SSD网络是继YOLO之后的one-stage目标检测网络,是为了改善YOLO网络设置的anchor设计的太过于粗糙而提出的,其设计思想主要是多尺度多长宽比的密集锚点设计和特征金字塔,下面我将详细的解析SSD网络结构
SSD网络结构
精简版
详细版
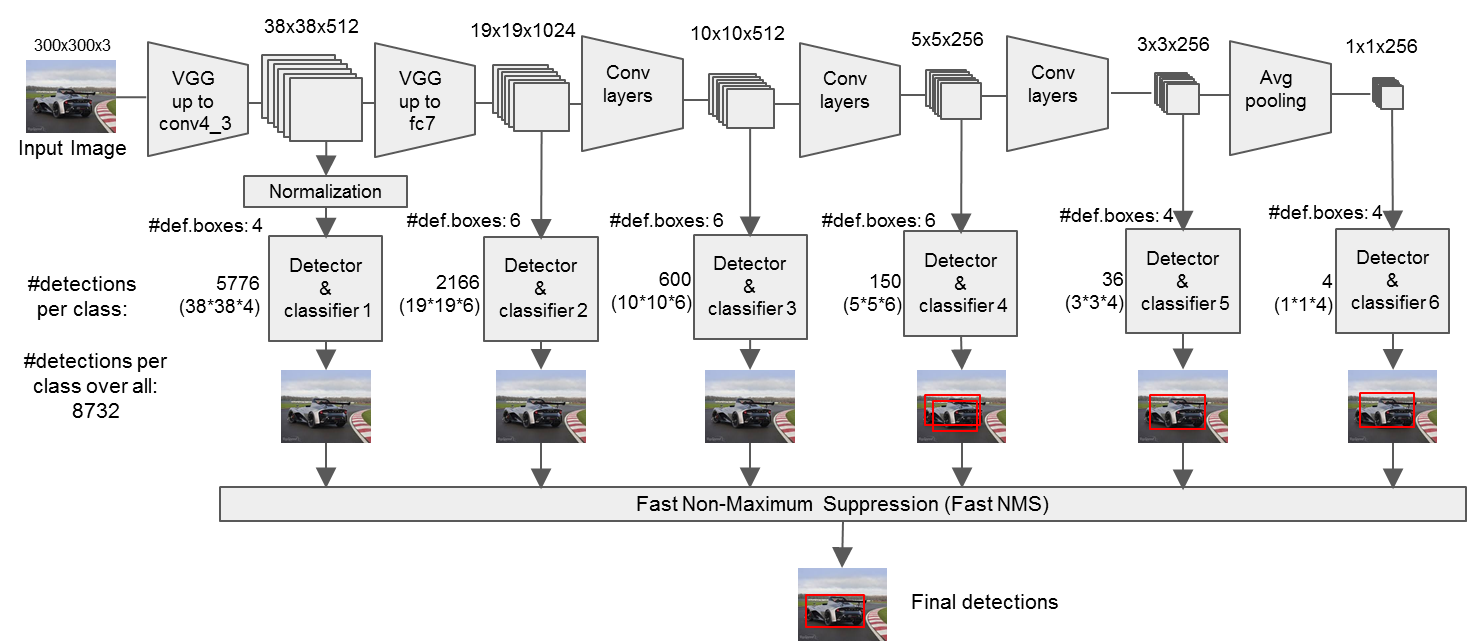
通过上面这个图,大家可以清楚的看到SSD的网络结构主要分为以下几个部分:
- VGG16 Base Layer
- Extra Feature Layer
- Detection Layer
- NMS
补充说明:在整个SSD网络中,其实还隐藏了两个重要的部分:
- Anchor
- MultiBoxLoss
VGG16 Base Layer
SSD网络以VGG16作为基础的特征提取层Base Layer,选取其中的Conv4_3作为第一个特征层用于目标检测,VGG网络大家都很熟悉我就不多说了,有不了解的小伙伴可以参考博客VGG网络解析
Extra Feature Layer
在VGG16 Base Layer的基础上,作者额外的添加了几个特征层用于目标检测,将VGG16中的FC7该成了卷积层Conv7,同时增加了Conv8、Conv9、Conv10、Conv11几个特征层。
说到Conv4_3、Conv7、Conv8、Conv9、Conv10、Conv11这几个特征层,小伙伴们就要注意了,这里是作者网络设计的第一个重要思想:特征金字塔,在多个尺度上进行目标检测以提高检测精度。
大家看上面这个图应该就可以理解特征金字塔在多尺度的检测原理了,它之所以能提高检测精度,主要有以下几个方面的原因:
- 特征层越高,具有的语义信息越丰富,不同特征层代表了不同级别的特征利用,检测结果必然比只在最后一层进行检测效果好
- 特征层从低到高,其感受野由小到大,不同特征层对检测不同尺寸的目标检测是有帮助的
Anchor
现在已经准备好了特征金字塔来进行目标检测,又不能像two-stage那样预先得到一些候选框,那么又该怎么样才能检测目标呢?anchor思想自然而然的就产生了,首先可以做的就是预先设定一些框proir box/default box,以他们为基本,通过位移和长宽比改变慢慢的向真实目标位置靠近;那么又该怎么样保证对整幅图像的每个地方都有一一的检测呢?解决办法就是设计大量的密集的proir box,下面具体说明SSD的proir box是怎么设计的
预备知识:proir box位置的表示形式是以中心点坐标和框的宽、高(cx,cy,w,h)来表示的,同时都转换成百分比的形式
proir box生成规则:
- SSD由6个特征层来检测目标,在不同特征层上,proir box的尺寸scale大小是不一样的,最低层的scale=0.2,最高层的scale=0.95,其他层的计算公式如下
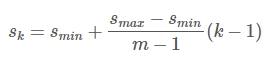
- 在某个特征层上其scale一定,那么会设置不同长宽比ratio=[1, 2, 3, 1/2, 1/3]的proir box,其长和宽的计算公式如下:
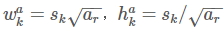
- 在ratio=1的时候,还会根据该特征层和下一个特征层计算一个特定scale的proir box(长宽比ratio=1),计算公式如下:
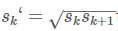
- 每个特征层的每个点都会以上述规则生成proir box,(cx,cy)由当前点的中心点来确定,由此每个特征层都生成大量密集的proir box,给个图大家体会一下
Detection Layer
好了,现在proir box都有了,那么就得想办法对这个proir box中目标的类别进行预测,同时还得预测proir box最终演变的框(该框最接近真实目标的框),所以Detection Layer要实现两个功能,类别预测和框预测(框的表示由(cx,cy,w,h)来表示)。
说明:实际上对于位置的预测并不是预测最终框(cx,cy,w,h),而是预测proir box到Ground Truth的映射关系offset,如下图所示,我们通过proir box学习到一种映射关系offset,得到预测框,使得预测框尽可能接近Ground Truth

proir box到Ground Truth的映射关系offset的表达式如下:

Detection Layer结构
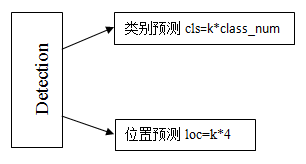
Detection Layer首先分成cls分支和loc分支,每个分支中包含6个(因为有6个特征层)卷积层conv,conv的输出尺寸和输入尺寸相同,cls分支的输出通道数为k*class_num,loc分支的输出通道数为k*4,k表示proir box个数。
NMS
特征层通过Detection Layer将得到8732个proir box的预测结果,可想而知很多proir box的预测结果是无用的,需要对这些预测结果进行筛选:
1.对于某个类别,将分类预测的<置信度阈值的框删除
2.将该类别筛选后的框按照置信度降序排序
3.对筛选后的框采用NMS:
1)计算置信度最高的框与后面所有框的iou,iou>阈值就删除
2)找到筛选后的框中除了当前框后面的另一个置信度最高的框,重复步骤1),以此不断遍历,直到结束
4.对除了背景类以外的所有类别执行步骤1、2、3
MultiBoxLoss
上面的5个部分按顺序完成了SSD网络的整个检测流程,但是预测之前需要进行训练啊!训练就需要损失函数,不同于分类网络,目标检测网络的损失函数包括类别损失和位置损失两个部分,其公式如下:
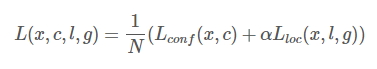
其中N是match到Ground Truth的proir box数量;而alpha参数用于调整confidence loss和location loss之间的比例,默认alpha=1。位置损失则是采用 Smooth L1 回归loss,类别损失是典型的softmax loss,损失函数看着很简单,但是实际计算过程包括Ground Truth和proir box匹配、负样本获取几个主要部分
匹配策略: 训练阶段建立真实标签和默认框对应关系,真实标签从默认框中选择。开始先匹配每个真实标签框与默认框最好的jaccard重叠,确保每个真实标签框有一个匹配的默认框,然后匹配与真实框jaccard重叠高于阈值0.5的默认框。这样就允许网络对多个重叠的默认框预测获得高置信度,而不是只选择最大重叠的一个。
Matching strategy:
上面得到的8732个目标框经过Jaccard Overlap筛选剩下几个了;其中不满足的框标记为负数,其余留下的标为正数框。紧随其后:
在训练时,groundtruth boxes 与 default boxes(就是prior boxes) 按照如下方式进行配对:
- 首先,寻找与每一个ground truth box有最大的jaccard overlap的default box,这样就能保证每一个groundtruth box与唯一的一个default box对应起来(所谓的jaccard overlap就是IoU,如下图)。
- SSD之后将剩余还没有配对的default box与任意一个groundtruth box尝试配对,只要两者之间的jaccard overlap大于阈值,就认为match(SSD 300 阈值为0.5)。
- 显然配对到GT的default box就是 候选正样本集,没有配对到GT的default box就是候选负样本集。

负样本获得(这是一个难例挖掘的过程)
在目标检测中我们会事先标记好ground_truth,接下来在图片中随机提取一系列sample,与ground_truth重叠率IoU超过一定阈值的(比如0.5),则认为它是positive sample,否则为negative sample,考虑到实际负样本数>>正样本数,我们为了避免network的预测值少数服从多数而向负样本靠拢,取正样本数:负样本数大约为1:3,显而易见,用来训练网络的负样本为提取的负样本的子集,那么,我们当然选择负样本中容易被分错类的困难负样本来进行网络训练。
困难负样本是指容易被网络预测为正样本的proposal,即假阳性(false positive),如roi里有二分之一个目标时,虽然它仍是负样本,却容易被判断为正样本,这块roi即为hard negative,训练hard negative对提升网络的分类性能具有极大帮助,因为它相当于一个错题集。
如何判断它为困难负样本呢?也很简单,我们先用初始样本集(即第一帧随机选择的正负样本)去训练网络,再用训练好的网络去预测负样本集中剩余的负样本,选择其中得分最高,即最容易被判断为正样本的负样本为困难样本,加入负样本集中,重新训练网络,循环往复,然后我们会发现:我们的网络的分类性能越来越强了。
在生成 prior boxes 之后,会产生很多个符合 ground truth box 的 positive boxes(候选正样本集),但同时,不符合 ground truth boxes 也很多,而且这个 negative boxes(候选负样本集),远多于 positive boxes。这会造成 negative boxes、positive boxes 之间的不均衡。训练时难以收敛。因此对default boxes以confidence loss由高到低排序,取最高的一些值,把将正负样本控制在3:1的范围。
将每一个GT上对应prior boxes的分类loss进行排序:
对于候选正样本集:选择loss最高的m个 prior box 与候选正样本集匹配 (box 索引同时存在于这两个集合里则匹配成功),匹配不成功则从候选正样本集中删除这个正样本(因为这个正样本loss太低,易被识别,已经很接近 ground truth box 了,不需要再训练);
对于候选负样本集:选择最高的m个 prior box 与候选负样本集匹配,匹配成功的则留下来作为最后的负样本,不成功剔除出这个候选负样本,因为他们loss不够大,易被识别为背景,训练起来没难度没提升空间。
举例:假设在这 8732 个 default box 里,经过 FindMatches 后得到候选正样本 P 个,候选负样本那就有 8732−P个。将 prior box 的 prediction loss 按照从大到小顺序排列后选择最高的 M个 prior box。如果这 P 个候选正样本里有 a 个 box 不在这 M 个 prior box 里(说明这a个box误差小,与真实框很接近),将这 a个 box 从候选正样本集中踢出去。如果这 8732−P个候选负样本集中有 b个在这 M 个 prior box(说明这b个box误差大,与真实框很远),则将这b个候选负样本作为正式负样本。即删除易识别的正样本,同时留下典型的负样本,组成1:3的prior boxes样本集合。SSD 算法中通过这种方式来保证 positives、negatives 的比例。