这篇教程FPN-从原理到模型的训练与测试写得很实用,希望能帮到您。
原文https://blog.csdn.net/gusui7202/article/details/101875703?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.channel_param
原理简介
-------------------------------
【FPN】
特征金字塔网络,是众多卷积神经网络结构中的一种。
【创新点】
特征的构建和对特征的应用呈现出一种金字塔状的多尺度方式。这里的多尺度有两个层次,一个是特征的多尺度:构建了不同分辨率的融合特征;另一个是多尺度是应用的多尺度,在多个不同尺度的特征上分别做分类和回归。
【动机】
1.针对深度网络中语义不能兼顾的问题,设计一种能够兼顾底层和高层特征的卷积神经网络结构
2.附带针对:小目标。
【有效性分析】
1.特征融合是一个被证明有效的,通过增加计算量来提高模型性能的方式,FPN提供的,是一种更充分的特征融合,因为每一种分辨率的特征,都被用于融合,而融合结果也不是局限于单一的一个特征,而是同样融合出多种分辨率的特征,并且融合的特征之间还有递进关系,更后面的特征融合将会用到前面的融合特征。在这么一个不同层之间构建了丰富的信息交互,保证了从头到尾有效信息的传播。
2.关于小目标的检测,是其主打卖点。有用的原因主要有三个,第一个是更充分的利用了底层特征,而小目标正是因为小,所以在底层的信息才是最多的,所以对于小目标的特征是被优化了的。第二,就是在不同尺度的特征上都做预测,本质就是加大了搜索粒度,因为每个尺度的Feature上都会产生anchor,那么三个尺度的特征上都做预测,本质上,anchor boxes会更多更充分更准确的包含到小目标,也就是能更好的将小目标检索出来。第三,是原因1和原因2的共同作用,特征优化了,搜索更细了,这才是效果直接提升的必要因素,也就是我能框出更多的框,并且小框的特征还更有效。
3.模型结构:这些其他博客都很多了,不必赘述。
4.关于FPN和Faster R-CNN等模型的关系。其实FPN不是一个单独的网络,其提出的是一种主干网络以及对应该主干网络的一种检测方式。也就相当于把Faster R-CNN中的Backbone从ResNet-101的连接结构变成FPN结构,然后将Faster R-CNN的RPN输入从原来的最后一个特征层变为多个特征层(不同尺度的融合特征),也可以理解为将RPN复制多次。所以大家看源代码的时候,就当成Faster R-CNN的一种改进看就可以了。其他部分都一样的。
-------------------------------
模型搭建
-------------------------------
1.环境搭建
ubuntu + python2 + tensorflow1.2 + cv2 + cuda8.0 (+ GeForce GTX 1080)
作者将自己的环境用Docker打包了一份,So,
You can also use docker environment, command:
docker pull yangxue2docker/tensorflow3_gpu_cv2_sshd:v1.0
2.下载源代码
git clone https:
3.跑一下Demo测试一下模型
1、解压基于res101训练好的demo模型:
文件在 FPN根目录/output/res101_trained_weights/(一个飞机检测的模型)
2、在测试图像文件夹里面丢一些包含目标(飞机)的图片。本身就有几张,故可不放。
文件夹为:FPN根目录/tools/inference_image
3、修改模型的绝对路径。因为内部的调用都需要基于一个路径,这里作者集成到配置文件cfgs.py中了。在里面直接改就行,然后其他的路径就都会根据这个来。
在这里面修改:FPN根目录/libs/configs/cfgs.py
-
-
ROOT_PATH = os.path.abspath(r'C:\Users\yangxue\Documents\GitHub\FPN_Tensorflow')
4、运行代码测试:
这里作者提供两种代码,一种是用于跑小图片的(作者所用数据集中的.jpg为小分辨率图像),一种是用于跑大图的,.tif结尾的是分辨率大的大图。
-
-
-
-
-
-
(注:大图小图都可以跑,大图就用最小边压缩了一下)
-
-
-
-
-
python demo.py --src_folder=.\demo_src --des_folder=.\demo_des
-
-
-
(注:这个demo只处理.tif结尾的大图,src_folder和des_folder后面修改为测试图片和保存测试结果的文件夹位置。)
一般就用第一个就行了。后面那个也就相当换了一种方式处理格式问题,然后还是用最小边缩小大图。
【测试结果】
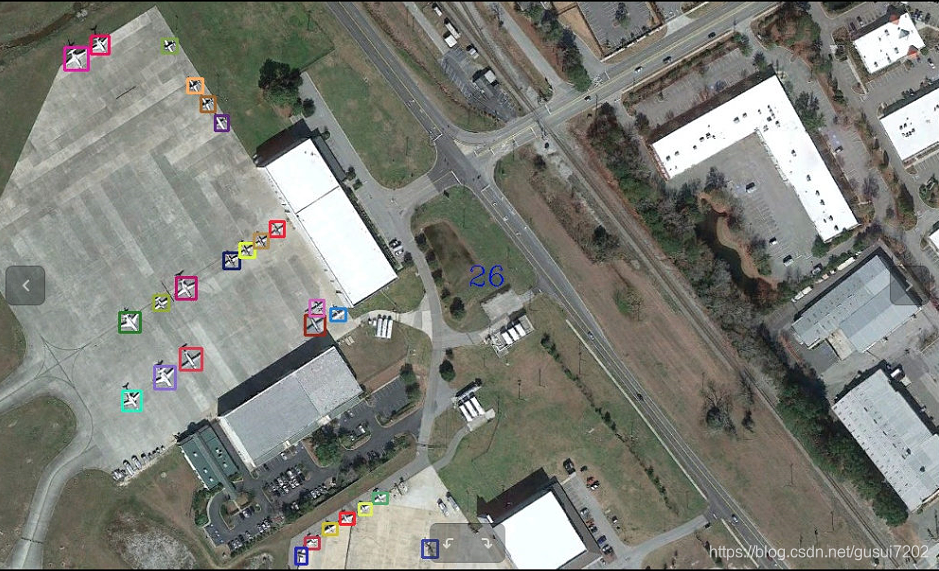
到此,模型搭建完成,测试通过。
-------------------------------
训练自己的数据
-------------------------------
1.数据准备
将自己的PASCAL_VOC数据集拆分为训练集、测试集合。适用/data/io/divide_data.py
具体的拆分比例,调节divide_data.py中的divide_rate = 0.8。
python /data/io/divide_data.py
在根目录下,将会生成两个文件夹:VOCdevkit_train 和 VOCdevkit_test

下一步,需要分别将训练和测试数据转换成 TFrecord 格式。该格式是TensorFlow的高效存储格式,连续的内存二进制存储能够有效的加快数据的读取和写入。而像原始文件夹那样每个数据独立存储。
转换的代码为 /data/io/convert_data_to_tfrecord.py
python convert_data_to_tfrecord.py --VOC_dir='***/VOCdevkit/VOCdevkit_train/' --save_name='train' --img_format='.jpg' --dataset='ship'
在使用的时候,训练和测试数据分别使用。.py后面的参数需要根据自己的路径和数据集进行修改。参数说明如下:
-
-
--VOC_dir='你的FPN路径/VOCdevkit/VOCdevkit_train/'
-
-
-
-
-
-
上面的参数前三个都Ok,第四个需要添加自己数据集的类别字典,所以你无法直接运行上面的代码。需要修改以下:
在/libs/label_name_dict/label_dict.py中添加自己的数据集标签类别。具体如下:
-
-
from __future__ import division, print_function, absolute_import
-
-
from libs.configs import cfgs
-
-
if cfgs.DATASET_NAME == 'ship':
-
-
-
-
-
-
-
别人我为什么需要自己数据集训练数据类别的字典- -
-
因为字典不同训练的模型后面的softmax层大小不一样。2类就2个。
-
4类的话softmax就有4个节点。这个需要训练师自己确认。
-
(而不是因为无法从你的dataset自动的统计你的类别名字及其数量。)
-
-
elif cfgs.DATASET_NAME == 'mydataset':#这个名字就是你数据集类别字典的名字了。
-
-
-
-
-
-
-
-
-
-
-
-
elif cfgs.DATASET_NAME == 'SSDD':
-
-
-
-
-
elif cfgs.DATASET_NAME == 'airplane':
-
-
-
-
-
elif cfgs.DATASET_NAME == 'nwpu':
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
然后就可以运行convert_data_to_tfrecord.py了。别忘了填上四个参数。
python convert_data_to_tfrecord.py --VOC_dir='***/VOCdevkit/VOCdevkit_train/' --save_name='train' --img_format='.jpg' --dataset='ship'
运行结果就是得到训练、测试数据的tfrecord格式数据,在 /data/tfrecords/ 里面。你可以自己检查一下。
2.参数设置
数据准备好了,那么训练就要调参和调一些路径啦。打开/libs/configs/cfgs.py,按我的注释来。
对应里面的model,应先下载好预训练模型,放在 /data/pretrained_weights/ 中。
预训练模型的下载地址:
Res101: http://download.tensorflow.org/models/resnet_v1_101_2016_08_28.tar.gz
Res50: http://download.tensorflow.org/models/resnet_v1_50_2016_08_28.tar.gz
-
-
from __future__ import division, print_function, absolute_import
-
-
-
-
-
-
-
-
ROOT_PATH = os.path.abspath(r'C:\Users\yangxue\Documents\GitHub\FPN_Tensorflow')
-
-
-
-
TEST_SAVE_PATH = ROOT_PATH + '/tools/test_result'
-
INFERENCE_IMAGE_PATH = ROOT_PATH + '/tools/inference_image'
-
INFERENCE_SAVE_PATH = ROOT_PATH + '/tools/inference_result'
-
-
NET_NAME = 'resnet_v1_101'
-
-
-
-
-
-
-
-
-
BASE_ANCHOR_SIZE_LIST = [15, 25, 40, 60, 80]
-
LEVEL = ['P2', 'P3', 'P4', 'P5', "P6"]
-
STRIDE = [4, 8, 16, 32, 64]
-
-
ANCHOR_RATIOS = [1, 0.5, 2, 1 / 3., 3., 1.5, 1 / 1.5]
-
SCALE_FACTORS = [10., 10., 5., 5.]
-
-
-
-
DATASET_NAME = 'mydataset'
-
-
-
WEIGHT_DECAY = {'resnet_v1_50': 0.0001, 'resnet_v1_101': 0.0001}
-
-
-
-
-
-
-
-
-
RPN_NMS_IOU_THRESHOLD = 0.5
-
-
RPN_IOU_POSITIVE_THRESHOLD = 0.5
-
RPN_IOU_NEGATIVE_THRESHOLD = 0.2
-
-
-
IS_FILTER_OUTSIDE_BOXES = True
-
-
-
-
-
-
-
-
FAST_RCNN_NMS_IOU_THRESHOLD = 0.2
-
FAST_RCNN_NMS_MAX_BOXES_PER_CLASS = 100
-
FINAL_SCORE_THRESHOLD = 0.5
-
FAST_RCNN_IOU_POSITIVE_THRESHOLD = 0.45
-
FAST_RCNN_MINIBATCH_SIZE = 256
-
FAST_RCNN_POSITIVE_RATE = 0.5
3.跑起来
在根目录下打开终端。运行以下:
python /tools/train.py
等着训练完成吧。
-------------------------------
测试自己的数据
-------------------------------
1.参数设置
测试实际上包括指标验证和保存测试结果。如果只是像将测试集跑一边然后将结果保存下来,就用/tools/test.py
如果是想验证,就用/tools/eval.py
在test.py或eval.py里面有对应的测试参数可以改,比如正样本阈值等。
2.验证测试
运行代码。
-
-
-
运行test.py的话你会在./tools/test_result里获得测试集的图片检测结果。
运行eval.py则得到 AP、Recall 和mAP。
以上。
------------------------
作者优化的FPN版本:https://github.com/DetectionTeamUCAS/FPN_Tensorflow
作者给出了一个优化版本。因为原来的版本在训练的过程中因为summary的可视化原因,会终止训练。
比如tensorboard显示proposals图像结果的时候,画了超出图像的框等。就会终止训练。如果不想换模型,把对应的地方注释掉就可以,一般大家可能也用不到tensorboard。另一个就是使用方面的优化。优化版的代码用eval.py就可以直接获取指标验证结果以及测试结果,只需要调节一个参数。
以上是我使用时发现的主要两点感受。
两个使用方法大同,不赘述。
SSD网络原理解析
FPN(Feature Pyramid Networks)网络原理解析 |