,以便在训练期间进行调整,从而使其能够推断像素和性别信息之间的关系。
每个月的单个数字输出而不是区分开的类别输出会更加直观,并且可以避免相似的类别一起激活。多类别输出效果可能不会太好,因为它不会利用骨龄值之间的顺序关系,但是,Mark Cicero 和 Alexander Bilbily没有测试这一点。
Mark Cicero 和 Alexander Bilbily进行了40多次实验,内容涉及架构、数据集、优化器、批处理大小、损失函数和超参数。他们在Python 3.4运行的后端上将Keras 2.08与TensorFlow 1.3结合使用。在两台机器上运行这些实验,一台装有NVIDIA P40和两个Titan X GPU,另一台装有单个Titan X。没有使用数据或并行模型 (即每个实验都在单个GPU上运行)。也没有使用任何预先训练的模型,因为他们的输入图像大于常规使用的大小,并且数据集足够大,可以使用随机初始化的网络有效地解决问题。
500 x 500像素数据集、性别信息和标签在运行时加载到内存中。将整个数据集存储在内存中还可以使用 Keras 图像数据生成器对整个数据集进行实时数据增强。对于训练集,他们使用了20度的旋转范围,水平/垂直平移20 %,缩放20 %和水平翻转来进行数据增强,但未对验证集进行增强。这些值是根据“放射科医师格式塔法则”来选择的,即基于图像与图像之间的实际差异是什么。
train_datagen = ImageDataGenerator(rotation_range=20, width_shift_range=0.2, height_shift_range=0.2, zoom_range=0.2, horizontal_flip = True)
在没有增强情况且250×250像素的分辨率下,他们实现了8-9个月间MAE。实时增强不仅极大地增加了数据集从而改进了学习,而且选择的每个变换都提高了泛化能力。通过这样的方法迫使网络去学习样本的内在的特征,而不是成像技术。用于分析的儿童手部的图像可以改变大小位置,进行旋转,转变左右手,而这些因素不会影响算法分析图像的能力。
最后,他们最终模型进行了500个周期(约50小时)minibatch为16的小批量训练,使用ADAM优化器尝试使输出的平均绝对误差最小化。当验证失去稳定时,降低学习率。
optim = optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)
reduceLROnPlat = ReduceLROnPlateau(monitor=’val_loss’, factor=0.8, patience=10, verbose=1, mode=’auto’, epsilon=0.0001, cooldown=5, min_lr=0.0001)
他们认为“你无法改进你不能测量的物体”,Mark 和 Alexander认为在整个训练过程中必须监控模型的一致性相关系数( Concordance Correlation Coefficient CCC ),这个他们在决赛中使用了这一度量,因此他们编写了一个定制的Keras回调函数在整个训练过程中实现这一点。
最好的三个模型在验证集上都达到了5.99个月的MAD。排在第四第五的模型实现了6.00和6.04个月的MAD。CCC保持在0.98 – 0.99之间。
推 断
在类似的竞赛中存在多种推断技术来改进模型性能,甚至增量改进也是有利的。许多论文参考了一个10-crop-validation方案,这个方案随机剪切模型和平均化模型的预测,以减少局外点预测的影响。Mark Cicero 和 Alexander Bilbily设计了一个类似的计划,帮助这个模型在Keras上成为一个生成器。通过一些实验,他们发现以下参数可以产生最佳结果。
val_datagen = ImageDataGenerator(width_shift_range=0.25, height_shift_range=0.25, horizontal_flip = True)
他们通过生成器为排名前五的模型生成10个样本,从而为每个测试图像生成50个预测结果。然后对结果求平均并四舍五入到最接近的整数,得出最终预测。
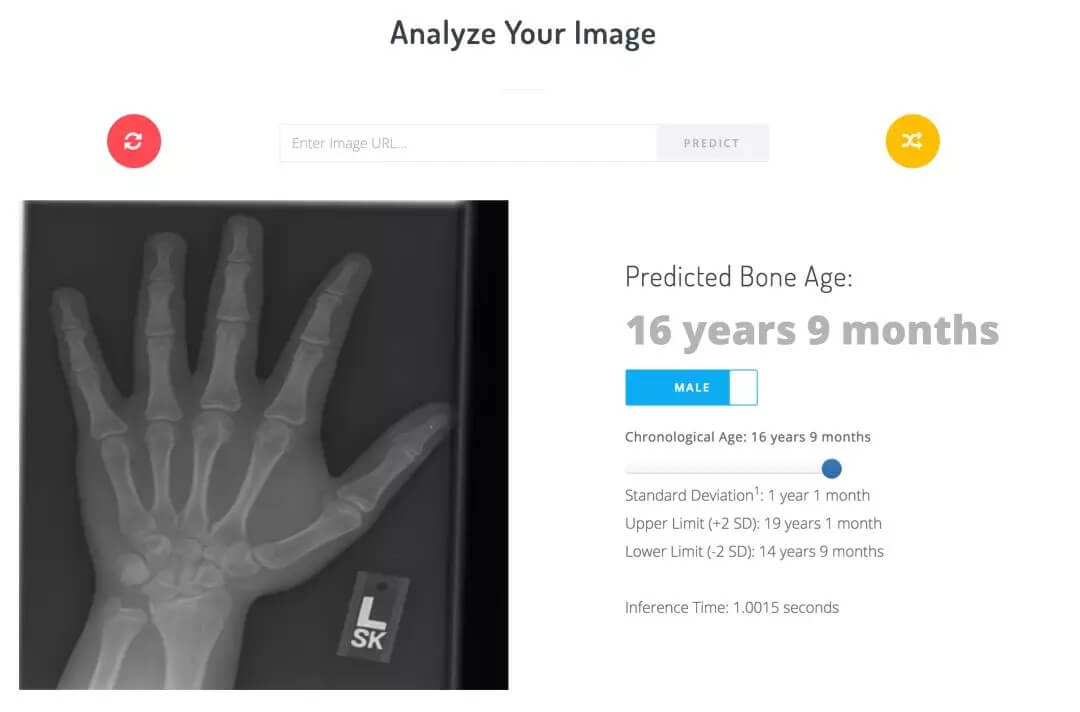
他们设置了一个实时网络演示,该演示在Flask服务器上运行了一个训练过的模型。使用者可以通过浏览器上传自己的图像,在移动设备上拍照上传,或从测试集中随机选取图像进行分析。
结 论
Larson等人对测试集中不同观察者的观察差异进行了广泛的统计分析,并由另外三名儿科放射科医师独立审阅。他们发现,一名观察者与其他观察者的平均MAD介于0.53至0.69年( 6.36至8.28个月)之间,平均为0.61年( 7.32个月)。 而Mark Cicero 和 Alexander Bilbily的算法实现了0.36年( 4.265个月)的MAD,是不是真被说对了?我们针对不需要培训放射科医师吗?
我们认为这并不是事实的原貌。记住AI是使用数据解决特定问题的算法和方法的集合,这一点至关重要。放射科医师是未来医学人工智能的关键,因为他们最适合识别、指导和应用人工智能,以解决当今医学成像面临的最具影响力的临床问题。医学影像学已经成为医学的基石,几乎每一个医学专业都依赖它来诊断、排除或监测多种疾病,然后再做出治疗决定。在活跃的放射学研究领域的推动下,我们继续拓宽我们的视野,并为不断增长的临床环境创造价值。智能工具不是预示着我们的消亡,而是通过提高效率和帮助我们保持同样高的准确性和质量,来扩大我们作为专业人员的研究方向和影响力。机器学习、深度学习、人工智能(无论你想称之为什么)将成为下一代工具的基础,并最终使我们能够为患者提供更快、更好、更可靠的护理。
事实上,我们需要继续培训放射学家来实现这个惊人的健康领域的新纪元。智能分类算法将允许实现以前不可行的癌症筛查计划;增强的后端工具能够在获得患者扫描结果时迅速发现的潜在急性病症立即通知给转诊临床医生;挖掘大型成像和临床数据集可能会揭示人类从未考虑过的新因素,这一系列工具能为医学影像带来的优势不胜枚举……对于放射科医师来说,这是一个激动人心的时刻,因为我们创造的价值只有通过这种新技术才能得到放大造福更多的人。但最后还是要给出一个忠实的建议——放射科医师要积极地拥抱变革的浪潮,不能落后于时代的潮流。
分析网站:https://www.16bit.ai/bone-age
一些参考链接: https://www.16bit.ai/blog/ml-and-future-of-radiology
[1] https://www.gartner.com/smarterwithgartner/top-trends-in-the-gartner-hype-cycle-for-emerging-technologies-2017/
[2] https://www.youtube.com/watch?v=2HMPRXstSvQ
[3] http://rsnachallenges.cloudapp.net/competitions/4#learn_the_details
[4] https://www.amazon.ca/Radiographic-Atlas-Skeletal-Development-Wrist/dp/0804703981
[5] Lee, H., Tajmir, S., Lee, J. et al. J Digit Imaging (2017) 30: 427. https://doi.org/10.1007/s10278-017-9955-8
[6] Ioffe, Sergey, and Christian Szegedy. “Batch normalization: Accelerating deep network training by reducing internal covariate shift.” arXiv preprint arXiv:1502.03167 (2015)