这篇教程基于CNN-BiLSTM和注意力机制的知识图谱补全的路径推理方法写得很实用,希望能帮到您。
原文
Path-based reasoning approach for knowledge graph completion using CNN-BiLSTM with attention mechanism
出版
Expert Systems With Applications 142 (2020) 112960
代码
github
摘要
知识图谱是构建智能系统(如问答或推荐系统)的宝贵资源。然而,大多数知识图都受到实体间关系缺失的影响。将实体和关系转换到低维空间的嵌入方法取得了很大的成果,但它们只关注实体之间的直接关系,而忽略了图中路径关系的存在。相反,基于路径的嵌入方法考虑单一路径来进行推断。它还依赖于简单的递归神经网络,这种高效的神经网络模型可用于处理序列数据。
我们提出了一种新的知识图谱补全方法,该方法将双向长短期记忆网络(BiLSTM)和卷积神经网络模块与注意机制相结合。给定一个候选关系和两个实体,我们使用卷积运算将连接实体的路径编码到一个低维空间,接着使用BiLSTM。然后,应用注意层来捕获候选关系和两个实体之间的每条路径之间的语义相关性,并从多条路径的表征中基于注意力地提取推理证据,以预测实体是否应该通过候选关系连接。
我们扩展了我们的模型,对嵌入空间中的路径表征进行多步推理。递归神经网络被设计为重复地与注意力模块交互,以从多条路径的表征中导出逻辑推理。我们在几个知识图上执行链接预测任务,并表明我们的方法与最近的最先进的路径推理方法相比取得了更好的性能。
方法
整体架构
本文提出的方法的整体框架如下图所示:

首先,给定一个候选关系和两个实体,我们的方法使用CNN算法将实体之间的多个推理路径编码成低维嵌入,然后将数据通过BiLSTM层。与此同时,我们假设不是两个实体之间的所有路径都同样有助于推断实体之间的缺失关系。为此,我们应用注意力机制捕获候选关系和两个实体之间的每条路径之间的语义相关性,并为实体之间的所有路径生成向量表示,并且将连接实体的不同长度的路径被编码成固定长度的实值向量。最后,关系嵌入和路径的向量表征的总和通过一个全连接层输出,来预测两个实体是否应该通过候选关系连接。T
寻找路径
给定图中的三元组和训练的三元组,使用PRA算法执行随机游走从而给训练三元组计算出一组有限长度的路径。
先在整个图上进行随机游走,从源实体开始到达目标实体,同时记录连接源实体和目标实体的关系。我们得到多条关系路径,得到的关系路径p包含一系列关系,{ r1, r2, ... , rl}。然后,给定从源实体es开始的随机行走,我们计算到达目标实体et(并且精确地遵循p中的所有关系)的随机游走概率。一旦计算出每个关系路径的随机行走概率,具有高概率的路径被选择作为潜在的路径特征。然后,我们通过包含中间实体进一步将所有关系路径p扩展为完整路径π,使得π = {es, r1, e1, ..., rl, et}。
卷积层
我们使用一维卷积在路径序列上面滑动多个具有相同窗口大小的滤波器来生成特征,滑动窗口大小为3,最终卷积算子的输出向量被传递给BiLSTM。
BiLSTM层
BiLSTM由两部分组成,即前向LSTM和后向LSTM。前项LSTM从左到右读取路径中的序列,后项的LSTM从右到左读取路径中的序列。嵌入向量m由路径的正向和反向信息组成,以有效地获取其顺序。
注意力层
在此之前,我们需要通过一个输入模块对查询的关系进行编码,并将其转换成一个向量表示,比如u。接下来,将关系的嵌入与编码路径进行匹配,通过注意力机制,计算每条路径的权重分数。每个路径嵌入mi被分配一个权重,以表示关系r和路径πi之间的语义相似性。最后对各条路径使用加权求和的运算来组合编码的路径向量,产生一个状态向量o。
全连接层
最后,将关系嵌入u和路径嵌入输出的状态向量o通过一个全连接层,来预测在源实体和目标实体之间所选的候选关系是否成立,具体公式如下:
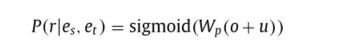
多步推理
多步推理流程框架图如下:
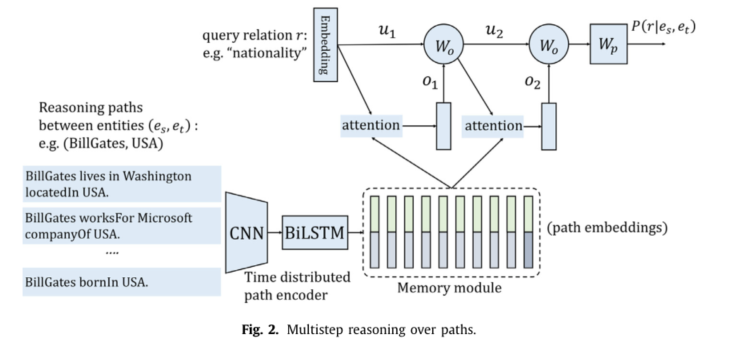
在经过BiLSTM层之后,会经历多次的注意力层迭代,第z次的注意力层的输出o(z)会和u(z)求和然后经过一个权重矩阵W0,生成新的u(z+1),其中初始的u(0)是候选关系r的嵌入u。最后迭代次数完成以后,经历和之前单步推理相同的全连接层,具体多步推理两层的公式如下:
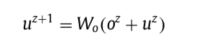
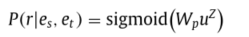
损失函数与优化器
本文的损失函数使用的是二元交叉熵,优化器使用Adam。
交叉熵是很有名的多分类损失函数,二元交叉熵就是其在二分类中的应用,具体解释可以查看链接,其具体公式如下:

Adan也很常见,是自适应梯度下架算法,它能够对每个不同的参数调整不同的学习率,对频繁变化的参数以更小的步长进行更新,而稀疏的参数以更大的步长进行更新。具体公式如下:

评估
数据集
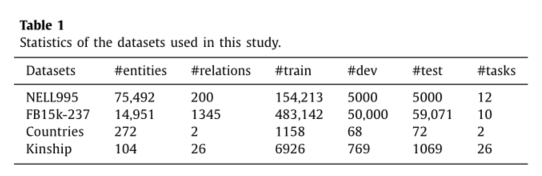
本文评估使用了4个经典的知识图谱,NELL995, FB15k-237, Countries, Kinship, 具体信息如下:
实验结果
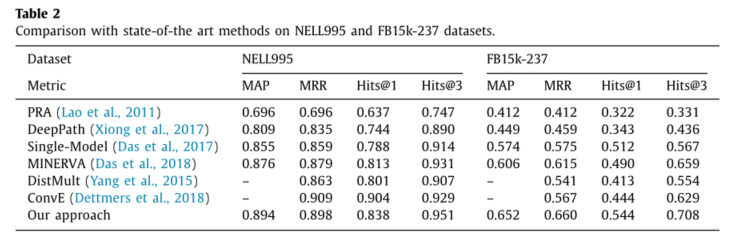
我们的方法,还与近期比较优秀的知识图谱补全方法进行了对比,最终结果如下:

结论
- 在我们的实验中,我们在所有评估指标上都取得了与最先进方法相当的结果。
- 我们的模型可以更准确地预测大型数据集上的缺失链接。
bilstm-cnn github
基于残差收缩网络模块及CNN-BiLSTM的调制识别方法 |